
The Gap of Judgement: The Missing Piece for Enterprise AI Transformation
Why your automation efforts might have plateaued

Decades of automation investment have digitized the skeleton of operations. What remains - the unstructured, ambiguous, exception-laden work - is precisely what AI agents are now positioned to solve. But the challenge isn’t capability anymore. It’s control.
There is a strange paradox sitting at the heart of every large enterprise right now. Organizations have spent the better part of three decades and billions of dollars automating their operations. ERP systems, workflow engines, robotic process automation, business intelligence dashboards - the infrastructure of the modern firm is a monument to deterministic logic. And yet, look closely at what actually happens inside a finance or operations team on any given Tuesday, and you will find something surprising: people are still spending the majority of their time doing things that feel, instinctively, like they shouldn’t require a human at all.
This isn’t a failure of effort or investment. It’s a structural property of the problem. Traditional automation is extraordinarily good at one specific thing: executing deterministic sequences on structured data. But enterprise reality is the opposite of deterministic. It is a landscape of intersecting, contradictory signals - an invoice that doesn’t match the PO, a vendor change request that cascades across seventeen open commitments, an exception that doesn’t fit any of the rules written into the system three years ago. Humans have always lived in that gap. Until now, nothing else could.
The Automation Plateau
The data here is uncomfortable in its persistence. NetSuite cites research showing that just 35% of finance professionals’ time goes to high-value insight work - the remaining 65% absorbed by routine data collection and validation. McKinsey puts the problem even more starkly: you cannot drive a business forward while spending 80% of your time on reporting and manual transactions. And despite near-universal investment in automation tooling - McKinsey’s 2024 CFO Pulse found 98% of finance leaders had invested in automation technologies in the prior twelve months - 41% of CFOs report that fewer than a quarter of their processes are actually automated.
This means that - if we oversimplify the numbers above for the sake of the argument - 60-70% of finance professional time is consumed by tasks that, in principle, should not require human judgment at all: gathering data across fragmented systems, reconciling numbers between spreadsheets and ERPs, managing exceptions that fall outside the logic of deterministic rules. That number has barely moved in a decade, despite massive investment in automation tooling.
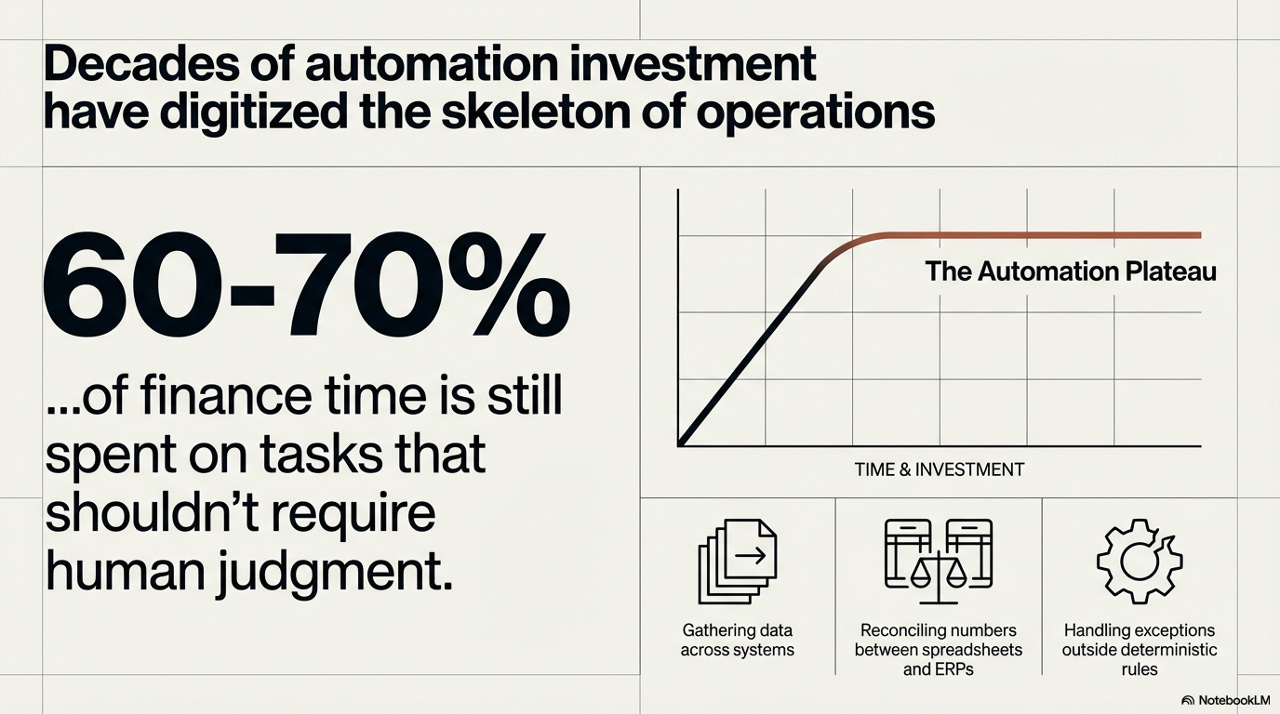
The reason is visible in the shape of the productivity curve. Traditional automation follows a classic S-curve: rapid value creation early, followed by a plateau where incremental investment yields diminishing returns. What gets automated first is always the easiest - the structured, predictable, rule-bound work. What remains on the plateau is the residue: everything that requires context, judgment, cross-system interpretation, and the capacity to reason under ambiguity. The plateau is not a bug. It is the logical terminus of the deterministic approach.
The automation plateau is not evidence that organizations haven’t tried hard enough. It’s evidence that they’ve been using a fundamentally limited instrument - and have now reached the edge of what that instrument can do.
