
🤕 OpenAI Can Not Be Happy About This
Does GPT-4.5 pass the vibe check?
In this issue:
OpenAI releases first “vibe” model
Microsoft bets on data quality and efficiency
When old benchmarks break, we need new ones

Accelerate your AI projects with Prolific. Claim $50 free credits and get quality human data in minutes from 200,000+ taskers.
No setup cost, no subscription, no delay—get started, top up your account to claim your free credit, and test Prolific for yourself now.
Use code: LLM-WATCH-50
1. GPT-4.5 System Card
Watching: GPT-4.5 (paper/my summary)
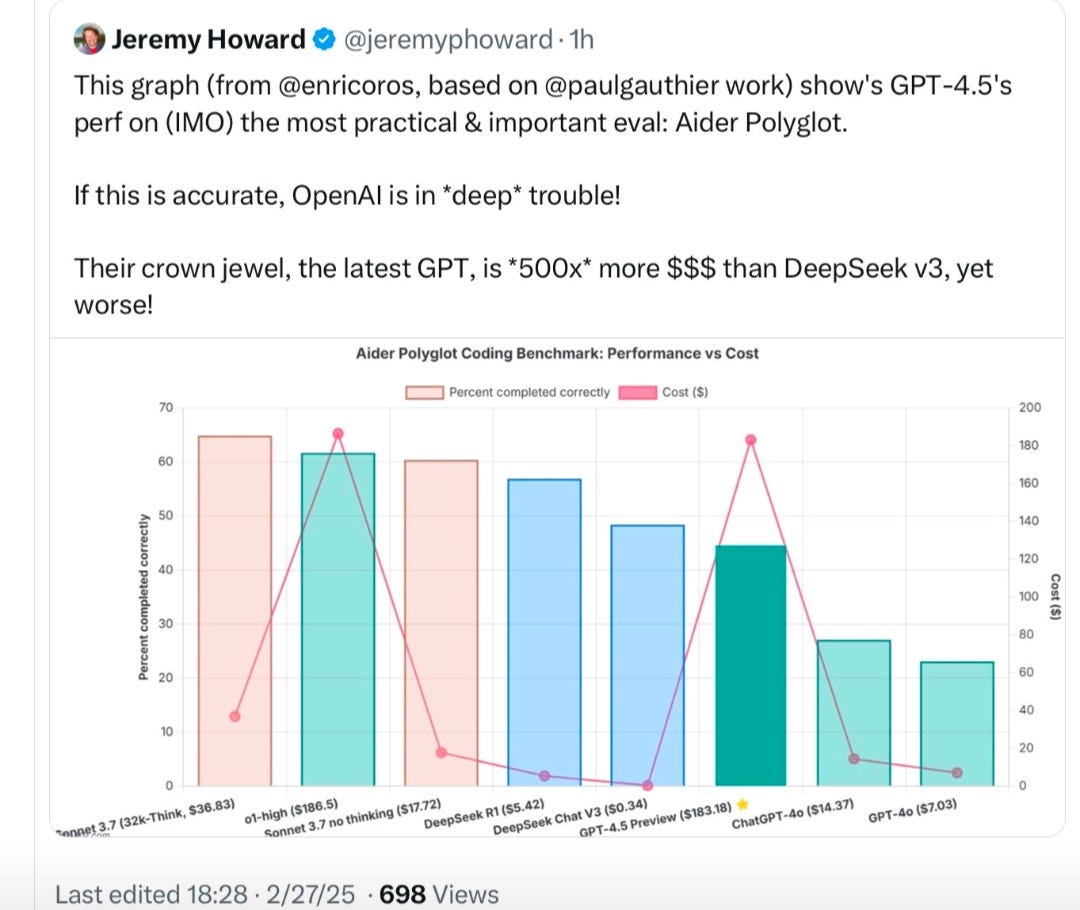
What problem does it solve? There’s a fundamental tension in AI development between two competing paradigms: scaled unsupervised learning (which builds extensive "world knowledge" but may lack reasoning depth) versus sophisticated reasoning approaches (which excel at problem-solving but might have less breadth of knowledge). Models like GPT-4.5 represent the former approach, while systems like o3 appear to represent the latter. This dichotomy has created a debate about which path will ultimately lead to more capable AI systems.
How does it solve the problem? OpenAI tries to address this by following a dual-track strategy where they simultaneously advance scaled unsupervised learning through GPT-4.5 while developing reasoning capabilities through other models (like o3). Rather than viewing these as competing approaches, they frame them as complementary paths that will eventually converge.
What are the key findings? While GPT-4.5 may currently be underwhelming relative to its cost for many practical applications, its importance lies not in immediate utility but in its role as a building block for future AI systems. The next breakthrough will come from unsupervised learning approaches converging with sophisticated reasoning capabilities, creating systems that can both leverage vast knowledge and perform complex step-by-step reasoning—a combination that would represent a transformative advance.
Why does it matter? This OpenAI release has a weird vibe to it and one can not help but think that their hand might have been forced by the big releases from their competition. According to them, GPT-4.5 isn’t supposed to be a breakthrough itself, but rather an enabler of one. Judging by how performant their existing reasoning model series turned out to be - which was based on GPT-4 - there’s a realistic chance that there’s some substance to their argument. So, if we believe their story, then GPT-4.5 would indeed play a very important rule. That’s a big if though.
Note: if you’re thinking about using GPT-4.5 for AI agents, I would recommend to check out the agent leaderboard from Galileo AI.
2. Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Watching: Phi-4-Mini (paper/my summary)

