
🤗 The Very First Diffusion Reasoning Model
Learn about d1, o3, o4-mini and NoThinking
Welcome, Watcher! This time around, we're diving into three AI highlights that push the boundaries of how AI models reason, learn, and interact with tools.
First, d1 tackles the challenge of enhancing reasoning in diffusion-based LLMs, a less explored area compared to standard models. By developing a novel reinforcement learning technique tailored for diffusion it demonstrates that these models can indeed achieve significant reasoning improvements, expanding the toolkit for AI reasoning.
Next, NoThinking questions the necessity of explicit 'thinking' steps in LLMs for complex reasoning It shows that bypassing this computationally expensive process can yield surprisingly effective results, especially with parallel generation, paving the way for much faster and more efficient reasoning systems without sacrificing accuracy.
Finally, OpenAI's o3 and o4-mini bridge the gap between deep reasoning and practical tool use. These models are trained not just to use tools, but to reason about when and how to deploy them, creating more versatile and agentic AI assistants capable of tackling complex, multi-step problems in real-world scenarios.
The underlying key trends: adapting powerful techniques like reinforcement learning to new architectures, finding more efficient paths to high-quality reasoning, and integrating reasoning with practical action and tool use. Whether scaling reasoning to different model types, challenging assumptions about generation processes, or building more autonomous agents, the push is towards more capable and practical AI.
Don’t forget to subscribe to never miss an update again.
Courtesy of NotebookLM
1. d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning

What problem does it solve? While autoregressive large language models (LLMs) have shown impressive reasoning capabilities enhanced through reinforcement learning, diffusion-based LLMs (dLLMs) have been overlooked in this area. Despite dLLMs demonstrating competitive language modeling performance through their non-autoregressive, coarse-to-fine generation approach, it remains unclear whether they can leverage similar reasoning advancements. The key challenge is that existing reinforcement learning techniques for improving reasoning were designed specifically for autoregressive models and cannot be directly applied to diffusion models due to fundamental differences in how they generate text and compute probabilities.
How does it solve the problem? "d1" is a two-stage framework that adapts pre-trained masked dLLMs into stronger reasoning models. First, they apply supervised fine-tuning (SFT) on high-quality reasoning traces to instill basic reasoning skills. Then, they developed "diffu-GRPO," a novel policy gradient method specifically designed for masked dLLMs that overcomes the technical challenge of estimating log-probabilities in non-autoregressive models through an efficient one-step estimation approach. They also introduced random prompt masking during training, which acts as regularization and allows more gradient updates per batch, reducing the computational cost of reinforcement learning.
What are the key findings? The researchers demonstrated that their d1 framework consistently improves reasoning performance across multiple mathematical and logical tasks when applied to LLaDA-8B-Instruct (a state-of-the-art dLLM). The combined SFT+diffu-GRPO approach outperformed both individual methods, with particularly impressive gains on specialized logical reasoning tasks like Countdown (26.2% improvement) and Sudoku (10.0% improvement). Qualitatively, models trained with their approach exhibited "aha moments" with self-correction and backtracking behaviors, especially with longer generation sequences. Their proposed random masking technique also significantly improved training efficiency, allowing the model to achieve better performance with fewer online generations.
Why does it matter? Their results are demonstrating that diffusion models can benefit from similar reasoning enhancements as their autoregressive counterparts. This expands the toolkit for developing more capable AI reasoning systems across different model architectures. The efficient training techniques developed could make advanced reasoning capabilities more accessible in dLLMs, which offer potential advantages in parallel processing and bidirectional context utilization. As we continue to explore alternatives to purely autoregressive architectures, understanding how to scale reasoning abilities across different model paradigms becomes increasingly valuable for advancing the field of AI reasoning.