This distinction matters enormously for how we think about what comes next. The conversation in most boardrooms is still framed around whether AI will disrupt their industry, when the more operationally urgent question is much narrower and more tractable: can we finally automate the work that traditional automation has always failed to automate?
The Gap of Judgment
The architectural reason for the plateau has a name: the Gap of Judgment. It is the space between what deterministic automation can handle and what enterprise operations actually require. On one side of the gap sits everything that RPA and ERP were built for - if-then logic, structured data, predictable sequences. On the other side sits enterprise reality: unstructured reasoning, exception handling, cross-system translation, and the ability to make sense of situations that were never anticipated when the rules were written.
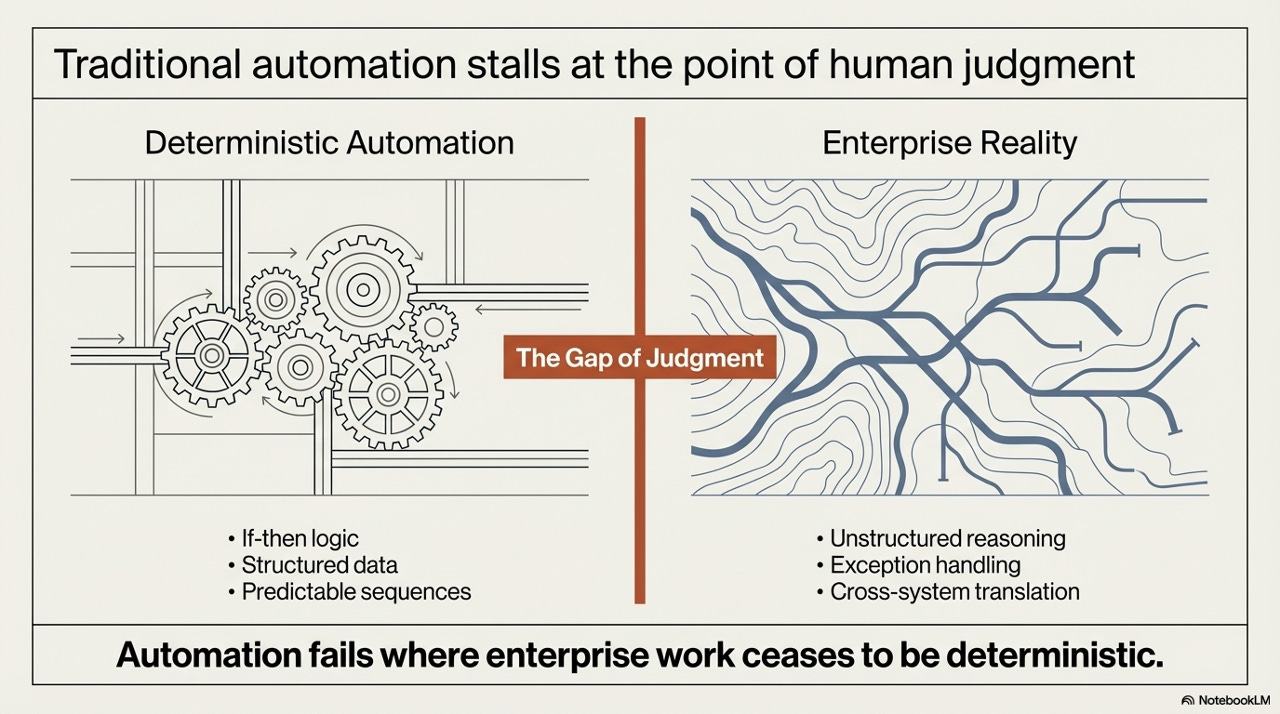
What makes the Gap of Judgment so durable is that it’s not simply a matter of complexity - it’s a matter of type. No amount of additional if-then rules bridges it, because the nature of the work on the other side of the gap is fundamentally probabilistic. Someone needs to reason about whether a given vendor exception is likely a data entry error or a legitimate dispute, and route it accordingly. Someone needs to look at a set of signals across four different systems and infer a coherent story about what’s happening to a payment. These are not lookup operations. They are inference operations. And inference, until very recently, was exclusively human territory.
Large Language Models changed this equation - not because they replaced the need for structured systems, but because they introduced, for the first time, something that can operate in the inference space. LLMs can handle ambiguity, reason through multi-step situations, and translate across incompatible data formats. The question that matters for enterprises is not whether these capabilities are real. It’s whether they can be deployed in a way that meets the control, compliance, and governance requirements of a regulated enterprise environment.
Three Stages, One Architecture
It is worth being precise about what “agentic AI” actually means in this context, because the term has been applied loosely to a spectrum of very different systems. The maturity path runs through three distinct stages, and conflating them leads to serious strategic errors.
