
Why Good AI Agents Look Less Like Chatbots and More Like Workshops
The Architecture of Trust

The marketing for AI agents still sells a dream: hand a digital colleague a goal, walk away, come back to finished work. But if you read what the people actually shipping these systems are saying, a different and more interesting picture emerges. The agents that work in production don’t look like a brilliant generalist set loose on your business. They look like a workshop of small, bounded tasks, with a human standing at the bench.
That gap between the dream and the practice is the most useful thing to understand about agents right now. It isn’t a sign the technology is failing. It’s a sign the field is growing up. And the pattern underneath it all is surprisingly simple to state: the path to capability runs through constraint.
The bottleneck isn’t intelligence
Start with the best data we have. In late 2025, researchers from UC Berkeley, Stanford, UIUC, and IBM published what they call the first large-scale study of AI agents running in production - 306 practitioners surveyed, 20 teams interviewed in depth, across 26 industries. Their headline finding was blunt: reliability is the top development challenge, driven by the difficulty of ensuring and evaluating whether an agent is actually correct.
That deserves a pause, because it contradicts the story we usually tell ourselves. We imagine the frontier of agent work as a race toward raw intelligence - bigger models, longer reasoning, more autonomy. But the teams shipping real systems aren’t mainly blocked by intelligence. They’re blocked by trust. They can’t reliably tell when their agent is right, wrong, or just confidently guessing, and that uncertainty is what stands between a demo and a deployment.
What they do about it is telling. Rather than unleashing autonomy, they fence it in. In that study, 68% of deployed agents take at most ten steps before a human checks in, 70% just prompt off-the-shelf models instead of fine-tuning, and 74% lean on human evaluation. The researchers put it plainly: teams deliberately trade capability for reliability. The agents winning in production aren’t the most autonomous ones. They’re the ones whose autonomy is most skillfully limited.
Context rot: the physics underneath
To see why constraint wins, you need a phenomenon that only recently got a name: context rot.
The belief that “more context means better answers” feels too obvious to question - it’s the whole pitch behind million-token context windows. But research from Chroma, which tested eighteen frontier models including GPT-4.1, Claude Opus 4, and Gemini 2.5, found the opposite. Output quality measurably degrades as input grows, even when the window is nowhere near full. And this wasn’t true of some models. It was true of every one they tested.
The mechanism is what makes it matter. It’s not just about the length. Performance falls off sharply in the presence of distractors - bits of information that look like the answer without being it. One distractor hurts. Add a few, and accuracy drops hard.
Now picture how an agent actually runs. Give it a vague, compound goal - “improve the report,” “handle the customer,” “grow engagement” - and it generates a sprawl of intermediate work: tool calls, half-formed plans, retrieved documents, reasoning about reasoning. All of it piles into the context window, and every irrelevant piece becomes a distractor that raises the failure rate of the next step. Coding agents are the clearest case, because they hit the trifecta: context that only accumulates, search results full of near-identical code, and tasks that run long enough for the rot to compound.
This can’t be solved by more reasoning effort alone. An agent doesn’t fail a sprawling task because it lacks ambition. It fails because the sprawl poisons the well it drinks from. This is why decomposition - breaking work into atomic, single-session chunks - isn’t a productivity tip layered on top, but a direct response to how these models actually process information.
The strange tolerance for slowness
If you assumed agents had to be fast to be useful, the production data says otherwise: 66% of deployed agents are allowed to take minutes or longer to respond. Only a third need sub-minute speed.
Why would anyone accept a five-minute answer? Because the thing you’re comparing against isn’t a chatbot - it’s a person. An agent that takes five minutes on a task that would cost a human an hour is still a tenfold speedup, especially when the task is someone’s secondary responsibility and the team is short-staffed.
That single statistic rearranges the design problem. Optimize an agent for snappy, real-time chat and you’ve implicitly accepted all the failure modes of context rot in exchange for speed the user may not even want. Accept that the agent runs in the background - slowly, deliberately - and you free yourself to do the things that actually buy reliability. You can decompose. You can verify. You can let the agent fail, retry, and check its own work before a human ever sees it. The trade is latency for correctness, and the market is overwhelmingly taking it. The exceptions prove the rule: voice agents, which have to keep pace with human conversation, are exactly where the same study found latency becomes the hard constraint.
