
Watch#9: A CPU Is All You Need
Is ChatGPT good for search?

Foreword:
I changes the format of today’s spotlights a little bit. I realized that my “what’s next?”-sections tend to repeat itself (or rather, that it’s getting harder and harder for me to 𝘯𝘰𝘵 repeat myself).
The next steps for most papers are very similar: continue to expand the scope in the direction of the paper, do more experiments, evaluate as thoroughly as possible and so on. This is why I changed the third paragraph to “key results” on two of the three spotlights. Let me know which version you prefer in the poll at the bottom.
Have a great day all,
Pascal
Want to support me going professional as a content creator? Pledge now for future additional content. Your pledge will help me plan ahead and improve my content.
In this issue:
Unifying Vision and Language
Supercharging LLM inference on CPUs
ChatGPT for Search
1. MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning
Watching: MiniGPT-v2 (paper/code)
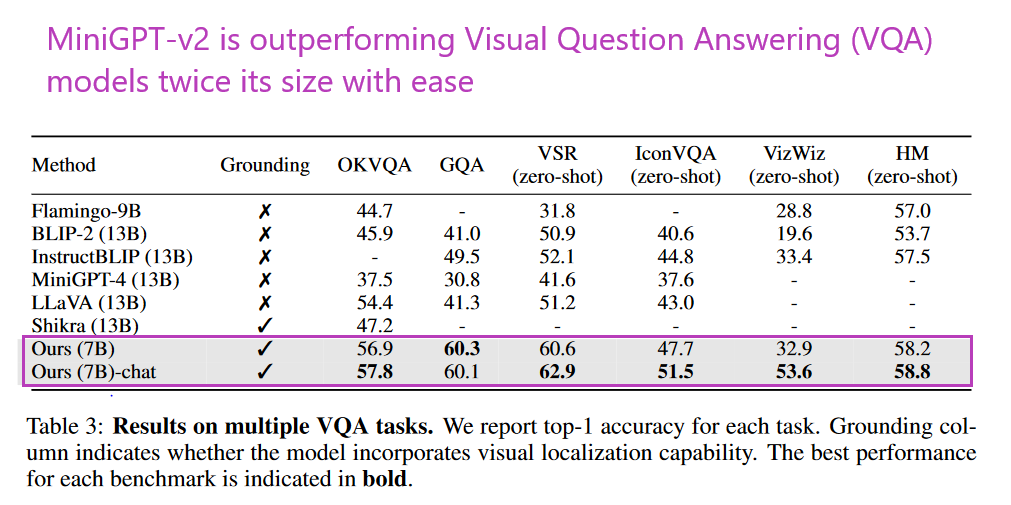
What problem does it solve? Existing vision-language models are typically trained for specific tasks, such as image description or visual question answering. This means that users need to train a different model for each task, which can be time-consuming and expensive. MiniGPT-v2 aims to solve this problem by providing a unified interface for various vision-language tasks.
How does it solve the problem? MiniGPT-v2 is a model that can be treated as a unified interface for better handling various vision-language tasks. It uses unique identifiers for different tasks when training the model. These identifiers enable the model to better distinguish each task instruction effortlessly and also improve the model learning efficiency for each task.
What’s next? MiniGPT-v2 was evaluated on many visual question-answering and visual grounding benchmarks and achieved strong performance compared to other vision-language generalist models. The researchers plan to explore other vision-language tasks in the future, such as image captioning and video summarization.