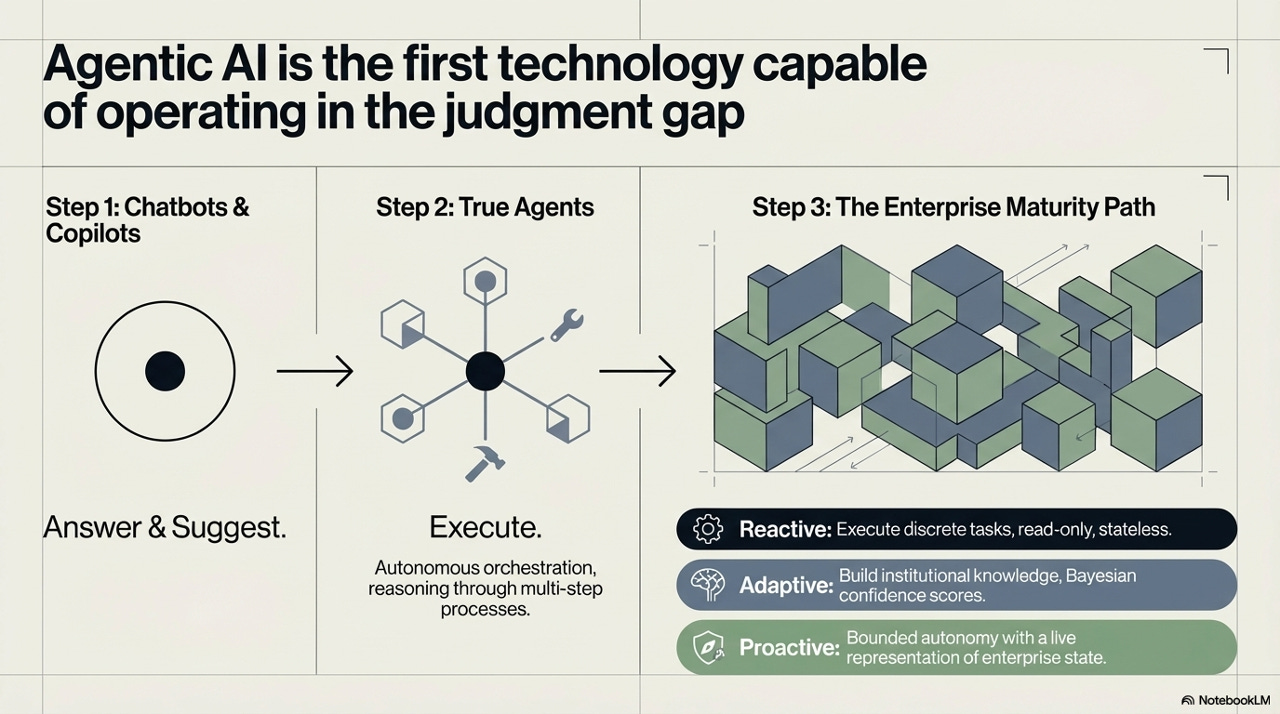
Stage one - chatbots and copilots - is where most enterprise AI deployments currently live. The AI answers questions, generates drafts, suggests actions. A human receives the output and decides what to do with it. This is genuinely useful, but it does not address the automation plateau because it still requires a human in the critical path of every task. The bottleneck moves slightly, but does not disappear.
Stage two is where the substantive transformation begins. True agents don’t just answer, they execute. They can autonomously orchestrate multi-step processes, call APIs, read from and write to enterprise systems, and reason through sequences of actions that would previously have required sustained human attention. This is the capability that begins to close the Gap of Judgment in a meaningful way.
Stage three - the enterprise maturity path - describes the architectural progression through which an organization operationalizes true agency at scale. This is where the real design work begins, because raw agentic capability is necessary but not sufficient for enterprise deployment.
The path runs through three modes: Reactive (executing discrete tasks, read-only, stateless), Adaptive (building institutional knowledge through Bayesian confidence scoring), and Proactive (bounded autonomy with a live representation of enterprise state). Progression through these modes is not a software upgrade. It is a governance journey.
The Central Problem Is Control, Not Capability
This brings us to what is, in practice, the defining challenge of enterprise AI deployment - and the one that most technical discussions underweight. The question that keeps CIOs and compliance officers awake is not whether LLMs are capable enough to handle enterprise work. Increasingly, they demonstrably are. The question is whether they can do so in a way that satisfies the control, auditability, and regulatory requirements of a real enterprise operating environment.
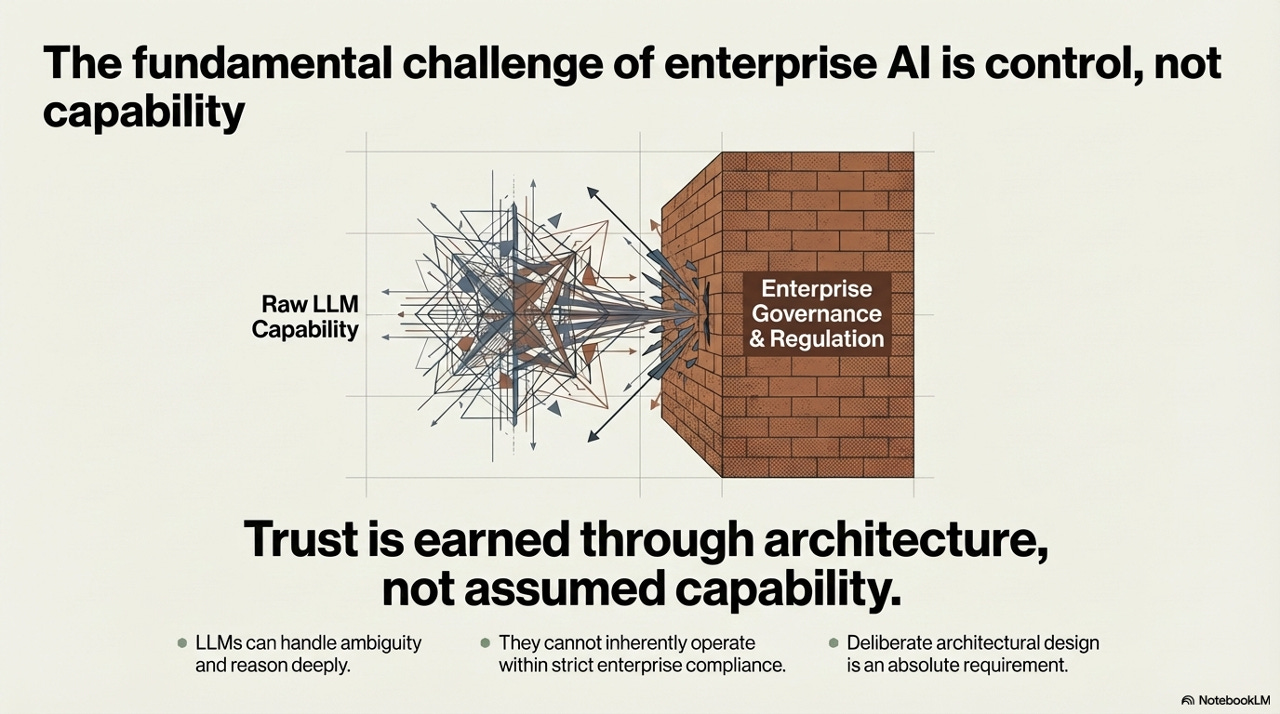
The visual metaphor in the framework is apt: raw LLM capability is energetic and multidirectional, capable of operating across a huge range of tasks and contexts. Enterprise governance is a wall - immovable, intentional, and load-bearing. The productive relationship between these two things is not the LLM crashing through the wall. It is a deliberate architectural interface that lets the LLM’s reasoning capability operate while keeping its actions inside the compliance boundary.
