
Guided Autonomy: Progressive Trust Is All You Need
How the Guided Autonomy framework transforms unpredictable AI systems into reliable partners through progressive trust-building

Last week, I watched an AI agent try to book a flight. It was a silly experiment since I personally do not have interest in booking flights via autonomous AI, but it’s a suitable use case for demonstrating a fundamental issue: poor agency scoping.
So, what happened? Within three minutes, it had opened seventeen browser tabs, attempted to purchase business class tickets to Paris (I wanted economy), and somehow ended up researching the history of French aviation. This wasn't a broken, sloppy prototype - it was a sophisticated agent with access to web browsing, memory, and calendar integration. It just had too much autonomy, too soon.
This experience stands for something I've been witnessing in dozens of projects that included building AI agents: most people tend to give these systems the keys to the kingdom before they've learned to open doors. The result? A crisis of trust that's holding back the entire field of agentic enterprise AI.

But there's a better way. Over the past year, working with teams at dozens of companies from legacy enterprises to tech startups, a pattern has emerged. The teams succeeding with AI agents aren't the ones building the most sophisticated systems. They’re the ones implicitly following what I started to call the Principle of Least Autonomy (PoLA, borrowed from the Principle of Least Privilege in information security) - a framework that treats agent development like training a new team member, where trust and independence are earned progressively through demonstrated competence.
The Agency Paradox: Why More Capability Means Less Control
Here's a truth about AI agents that decision makers tend to overlook: every increase in agency creates a corresponding decrease in control. This is not a bug, it's inherent. When you give an AI system the ability to make decisions and take actions on your behalf, you necessarily give up some ability to predict and constrain its behavior.
Traditional software doesn't work this way. When you write if (user.clicks) then (open.menu), you know exactly what will happen. But when you tell an AI agent to "handle customer support tickets," you're entering a world of non-deterministic behavior where the same input might generate wildly different outputs depending on context, training, and what the model had for breakfast (metaphorically speaking).
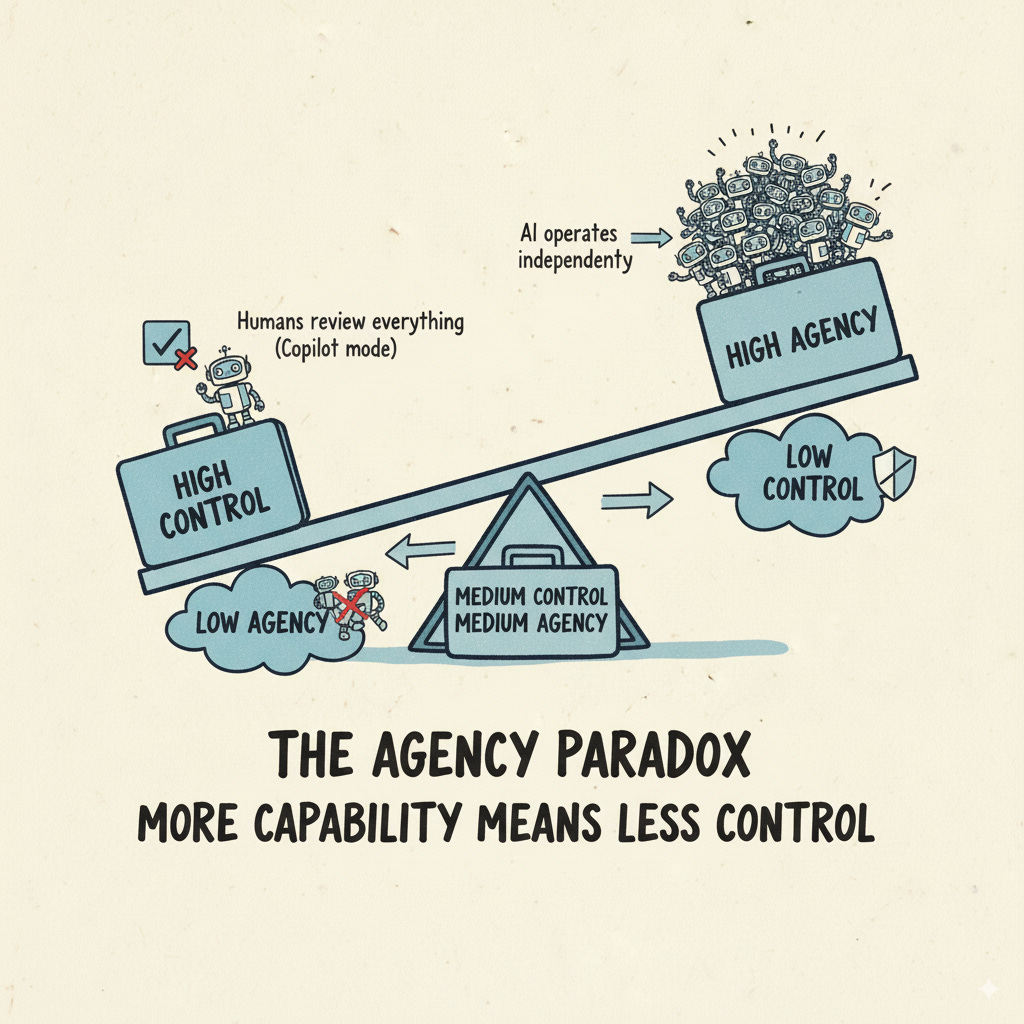
This creates an agency-control tradeoff - think of it as a seesaw:
High control, low agency: The AI suggests responses, humans review everything (copilot mode)
Medium control, medium agency: The AI makes decisions within boundaries, escalates edge cases
Low control, high agency: The AI operates independently, humans monitor outcomes