2. Reasoning Models Can Be Effective Without Thinking
Watching: NoThinking (paper)
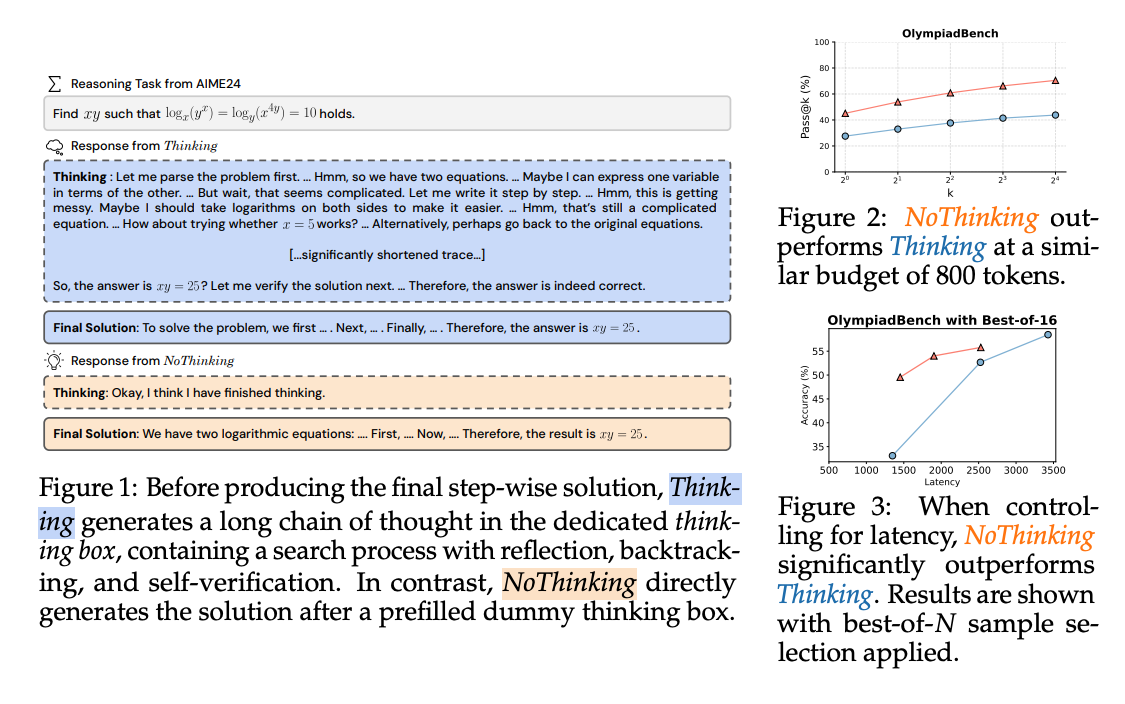
What problem does it solve? The latest generation of Large Language Models (LLMs) like DeepSeek-R1 and OpenAI's o1 have significantly improved their reasoning capabilities through a specific architecture: they first generate a lengthy "Thinking" process (where they explore multiple paths, reflect, and backtrack) before producing a "Final Solution." This two-step approach has become the dominant paradigm in reasoning-focused LLMs, but it comes at a substantial cost - generating these long thinking chains requires significantly more tokens, which increases both computational costs and response latency. The researchers question whether this explicit thinking process is actually necessary for achieving high-quality reasoning, or if it might be possible to bypass this step without sacrificing performance.
How does it solve the problem? The researchers developed a remarkably simple approach called "NoThinking" that bypasses the explicit thinking process. Using the state-of-the-art DeepSeek-R1-Distill-Qwen model, they simply prefilled the "thinking box" with a dummy statement ("Okay, I think I have finished thinking") and had the model immediately generate the final solution. They evaluated this approach across diverse reasoning benchmarks including mathematical problem-solving (AIME, AMC, OlympiadBench), coding (LiveCodeBench), and formal theorem proving (MiniF2F, ProofNet). They compared "NoThinking" with standard "Thinking" approaches in multiple scenarios, controlling for token usage and examining performance across different pass@k metrics (which measure whether at least one correct answer appears when sampling k different solutions).
What are the key findings? NoThinking was surprisingly effective despite eliminating the explicit thinking process. When controlling for token budget, NoThinking consistently outperformed Thinking across diverse reasoning tasks, especially in low-budget settings (e.g., scoring 51.3 vs. 28.9 on AMC 23 with only 700 tokens). Most notably, NoThinking's performance advantage grew as the pass@k value increased - meaning when sampling multiple solutions, NoThinking became even more competitive. Building on this observation, the authors showed that a parallel scaling approach (generating multiple NoThinking outputs independently and selecting the best one) was highly effective. For tasks with perfect verifiers (like theorem proving), this approach achieved comparable or better accuracy than Thinking while reducing latency by 7× and using 4× fewer tokens. Even for tasks without perfect verifiers, NoThinking with parallel scaling offered up to 9× lower latency with similar or better accuracy.
Why does it matter? It’s challenging a fundamental assumption about how reasoning in LLMs should work. While most research has focused on making the "thinking" process more effective through specialized training techniques, this research suggests a simpler, more efficient approach may be possible. The practical implications are significant: it could enable much faster and more cost-effective reasoning systems that use fewer tokens while maintaining accuracy. Rather than focusing on lengthy sequential reasoning, model providers might achieve better performance by generating multiple shorter solutions in parallel and selecting the best one. This approach is particularly valuable for real-world applications where response time and computational efficiency matter. Additionally, this work establishes an important baseline for future research on efficient reasoning in low-budget or low-latency settings, which are critical constraints in many practical LLM deployments.