LLMs can handle ambiguity and reason deeply. They cannot inherently operate within strict enterprise compliance. Deliberate architectural design is an absolute requirement. Trust is earned through architecture, not assumed from capability.
This reframing has significant practical consequences. It means that evaluating enterprise AI deployments primarily on the basis of model capability benchmarks is misleading. The relevant question is not “how capable is the model?” but “how well has the architecture been designed to make that capability safely operable in this environment?” These are different problems, and they require different expertise to solve.
The Enterprise Sandbox: A Controlled Execution Boundary
The architectural response to the control problem is what this framework calls the Enterprise Sandbox - a deliberate execution boundary inside which agentic reasoning operates, insulated from direct write access to production systems until outputs have cleared governance checks.
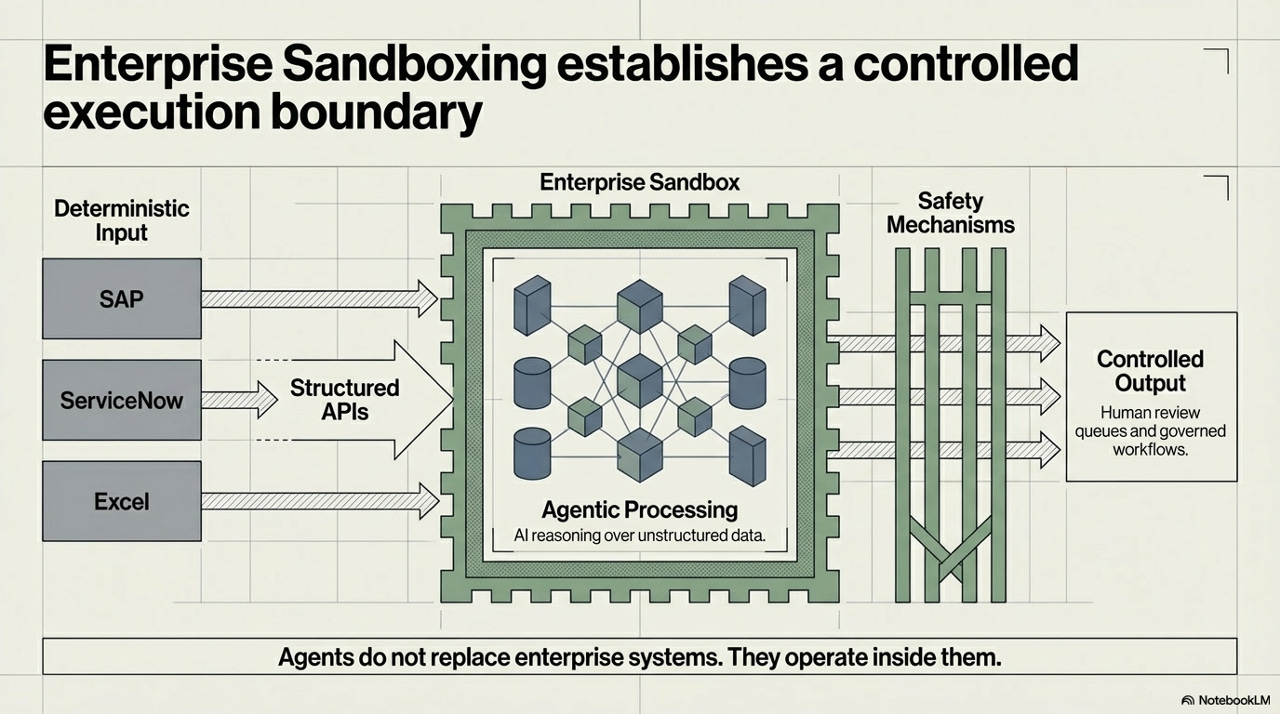
The architecture is worth tracing in detail because the design choices matter. Enterprise systems - SAP, ServiceNow, Excel - are connected to the sandbox through structured APIs. Data flows in, agentic processing happens inside the boundary, and outputs exit through a safety mechanism layer before reaching controlled output channels: human review queues and governed workflows. At no point does the agent touch a live production database directly.
The critical design principle here is inscribed at the bottom of the diagram: agents do not replace enterprise systems - they operate inside them. This is not a rip-and-replace architecture. The ERP is still the system of record. The workflow engine is still the workflow engine. The agent is a reasoning layer that can read, interpret, and propose - but the action still flows through the institution’s existing governance channels. This matters for adoption as much as it matters for safety. Organizations do not need to bet their operations stack on an unproven technology. They need to add an intelligent layer over infrastructure they already trust.