2. Efficient LLM Inference on CPUs
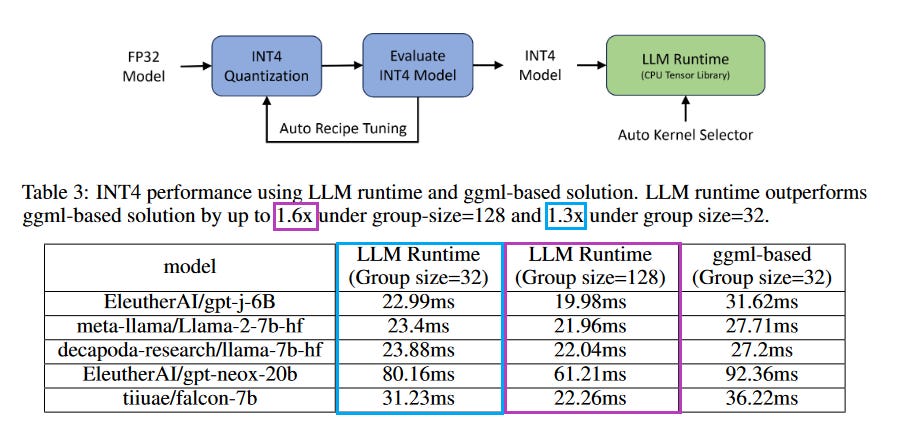
What problem does it solve? Large language models (LLMs) are typically very large and computationally expensive to deploy. This makes it difficult to use them in real-world applications, where resources may be limited. INT4 weight-only quantization is a technique that can be used to reduce the size and computational cost of LLMs without sacrificing too much accuracy.
How does it solve the problem? INT4 weight-only quantization works by converting the weights of an LLM to 4-bit integers. This can reduce the size of the model by up to 8x, and the computational cost by up to 4x. The authors of the paper propose an automatic INT4 weight-only quantization flow and design a special LLM runtime with highly-optimized kernels to accelerate LLM inference on CPUs.
Key results:
INT4 weight-only quantization can achieve near-parity accuracy with FP32 models, with a relative loss of less than 1%.
LLM runtime, the authors' proposed LLM runtime with highly-optimized kernels, outperforms the popular open-source ggml-based implementation by up to 1.6x.
3. Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents
Watching: LLMs 4 Search (paper)
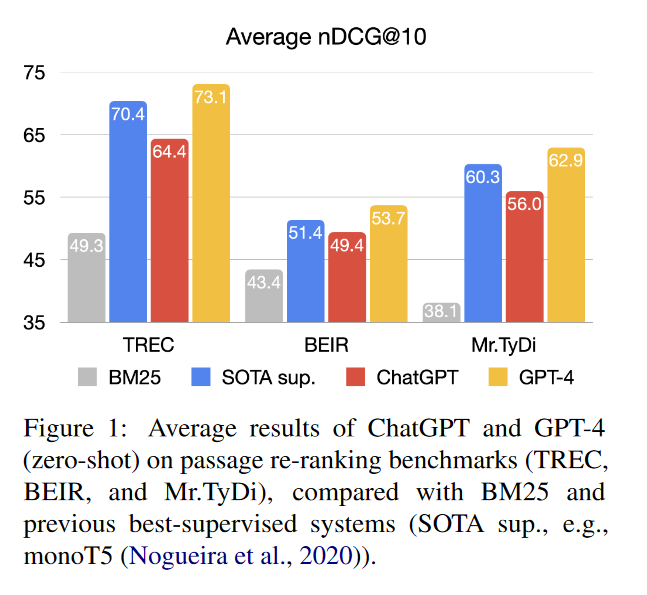
What problem does it solve? Traditional Information Retrieval (IR) systems rely on supervised learning methods to rank documents. However, these methods require large amounts of labeled data, which can be expensive and time-consuming to collect. Large Language Models (LLMs) offer a potential solution to this problem. LLMs can be trained on massive amounts of unlabeled data, and they have been shown to be capable of performing a variety of language-related tasks, including IR.
How does it solve the problem? The authors propose a new approach to IR that leverages the generative capabilities of LLMs. They show that LLMs can be instructed to rank documents by providing them with a set of training examples that include both the query and the relevant documents. The LLM then learns to generate a ranking score for each document, which can be used to determine the order in which the documents are presented to the user.
Key results:
ChatGPT and GPT-4 can be effectively used for passage re-ranking, without the need for any labeled data.
GPT-4 outperforms the state-of-the-art supervised and unsupervised passage re-ranking methods on both TREC and BEIR datasets.
ChatGPT also achieves impressive results on the BEIR dataset, surpassing the majority of supervised baselines.
Papers of the Week:
WebArena: A Realistic Web Environment for Building Autonomous Agents
Can large language models replace humans in the systematic review process?
AMSP: Super-Scaling LLM Training via Advanced Model States Partitioning
How to Build Low-cost Networks for Large Language Models (without Sacrificing Performance)?