Beyond the chatbot
All of this points at something about interface. The chatbot - one scrolling conversation - has been the default metaphor for AI since ChatGPT. For agentic work, it’s increasingly the wrong one.
A conversation is linear, accumulative, and never finished. It is, in other words, a context-rot machine by design: every turn piles onto the last, with no natural boundary, no checkpoint, no way to mark a unit of work done and clear the bench. The chat interface quietly optimizes for exactly the conditions that make agents unreliable.
The alternative changes the human’s job. In the chatbot model you’re a processor - answering the agent’s questions, feeding it the next prompt, stitching the output together by hand. In the task-system model you’re a strategist and a governor: you break a project into atomic, checkbox-style tasks, dispatch them, and review the results against a definition of done. You can watch this metaphor migrate into real products. When Anthropic shipped Cowork - Claude Code’s agentic guts brought to the desktop for knowledge work - it described the experience as “less like a back-and-forth and more like leaving messages for a coworker.” That’s a task system, not a chat. The checkbox, not the chat bubble, becomes the atomic unit.
Automation you earn
If one principle holds this together, it’s this: the right to automate a task should be earned, not assumed. You don’t hand an agent a workflow and hope. You do the task with it first, watch where it breaks, build a fix for those specific failure points, and only then let it run on its own.
This is where the coding world’s hard-won patterns turn out to transfer - not as tricks, but as instruments of context control. Three are worth knowing.
Sub-agents as context firewalls. Instead of one agent carrying a whole project in its head, you spin up a sub-agent for a discrete job - “research vendor pricing” - and have it return only a condensed result. Each runs in its own clean context window. The intermediate mess never reaches the orchestrator, so the rot never spreads. That’s the firewall.
Hooks as guardrails. In coding agents, hooks fire on events to surface errors or block dangerous commands. The distinction that matters, which Anthropic draws in its own docs, is between advice and enforcement: guidance the model can choose to follow versus a check that always runs. For knowledge work, a hook becomes the thing that triggers an evaluator to validate output against explicit “done” criteria before it reaches you - the system checking its own homework as policy, not goodwill.
Skills as packaged competence. A skill is a folder of instructions, scripts, and resources the agent can load on demand. It’s the earned-automation loop made durable: the residue of figuring out how to do a task well, saved so nobody - and no agent - has to rediscover it from scratch.
The architecture that ties it together
There’s one structural move that matters more than any other for systems touching money, records, or anything you can’t take back. It’s the decision to stop letting the model act, and let it only decide.
This cuts against the whole agent pitch - weren’t they supposed to do things? But the teams building auditable systems are converging on the opposite. The agent becomes a decision engine, not an executor. It examines a situation and emits a structured decision. A separate, deterministic layer of ordinary code decides whether and how to carry that decision out.
Make it concrete. A customer requests a refund. In the naive design, the agent reads the account and issues the refund itself. In the better one, a Decision Worker - an agent with read-only access - reads the order history and the policy and outputs a structured verdict: valid refund, $40, confidence 0.96. It cannot touch the billing system; that power simply isn’t wired to it. An Orchestrator - plain, testable code - receives that verdict and executes the payment, logging every step to an audit trail. The reason this matters is subtle but decisive: when an agent executes its own actions, the audit trail tends to live inside ephemeral prompts rather than in a system built to record it. Pull the action out of the prompt and into deterministic code, and you get auditability, retries, and least-privilege security back almost for free.
What makes this powerful rather than merely safe is confidence-based routing. The system runs autonomously by default - most refunds, most classifications flow straight through, no human involved. A person is summoned only when the agent’s own confidence drops below a set threshold. In practice those thresholds usually land between 0.70 and 0.85, calibrated against real labeled data rather than chosen by gut, often in tiers: above the high bar it proceeds, in the middle it acts but flags for review, below the floor it hands off live. And confidence is never the only trigger - mature systems escalate on financial limits, vulnerable customers, or legal exposure no matter how sure the model is. From August 2026, the EU AI Act turns that kind of human oversight from good practice into a legal requirement for high-stakes uses.