Simulation Before Action: The World Model Concept
One of the more technically interesting ideas in this architecture is the Enterprise World Model¹ - a live representation of enterprise state that agents can reason against before committing any action to a real system. The principle it embodies might be called simulation-before-act, and it deserves careful attention because it fundamentally changes the risk calculus of autonomous AI in enterprise environments.
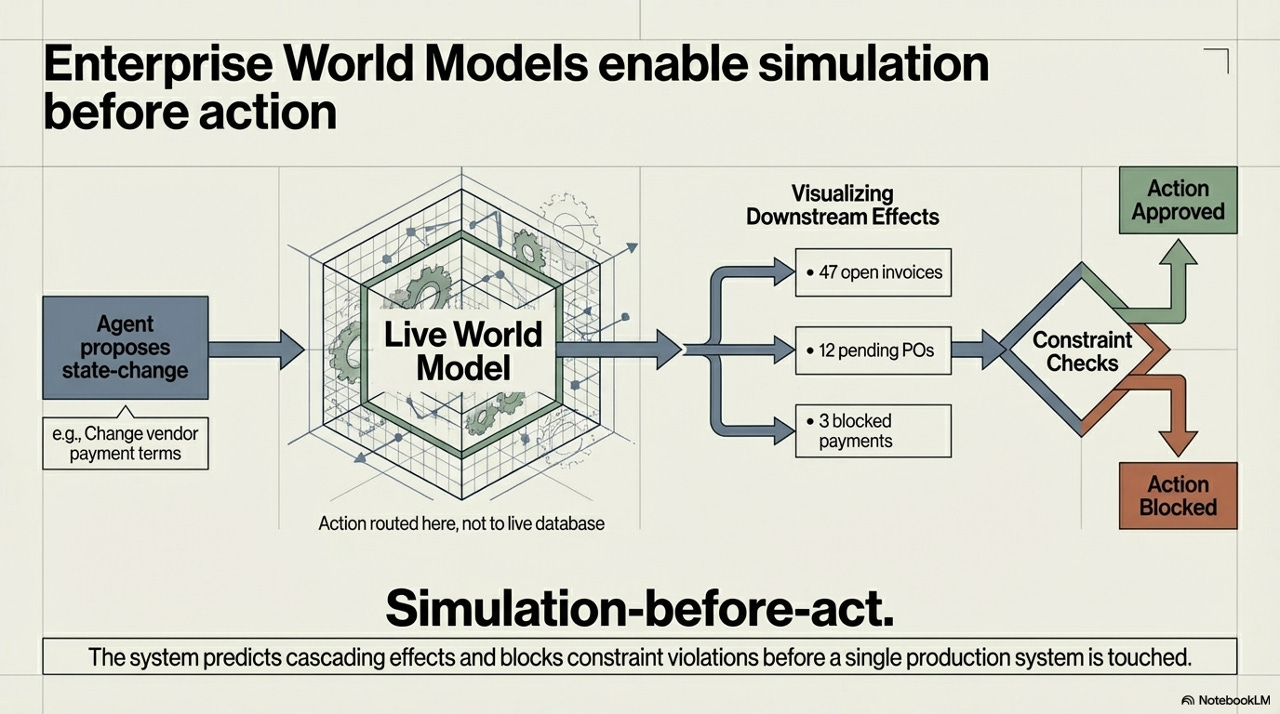
Consider the specific example in the framework: an agent proposes to change vendor payment terms. In a traditional system, this kind of change would either require a human to manually trace all the downstream dependencies - open invoices, pending purchase orders, blocked payments - or it would simply go through and create cascading problems discovered only after the fact. The world model architecture routes that proposed action through a live simulation first. The agent sees 47 open invoices, 12 pending POs, 3 blocked payments. Constraint checks run against that snapshot. The action is either approved or blocked before a single production system is touched.
This is not a small increment over existing validation approaches. It is a qualitatively different capability, because it allows the system to reason about systemic effects - the kind of second- and third-order consequences that humans have always been responsible for tracing, and often fail to trace completely. A world model that can reliably predict cascading constraint violations before action represents a genuine expansion of what safe autonomous operation looks like.
¹We use the term "world model" loosely here, to mean a stateful, dynamic representation of enterprise systems and processes. It's a pragmatic definition, without any appeal to physical simulation or digital-twin architectures.
Context Graphs and Multi-Layer Governance
The governance architecture adds another layer of verifiability through what the framework calls Context Graphs - a mechanism for tracking the relationship between agent actions, predictions, and outcomes over time. The purpose is not just auditability after the fact, but active learning: the system accumulates evidence about the reliability of its own predictions, which feeds back into the confidence calibration of future actions.