What problem does it solve? They address the challenge of creating compact yet highly capable language and multimodal models. As AI systems grow increasingly complex, there's a significant need for smaller models that can still perform sophisticated tasks without requiring massive computational resources. Specifically, the researchers sought to build models under 6B parameters that could match or exceed the performance of much larger models on complex reasoning, math, coding, and multimodal understanding tasks - a capability that would enable deployment in more resource-constrained environments.
How does it solve the problem? The Microsoft researchers developed two models: Phi-4-Mini (3.8B parameters) and Phi-4-Multimodal (5.6B parameters). For Phi-4-Mini, they trained on carefully curated high-quality web and synthetic data with emphasis on reasoning-rich content and code datasets. For Phi-4-Multimodal, they introduced a novel "mixture-of-LoRAs" technique that allows multiple inference modes combining various modalities without interference. This approach keeps the base language model entirely frozen while adding modality-specific capabilities through separate LoRA adapters and routers, enabling efficient handling of text, vision, and speech/audio inputs in various combinations without degrading performance in any single modality.
What are the key findings? They found that despite its compact size, Phi-4-Mini significantly outperforms recent open-source models of similar size and matches models twice its size on math and coding tasks. Phi-4-Multimodal ranks first on the OpenASR leaderboard despite having a speech/audio component of just 460M parameters. It demonstrates strong performance across vision-language tasks, often outperforming larger models, and supports combined modality scenarios like vision+language, vision+speech, and speech/audio inputs. An experimental reasoning-enhanced version of Phi-4-Mini achieves performance comparable to or surpassing specialized reasoning models with 7-8B parameters on complex mathematical reasoning tasks like AIME and MATH-500.
Why does it matter? Phi-4-Mini demonstrates that smaller, more efficient models can achieve performance levels previously thought to require much larger models when trained with high-quality data and specialized techniques. This has profound implications for democratizing access to advanced AI capabilities in resource-constrained environments like mobile devices and edge computing. The modular LoRA-based approach to multimodal integration provides a blueprint for efficiently extending models to new capabilities without retraining the entire system. This enables more practical, accessible, and resource-efficient AI applications without sacrificing performance quality.
3. BIG-Bench Extra Hard
Watching: BIG-Bench (paper/code)

What problem does it solve? Current LLM reasoning benchmarks have hit a ceiling, particularly BIG-Bench Hard (BBH), where state-of-the-art models now achieve over 90% accuracy. This saturation means these benchmarks can no longer effectively differentiate between the reasoning abilities of the latest LLMs. Additionally, most existing reasoning benchmarks disproportionately focus on mathematical and coding abilities, neglecting the broader spectrum of reasoning skills needed for real-world applications. BBH itself had several limitations: high random chance performance (due to many binary-choice questions), potential shortcuts for solving problems without proper reasoning, short input contexts (averaging only 700 characters), and relatively shallow reasoning depth.
How does it solve the problem? The authors created BIG-Bench Extra Hard (BBEH), replacing each of BBH's 23 tasks with significantly more challenging counterparts that test similar reasoning capabilities but require deeper thinking. They employed a semi-adversarial approach, iteratively increasing task difficulty until even frontier models struggled (below 70% accuracy). BBEH features substantially longer inputs (6x longer on average), requires more complex reasoning (outputs are 7x longer), and tests additional skills including many-hop reasoning, learning on the fly, identifying errors in reasoning chains, processing long contexts, finding needles in haystacks, and dealing with distractors. The benchmark also reduces the random chance baseline and eliminates shortcuts that previously allowed models to solve problems without proper reasoning.
What are the key findings? BBEH reveals substantial headroom for improvement in LLM reasoning capabilities. The best general-purpose model achieved only 9.8% harmonic mean accuracy, while the best reasoning-specialized model reached 44.8%. Reasoning-specialized models like o3-mini (high) showed their greatest advantages on formal problems involving counting, planning, arithmetic, and algorithms, but demonstrated limited progress on "softer" reasoning skills like commonsense, humor, sarcasm, and causation understanding. Similarly, larger models showed more improvement on tasks requiring many-hop reasoning or algorithm application, but less on tasks related to human-like understanding. The analysis also revealed that gains from reasoning specialization increased with both context length and reasoning complexity.
Why does it matter? Their work highlights crucial gaps in current LLM development. As these models are increasingly deployed in everyday applications, they need robust reasoning across diverse domains - not just in mathematics and formal logic. BBEH provides a more comprehensive assessment of general reasoning abilities by testing skills required for complex real-world scenarios. The results suggest a concerning imbalance: while significant progress has been made in formal reasoning capabilities, other equally important reasoning domains remain underdeveloped. This benchmark offers concrete guidance for future research, revealing where models struggle most and what capabilities need strengthening.
Papers of the Week:
Auto-Bench: An Automated Benchmark for Scientific Discovery in LLMs
Investigating the Adaptive Robustness with Knowledge Conflicts in LLM-based Multi-Agent Systems
IGDA: Interactive Graph Discovery through Large Language Model Agents
CodeSwift: Accelerating LLM Inference for Efficient Code Generation
From RAG to Memory: Non-Parametric Continual Learning for Large Language Models
Infinite Retrieval: Attention Enhanced LLMs in Long-Context Processing
General Reasoning Requires Learning to Reason from the Get-go