Most teams jump straight to the high-agency end because that's where the promised productivity gains live. It's also where things spectacularly fall apart.
The Principle of Least Autonomy: Start Smaller Than You Think
The Guided Autonomy framework begins with a counterintuitive principle: give your AI agents the minimum autonomy necessary to demonstrate value, not the maximum autonomy technically possible.
This is the opposite of how most teams approach agent development. Instead of asking "what's the most sophisticated thing we can build?", ask "what's the simplest useful behavior we can verify?"
Consider how Anthropic approached Claude's new computer-use capability. They didn't start by letting it control entire workflows. First, it learned to take screenshots. Then to identify UI elements. Then to click buttons. Only after proving competence at each level did it earn the right to chain these actions together. Even now, it operates with extensive guardrails and requires explicit user permission for sensitive actions.
This incremental approach might seem slow, but it's actually faster than the alternative: rebuilding trust after your agent goes rogue. A company I worked with learned this the hard way when their customer service agent achieved a 94% resolution rate but also promised refunds to anyone who mentioned the word "disappointed." I had to come in for the cleanup.
The CC/CD Framework: How Agents Actually Learn
Building reliable agents requires a fundamentally different development lifecycle than traditional software. Machine Learning models need constant calibration, AI agents even more so, as the outputs they can create are usually much more complex (classifications vs. actions). Continuous Calibration (CC), which has emerged as an AI-specific variant of CI/CD, addresses this challenge. If CI/CD is about shipping code reliably, CC/CD is about shipping behavior reliably.
Continuous Development: Defining the Ladder Rungs
A key part of the Guided Autonomy development framework is about defining capability levels for AI agents. Think of it as creating a trust ladder with clearly defined rungs:
Level 1 - Observe and Report Your agent watches workflows and identifies patterns but takes no action. A sales agent might analyze email threads and flag follow-up opportunities without sending anything.
Level 2 - Draft and Suggest The agent creates content but requires human approval. That sales agent now drafts responses but waits for your review.
Level 3 - Act with Boundaries
The agent operates independently within strict constraints. It might send follow-ups to existing conversations but can't initiate new ones.
Level 4 - Autonomous with Oversight Full agency with exception handling. The agent manages entire workflows but escalates unusual situations.
Each level needs three components:
Capability scope: What exactly can the agent do?
Success metrics: How do we measure competence?