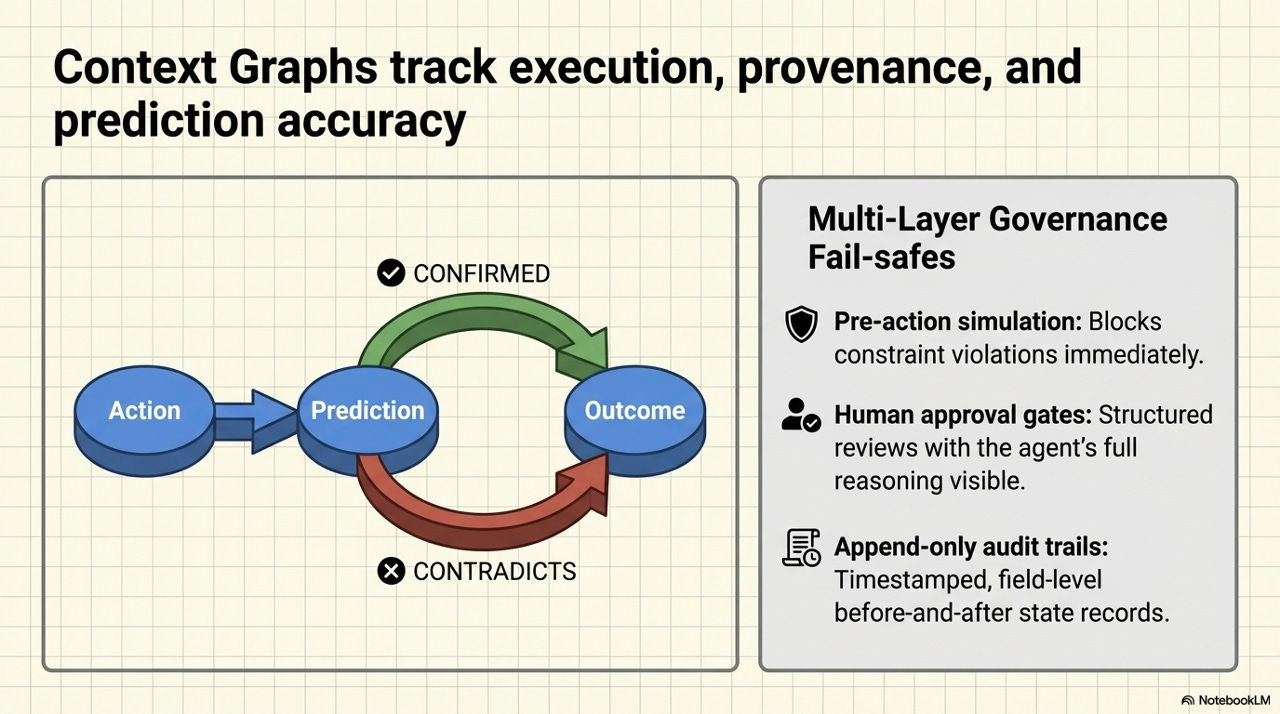
The governance stack assembled here addresses a different class of risk at each layer. Pre-action simulation blocks constraint violations immediately - this is the world model mechanism working upstream of any action. Human approval gates provide structured review with the agent’s full reasoning chain visible - critically, not just the recommendation but the reasoning behind it, so that reviewers are not rubber-stamping opaque outputs. Append-only audit trails create a timestamped, field-level record of before-and-after state for every action - exactly what regulators and internal audit functions require.
Together, these mechanisms represent something important: a shift from asking “do we trust AI?” as a categorical question, to building the empirical infrastructure through which trust can be earned and demonstrated incrementally. That is a much more tractable problem.
²Again, a pragmatic definition - for a much less flawed definition and in-detail explanation of context graphs, I want to recommend this piece from Kurt Cagle.
Integration Without Rip-and-Replace
One of the most practically consequential claims in this framework is the integration philosophy: agentic architecture sits above the existing tech stack, not in place of it. The specific systems named - SAP as system of record, ServiceNow as workflow orchestration, Excel as the finance lingua franca - are not incidental. They represent the actual landscape of enterprise infrastructure as it exists, not as architects might wish it looked.
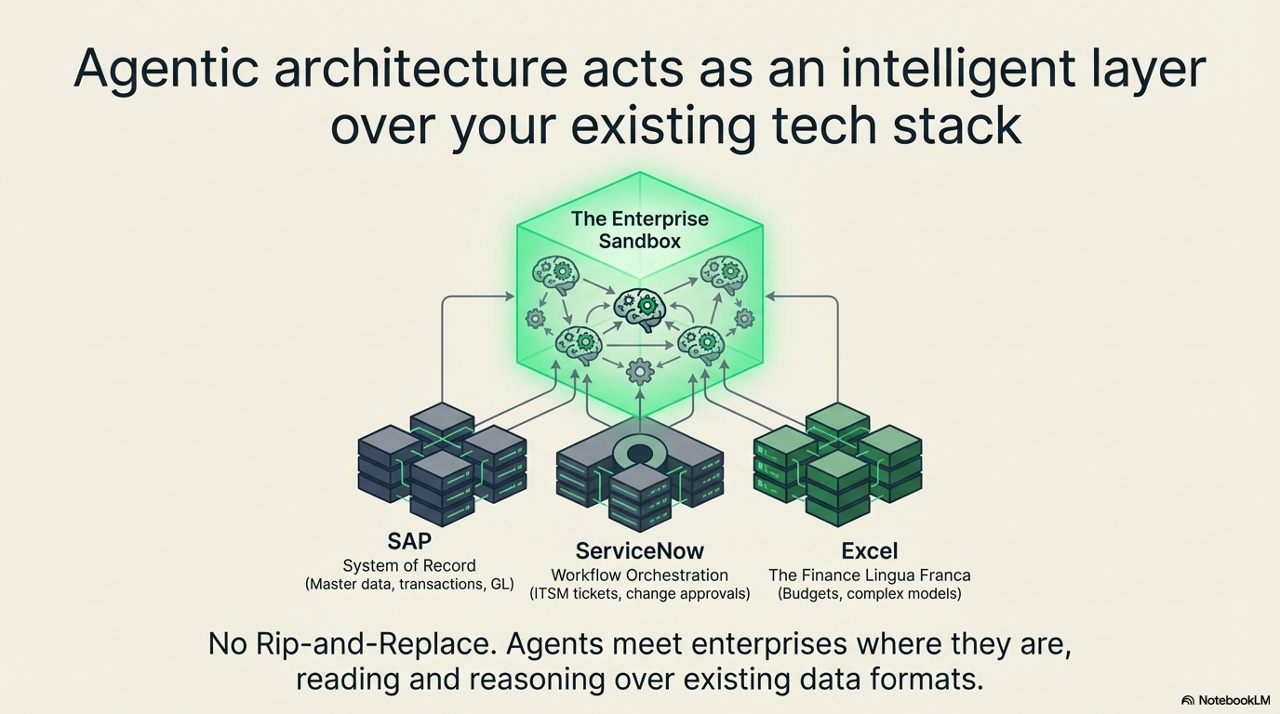
Organizations have spent decades and enormous resources building, customizing, and integrating their core enterprise systems. A deployment approach that required wholesale replacement of that infrastructure would face prohibitive switching costs and organizational resistance - and rightly so, because the institutional knowledge embedded in those systems is real and valuable. An approach that treats the existing stack as the data substrate, and adds intelligent reasoning capability as a layer above it, sidesteps that objection almost entirely. The agents read and reason over existing data formats. SAP remains the system of record. Excel remains the finance lingua franca. Nothing that currently works stops working.
