
🤖 The Future of Designing AI Agents
And the first "true" graph foundation model

In this issue:
Towards efficient graph foundation models
From LLMOps to AgentOps
A Text-to-SQL dataset that breaks LLMs

1. GFT: Graph Foundation Model with Transferable Tree Vocabulary
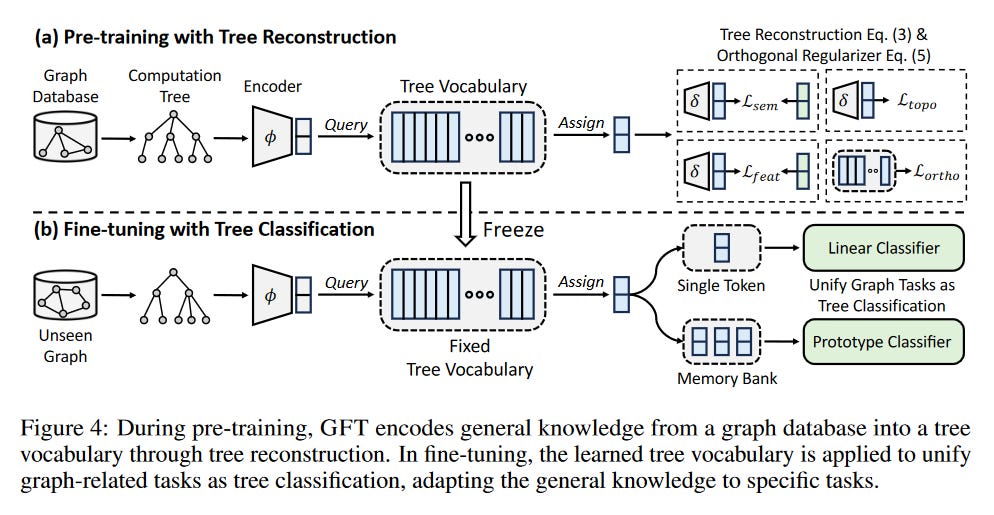
What problem does it solve? Foundation models have proven to be incredibly successful in the domains of natural language and computer vision. The key idea behind foundation models is to pretrain a large model on a vast amount of data in a self-supervised manner, allowing it to capture transferable patterns and knowledge. This pretraining phase is followed by fine-tuning the model on specific downstream tasks. However, directly applying this approach to graph data has been challenging due to the lack of a well-defined vocabulary that encodes transferable patterns shared among different tasks and domains.
How does it solve the problem? GFT (Graph Foundation model with transferable Tree vocabulary) addresses this challenge by introducing a novel concept of computation trees as the transferable vocabulary for graphs. Computation trees are derived from the message-passing process in graph neural networks and capture the local and global structural information of graphs. By treating these computation trees as tokens within the transferable vocabulary, GFT enables effective pretraining and fine-tuning on various graph-related tasks. The model learns to encode graph structures and patterns into a shared representation space, facilitating knowledge transfer across tasks and domains.
What's next? As graph data becomes increasingly prevalent in various domains, such as scientific research, social network analysis, drug discovery, and e-commerce, GFT can serve as a powerful tool for tackling a wide range of graph-related tasks. Future research directions may include exploring more advanced pretraining objectives, incorporating domain-specific knowledge into the model, and extending GFT to handle heterogeneous and dynamic graphs. Additionally, the interpretability and robustness of graph foundation models will be important areas of investigation to ensure their reliability and trustworthiness in real-world applications.
2. A Taxonomy of AgentOps for Enabling Observability of Foundation Model based Agents
Watching: AgentOps (paper)

What problem does it solve? As AI agents powered by foundation models (FMs) become more complex and are deployed in real-world applications, ensuring their reliability and traceability becomes increasingly important. The development and deployment of these agents involve multiple stakeholders, components, and workflows, making it challenging to obtain reliable outputs and answers. Without proper observability and traceability across the entire life-cycle, it becomes difficult to identify and resolve issues that may arise during the development and operation of these AI agent systems.
How does it solve the problem? To address the challenges of reliability and traceability in AI agent systems, the authors propose the concept of AgentOps platforms. These platforms are designed to provide end-to-end observability and traceability across the entire development-to-production life-cycle of AI agents. By conducting a rapid review of the agentic ecosystem, the authors identify essential features and tools that can be incorporated into AgentOps platforms. They provide a comprehensive overview of the observability data and traceable artifacts that should be collected and monitored throughout the agent production life-cycle, enabling developers and operators to identify and resolve issues more effectively.
What's next? The proposed AgentOps framework lays the foundation for building more reliable and traceable AI agent systems. It is crucial, however, to further develop and refine AgentOps platforms to keep pace with the increasing complexity and diversity of AI agent applications. Future research could focus on standardizing observability data formats, developing more advanced monitoring and debugging tools, and exploring best practices for integrating AgentOps into existing development and deployment workflows. Additionally, as AI agents become more widely adopted, it will be important to consider the ethical and legal implications of their use and ensure that AgentOps platforms incorporate mechanisms for accountability and transparency.
3. Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows
Watching: Spider 2.0 (paper/code)