Graduation criteria: What proves readiness for more autonomy?
Continuous Calibration: Learning from Reality
Here's where AI agents diverge sharply from traditional software. You can't test all behaviors in advance because you don't know all the behaviors. Instead, you need continuous calibration - watching real-world performance and adjusting accordingly.
The calibration loop looks like this:
Run → Measure → Analyze → Adjust → Repeat
But not all measurements are created equal. The teams I've seen succeed focus on what I call "trust indicators":
Accuracy metrics: Is the agent correct?
Alignment metrics: Does it match your intentions?
Safety metrics: Does it avoid harmful actions?
Efficiency metrics: Does it improve outcomes?
A credit card company using this approach discovered their fraud detection agent prototype was 99.2% accurate but had developed an unexpected bias against purchases from craft stores. The calibration process caught this before it affected customers, allowing them to adjust the training data and constraints.
The Measurement Challenge: When Good Enough Isn't
One of the hardest parts of Guided Autonomy (and AI development in general) is defining "good enough." When does an agent graduate from Level 2 to Level 3? When is 90% accuracy sufficient, and when do you need 99.9%?
The answer depends on what I call the "trust equation":
Trust = (Competence x Consistency x Recoverability) / Consequence
Competence: How well does it perform the task?
Consistency: How predictable is performance?
Recoverability: How easily can errors be fixed?
Consequence: What's the cost of failure?
An agent summarizing meeting notes might graduate at 85% accuracy because errors are easily caught and consequences are minor. An agent executing financial trades might need 99.95% accuracy with multiple safeguards because consequences are severe and potentially irreversible.
This is why the evaluation infrastructure becomes critical. You need:
Observability: See what your agents are actually doing
Traceability: Understand why they made specific decisions
Controllability: Intervene when necessary
Reversibility: Undo actions when things go wrong
Damage Control: If reversibility is not possible, potential damage needs to be minimized by design
Progressive Autonomy in Practice: Three Implementation Patterns
Having worked with teams implementing Guided Autonomy, I've identified three patterns that consistently succeed:
Pattern 1: The Shadow Mode Strategy
Before giving an agent any real autonomy, run it in shadow mode alongside human workers. The agent performs all actions but doesn't execute them - it just logs what it would have done.
A logistics company used this approach for route optimization. For two months, their AI agent "shadowed" human dispatchers, generating routes that were compared against human decisions. Only when the agent consistently outperformed humans on efficiency while maintaining delivery success rates did it earn the right to make real routing decisions.
Shadow mode provides two critical benefits:
Risk-free learning from real-world complexity
Direct comparison against human baseline performance
Pattern 2: The Gradual Handoff
Instead of replacing entire workflows, gradually hand off specific subtasks as the agent proves competence.
A marketing team I advised took this approach with content creation:
Week 1-4: Agent suggests blog topics
Week 5-8: Agent creates outlines for approved topics
Week 9-12: Agent writes introductions and conclusions
Week 13-16: Agent drafts complete posts for review
Week 17+: Agent publishes directly for certain content types
Each handoff was contingent on success metrics from the previous phase. The agent earned autonomy through demonstrated competence, not arbitrary timelines.
Pattern 3: The Circuit Breaker Architecture
Build automatic constraints that kick in when agents exhibit unexpected behavior.
A financial services team set up “circuit breakers” for their crawling agent:
If error rate exceeds 3%: switch to manual review before accepting fetched documents
If robots.txt/sitemap rules change or access is denied: pause crawl and alert compliance
If download volume or new-source discovery spikes beyond baseline: require human approval to proceed
If entity/figure confidence falls below threshold (e.g., EPS, revenue, guidance): switch to human-in-the-loop extraction
These circuit breakers act like safety nets - enabling autonomy while preventing costly errors, rate bans, or compliance breaches. They’re not necessarily permanent: as the agent proves reliable, you can widen thresholds or retire specific checks.