A Data-Driven Progression of Autonomy
How organizations actually move from here to a fully agentic operating model is one of the hardest questions in enterprise AI, and the framework offers a clear structural answer: phased progression, where each phase produces the empirical evidence that justifies the next. This is not a roadmap in the abstract planning sense. It is a feedback-driven escalation protocol.
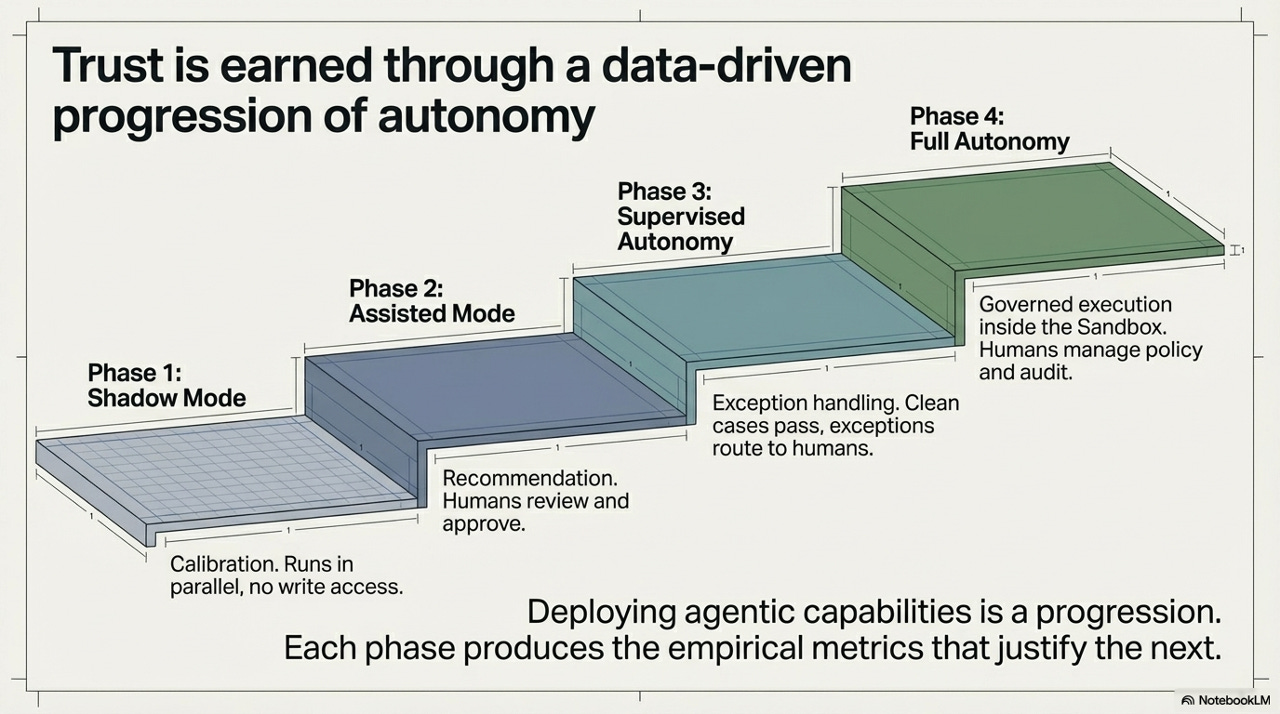
Phase 1 - Shadow Mode. The agent runs in parallel with existing processes, with no write access. Pure calibration - the system generates predictions and recommendations, but nothing is acted on. The purpose is to accumulate accuracy data against which later claims about capability can be evaluated. This phase answers the question: how reliable is this system on our actual data, in our actual environment?
Phase 2 - Assisted Mode. The agent surfaces recommendations; humans review and approve before any action is taken. The bottleneck shifts from human analysis to human review - significantly faster, but the human remains in the critical path. Data from this phase reveals the failure modes and edge cases specific to this deployment context.
Phase 3 - Supervised Autonomy. Clean cases - those that meet confidence thresholds established in prior phases - execute autonomously. Exceptions route to human queues. The human’s role shifts from reviewer of all outputs to exception handler. The organization now has empirical data on where the system is reliable enough to trust without review.
Phase 4 - Full Autonomy. Governed execution inside the sandbox, with humans managing policy and audit rather than individual transactions. The agent operates with bounded autonomy; the human organization’s role is governance, not execution. This phase is only justified by the data accumulated in phases one through three.
The structure transforms trust from a prerequisite into a product. You do not need to decide, in advance, whether to trust AI with your accounts payable process. You run shadow mode, collect data, move to assisted mode, collect more data, and let the empirical record make the decision for you. This is how you should think about governance of complex systems generally - not as a policy problem but as an evidence accumulation problem.