What you end up with is a system that’s autonomous where autonomy is safe, governed where it isn’t, and - crucially - knows the difference. The human leaves the loop on routine decisions and moves to the exception desk, handling only the cases the system itself flags as beyond its competence. That’s a more honest and more scalable division of labor than either full automation or constant babysitting.
Where the coding playbook stops working
It would be naive to say that because Cowork and Claude Code share an architecture, the coding playbook simply is the knowledge-work playbook. It’s not that clean, and the difference is worth naming.
Software engineering is unusually objective: the code compiles or it doesn’t, the tests pass or they fail. That’s why coding agents can verify themselves - a compiler is an oracle that never flatters you. Knowledge work has no compiler. A memo, a strategy, a piece of analysis turns on taste and judgment, which are stubbornly hard to package into a test. This doesn’t sink the analogy, but it reshapes it: the verification layer that runs automatically in code has to become human-led, or routed through evaluator agents that approximate judgment rather than compute it.
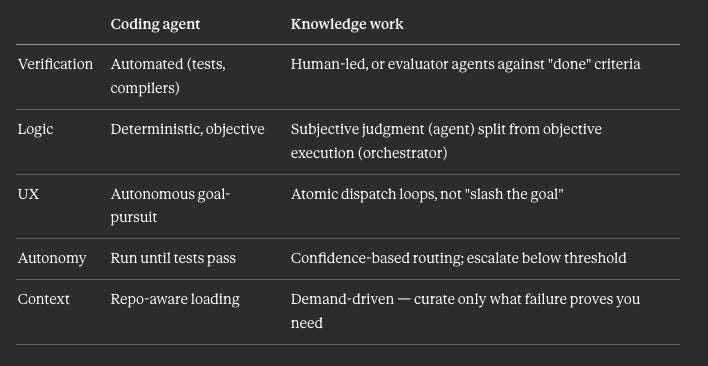
That last row points to the pattern that does transfer cleanly, and it’s my favorite of the bunch. Call it demand-driven context. Instead of documenting everything an agent might need up front - exhausting, and mostly wasted - you give it a task, let it fail, and then add only the minimum knowledge required for it to succeed next time. Failure writes the curriculum. The knowledge base grows in response to real gaps instead of imagined ones, which is its own kind of discipline.
What to actually do with this
Step back and the forces all point the same way. Decomposition, human governance, earned automation - none of these are temporary limitations waiting for a smarter model to dissolve them. Reliability is the binding constraint, context rot is the physics, and the willingness to trade speed for correctness is what makes careful, decomposed, verifiable work the winning move.
If you’re building or buying in this space, that suggests a few concrete habits. Stop evaluating agents on how autonomous they are and start evaluating them on how well they know their own limits. When a task touches anything irreversible, separate the deciding from the doing. Don’t write the giant knowledge base up front, let failures tell you what to write. And treat full automation as a destination you arrive at by earning it, one verified task at a time - not a switch you flip on day one.
Gartner has projected that a large share of agentic AI projects will be scrapped by 2027, citing cost, unclear value, and inflated expectations. I’d wager the casualties cluster around the old dream - the long-running generalist handed a vague goal and trusted to figure it out. The survivors will look more mundane and work far better: systems of small, high-leverage dispatch loops, governed by a human who treats constraint not as the enemy of capability but as its precondition.
That’s a less magical story than the one we were sold. I think it’s also the more durable one - though the honest caveat is that this field rewrites itself every few months, and the right move is to hold these patterns firmly and update them often.
Really nice article. Resonates deeply with conclusions I have on what works and what doesn't in the current state of AI. I like to codify rigid parts into bones and use AI as joints - fast, reliable, cheap.
Maybe, I would just tone down a bit, "chat is wrong" to "stop promising real-time" - a slight UX tone down on the rapidness.