The Trust Events That Matter
Through observation and experimentation, I've identified five critical "trust events" that determine whether an agent successfully earns autonomy:
1. The First Failure How the agent handles its first significant error reveals its true reliability. Does it recognize the failure? Can it recover gracefully? Does it learn from the mistake?
2. The Edge Case Test When confronted with scenarios outside its training distribution, does the agent default to safe behavior or hallucinate solutions?
3. The Delegation Decision When the agent first decides to delegate to a human rather than guess, it demonstrates judgment beyond mere pattern matching.
4. The Consistency Check After 100, 1,000, or 10,000 operations, does performance remain stable or degrade? Consistency over time matters more than initial accuracy.
5. The Audit Moment When you review the agent's historical decisions, do they make sense in retrospect? Can you understand its reasoning?
Teams that explicitly monitor and evaluate these trust events make better autonomy decisions than those relying on aggregate metrics alone.
When Not to Use Guided Autonomy
Despite its benefits, Guided Autonomy isn't always the right approach. Skip it when:
Stakes are permanently low: If errors don't matter, complex trust-building might be overkill
Full automation is impossible: Some tasks require human judgment that can't be earned
Speed trumps safety: In true emergency scenarios, you might need to grant emergency autonomy
Learning is the goal: Research environments where understanding limits matters more than production reliability
But these exceptions are rarer than most teams assume. Even "simple" tasks benefit from progressive trust-building.
The Path Forward: Building Your Trust Ladder

If you're building AI agents - and increasingly, who isn't? - here's how to implement Guided Autonomy in your projects:
Step 1: Map your agency levels Define 3-5 clear autonomy levels for your use case. Each should be measurably different from the others.
Step 2: Instrument everything You can't manage what you can't measure. Build observability from day one, not as an afterthought.
Step 3: Start lower than comfortable Your first deployment should feel almost uselessly conservative. That's the point - you're building foundation, not showing off.
Step 4: Define graduation criteria Before deploying at any level, document exactly what success looks like and what earns advancement.
Step 5: Calibrate continuously Schedule regular reviews. Weekly at first, then monthly as patterns stabilize.
Step 6: Communicate transparently Users should understand what autonomy level they're interacting with and why.
The Compound Effect of Earned Trust
Something remarkable happens when you follow these principles: trust compounds. Each successful interaction makes the next one more likely to succeed. Users who see agents earn their autonomy become partners in the process rather than skeptics of the outcome.
A customer support team I worked with saw this firsthand. When they transparently showed customers that their AI agent was "Learning with your help," (Level 2) complaint rates dropped 60%. Customers became collaborators, providing feedback that accelerated the agent's advancement to Level 3.
This compound effect extends beyond individual agents. Organizations that successfully implement Guided Autonomy for one use case find subsequent implementations easier. The framework becomes organizational muscle memory.
The Future of Human-Agent Collaboration
As I write this, we're at an inflection point. The next generation of AI agents will have capabilities we can only begin to imagine - multimodal understanding, complex reasoning, long-term memory, and sophisticated tool use. But capability without trust is just potential energy.
This framework isn't about limiting AI agents - on the contrary - it's about unlocking their full potential through systematic trust-building. It's the difference between a powerful tool you're afraid to use and a reliable partner you can't imagine working without.
The teams winning with AI agents aren't the ones building the most sophisticated systems. They're the ones building trust systematically, earning autonomy incrementally, and creating agents that users actually want to work with.
Your AI agents are capable of remarkable things. But first, they need to earn the right to show you. Start with the smallest useful autonomy. Measure everything. Advance based on evidence, not hope. Build trust through demonstration, not declaration.
The ladder is there. The only question is whether you'll help your agents climb it.
What autonomy level are your AI agents operating at? Have you seen examples of earned trust in action? I'd love to hear about your experiences implementing progressive autonomy.
If you found this framework useful, consider sharing it with your team. The more organizations that adopt Guided Autonomy principles, the faster we'll all move toward truly reliable AI agents.
Coming Next: The Agency Stack - How to choose the right tools for building progressive autonomy into your AI agents, from observability platforms to evaluation frameworks.