The Compounding Institutional Learning Problem
The final and, in some ways, most important point in this framework concerns the competitive dynamics of agentic adoption - and why the historical intuition about the wisdom of being a fast follower no longer applies.
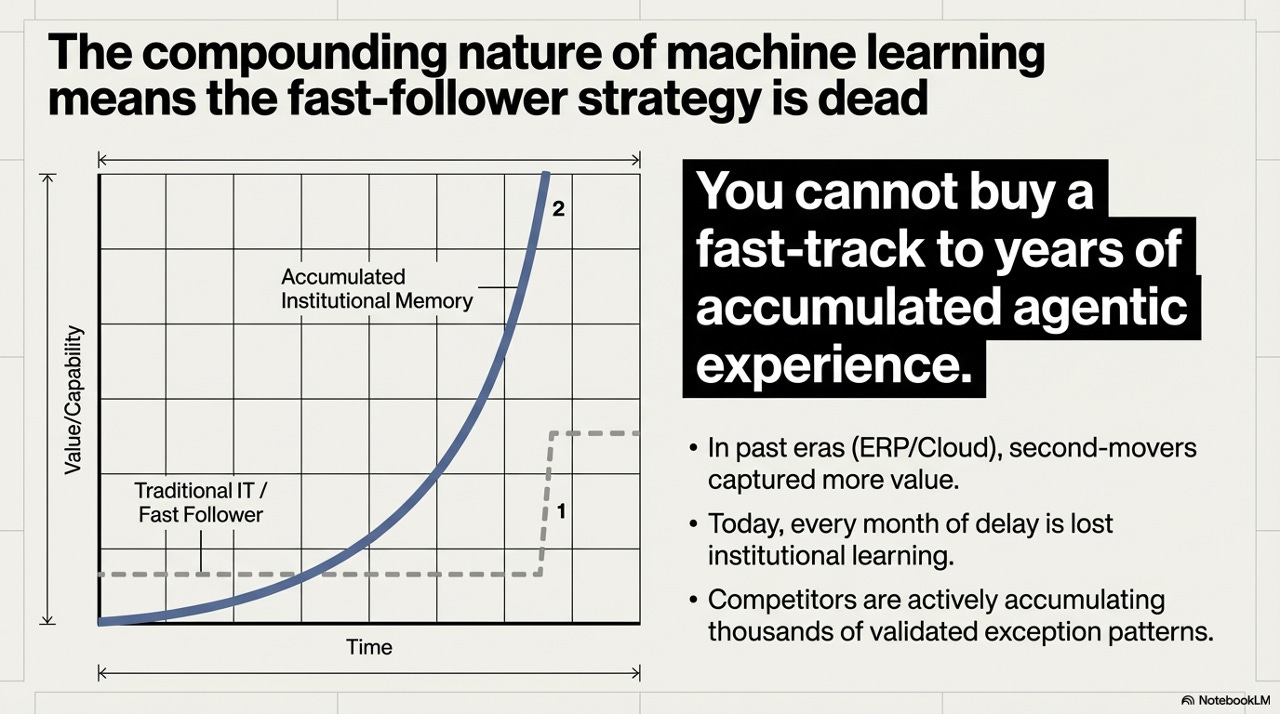
In past technology cycles - ERP, cloud migration - second-movers often captured comparable value to first-movers. The reason is that those technologies were, at their core, software implementations: the institutional knowledge required to operate them did not compound at the rate that the technology itself improved. A company that migrated to SAP in 2008 versus 2010 did not find itself at a permanently unbridgeable capability disadvantage by 2015.
Agentic AI is structurally different, because the value of the system is not primarily in the software. It is in the accumulated institutional memory - the thousands of validated exception patterns, the calibrated confidence models, the learned organizational context - that the system builds through actual deployment. An early-moving organization accumulating agentic experience today is building a data flywheel that grows more valuable compounding over time. A late mover cannot purchase that flywheel. It must be grown from scratch, from the beginning of the learning curve, in an environment where competitors are already operating at phase three or four maturity.
You cannot buy a fast-track to years of accumulated agentic experience. Every month of delay is not just delayed value - it is lost institutional learning that competitors are actively accumulating right now.
This is not an argument for recklessness. The governance architecture described above exists precisely to make disciplined, phased deployment possible and safe. But it is a sharp argument against treating agentic AI as a technology to evaluate seriously in twelve to eighteen months. The organizations beginning phase-one shadow deployments today are not just capturing early value - they are building the institutional knowledge base that will constitute a genuine competitive moat as capability matures.
What This Actually Means
The framework described here is not primarily a technology brief. It is an organizational design argument. The thesis is that the obstacles to deploying autonomous AI in the enterprise have always been more architectural and governance-related than they have been capability-related - and that the capability gap has now closed to the point where the architectural and governance questions have become the binding constraint.
The implication is that the organizations most likely to succeed with agentic AI are not necessarily those with the most sophisticated technical teams. They are the ones that approach deployment as a governance design problem: how do we build the sandbox that lets the reasoning capability operate within our compliance boundary? How do we design the progression through phases that produces the empirical evidence we need to expand autonomy responsibly? How do we structure human approval gates so that reviewers are genuinely informed rather than effectively rubber-stamping?
These are hard questions. But they are tractable ones - which is precisely what makes this moment feel different from the prior waves of enterprise AI investment that generated more hype than operational transformation. The gap of judgment has always been the hardest part of enterprise operations. For the first time, we have technology that can operate inside it, and an architecture that makes that operation controllable. The question is whether organizations have the governance imagination to use it.
Really good thought process. Like the idea of the sandbox in a live environment.
Very insightful!