3. Introducing OpenAI o3 and o4-mini
Watching: o3 & o4-mini (blog)
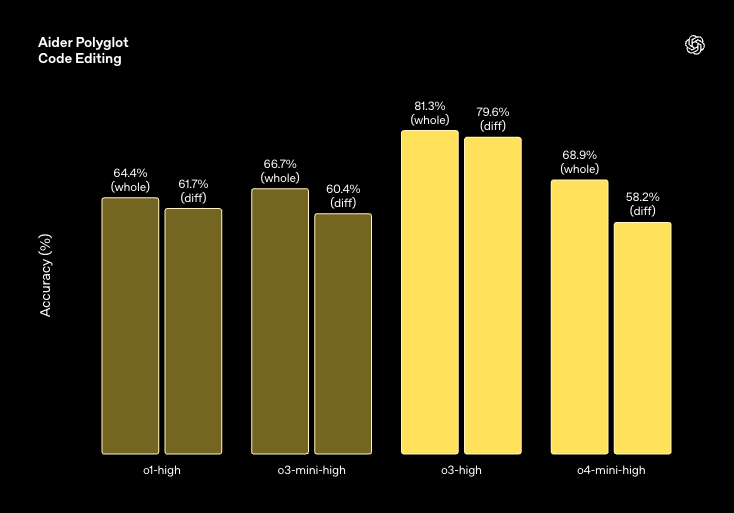
What problem does it solve? OpenAI's latest release addresses a fundamental challenge in large language models: how to enhance reasoning capabilities while maintaining usability. While previous models excelled at either conversational fluency or deep problem-solving, they often struggled to combine these strengths. The o-series models were specifically designed to "think for longer before responding," but earlier versions had limited tool access. This batch of models aims to bridge that gap by creating models that can reason deeply about when and how to use tools, enabling them to solve complex multi-faceted problems that require various forms of analysis and reasoning.
How does it solve the problem? o3 and o4-mini were developed through continued scaling of reinforcement learning and training models to agentically use tools. Beyond simply teaching models how to use tools, they specifically trained them to reason about when to deploy them based on desired outcomes. This approach allows the models to integrate multiple capabilities - web searching, Python coding, image analysis and generation, and more - while maintaining their reasoning strengths. The models can chain together multiple tool calls and pivot based on newly discovered information. Additionally, they enhanced visual capabilities, allowing the models to "think with images" by incorporating them directly into their reasoning process and manipulating them as needed.
What are the key findings? While the results aren’t groundbreaking (which no one should’ve expected that), both models show significant performance improvements across various domains. o3 established new state-of-the-art benchmarks in coding (Codeforces, SWE-bench), math, science, and visual perception tasks like MMMU. In real-world evaluations, o3 made 20% fewer major errors than its predecessor, particularly excelling in programming, business consulting, and creative ideation. Meanwhile, o4-mini achieved remarkable efficiency, becoming the best-performing benchmarked model on AIME 2024 and 2025, despite its smaller size. Both models demonstrated improved instruction following and produced more verifiable responses than previous iterations. The research also confirms that the "more compute = better performance" trend observed in pre-training holds true for reinforcement learning as well.
Why does it matter? We’re at a point where a lot of people professionals are using LLMs to augment their productivity. There’s a strong need for capable and flexible AI assistants that combine deep reasoning with practical tool use. By enabling models to independently decide when and how to employ different tools, OpenAI is moving closer to agentic systems that can execute complex tasks with minimal human guidance. The improved performance-to-cost ratio (with o4-mini often being both smarter and cheaper than its predecessor) makes advanced reasoning capabilities more accessible. Additionally, the open-source Codex CLI experiment opens new possibilities for developers to build applications leveraging these reasoning capabilities.

Papers of the Week:
GFSE, a Graph Transformer with attention mechanisms informed by graph inductive bias, captures transferable structural patterns across domains like molecular graphs and citation networks using self-supervised learning. GFSE generates generic positional encoding, enhancing downstream task performance and reducing task-specific fine-tuning.
LLMs struggle with complex reasoning due to generalization failures and knowledge-augmented reasoning (KAR) limitations: error propagation and verification bottleneck. ARise addresses this by integrating risk assessment of intermediate reasoning states with dynamic RAG within a Monte Carlo tree search paradigm, enabling effective construction and optimization of reasoning plans across multiple hypotheses.
LLMs generate parameterized quantum circuits in OpenQASM 3.0, trained on 14,000 quantum circuits covering optimization problem instances. Fine-tuned LLMs outperform state-of-the-art models, producing parameters with better expectation values than random, advancing quantum computing applications through automated circuit generation.
A tri-encoder sequential retriever models compositional retrieval as a Markov Decision Process (MDP). Trained with supervised data and refined via structural correspondence rewards, it enhances LLMs' complex task handling by explicitly modeling inter-example dependencies, outperforming single-pass retrieval-augmented frameworks.
The article introduces DocAgent, a multi-agent system (Reader, Searcher, Writer, Verifier, Orchestrator) using topological code processing to enhance automatic code documentation generation with Large Language Models (LLMs). It evaluates Completeness, Helpfulness, and Truthfulness to improve documentation quality in AI-driven software development.
SWE-PolyBench, a repository-level, multi-language benchmark (SWE-PolyBench500), enables execution-based evaluation of coding agents across languages and task types like bug fixes and feature additions. Syntax tree analysis metrics reveal strengths/weaknesses for real-world software engineering tasks.
Hey! The podcast option for the newsletter is amazing — I’m really enjoying it. Loving the overall experience so far! 🎧🙌