What problem does it solve? While text-to-SQL has been a popular research area in recent years, most benchmarks and datasets are still quite limited in their complexity and real-world applicability. Spider 2.0 aims to change that by providing a new evaluation framework that is much more aligned with the challenges of enterprise-level database use cases. This includes complex cloud or local data across various database systems, multiple SQL queries in various dialects, and diverse operations from data transformation to analytics.
How does it solve the problem? Spider 2.0 comprises 632 real-world text-to-SQL workflow problems derived from enterprise-level database use cases. The databases in Spider 2.0 are sourced from real data applications, often containing over 1,000 columns and stored in local or cloud database systems such as BigQuery and Snowflake. Solving problems in Spider 2.0 frequently requires understanding and searching through database metadata, dialect documentation, and even project-level codebases. This challenge calls for models to interact with complex SQL workflow environments, process extremely long contexts, perform intricate reasoning, and generate multiple SQL queries with diverse operations, often exceeding 100 lines.
What's next? The researchers evaluated their code agent framework based on o1-preview on Spider 2.0 and found that it successfully solves only 17.0% of the tasks, compared with 91.2% on Spider 1.0 and 73.0% on BIRD. These results show that while language models have demonstrated remarkable performance in code generation -- especially in prior text-to-SQL benchmarks -- they require significant improvement in order to achieve adequate performance for real-world enterprise usage. Progress on Spider 2.0 will represent crucial steps towards developing intelligent, autonomous, code agents for real-world enterprise settings.
Papers of the Week:
LLMs as Method Actors: A Model for Prompt Engineering and Architecture: Method Actors treats LLMs as performers solving NYT's Connections word puzzle. GPT-4 achieves 86% success versus Chain of Thoughts' 41%. OpenAI's o1-preview reaches 100% success via multiple API calls, with Method Actor prompting increasing perfect solutions from 76% to 87%.
M-Longdoc: A Benchmark For Multimodal Super-Long Document Understanding And A Retrieval-Aware Tuning Framework: M-LongDoc pioneers retrieval for multimodal documents through automatic corpus construction and retrieval-aware tuning. The 851-sample benchmark spanning hundreds of pages achieves 4.6% improvement over baseline open-source models, delivering open-ended solutions for question-answering tasks.
Learning with Less: Knowledge Distillation from Large Language Models via Unlabeled Data: Knowledge distillation enables smaller models to learn from LLMs using pseudo-labels from unlabeled data. LLKD's adaptive sample selection improves this process by prioritizing high-confidence teacher labels and high student information need, achieving superior performance with enhanced data efficiency in natural language processing applications.
Evaluating World Models with LLM for Decision Making: Research evaluates world models and LLMs across 31 environments, comparing GPT-4o and GPT-4o-mini's performance in policy tasks, especially regarding domain knowledge. Studies show performance decrease in long-term decision-making and functional instabilities when combining different capabilities, with GPT-4o significantly outperforming GPT-4o-mini.
Designing Reliable Experiments with Generative Agent-Based Modeling: A Comprehensive Guide Using Concordia by Google DeepMind: Social science researchers face technical barriers in large-scale experiments. Agent-Based Modeling enables simulations, while Generative ABM uses AI-driven agents. The framework provides a step-by-step guide for implementing experiments, including protocols and validation methods. This approach makes computational simulations accessible to researchers.
Tooling or Not Tooling? The Impact of Tools on Language Agents for Chemistry Problem Solving: A comprehensive evaluation of ChemCrow, ChemAgent, and Coscientist examines tool-augmented chemistry LLMs. Expert analysis shows specialized tools aid synthesis prediction but don't consistently outperform basic LLMs. While tools enhance specialized tasks, success with exam questions and general chemistry depends more on fundamental reasoning.
ClinicalBench: Can LLMs Beat Traditional ML Models in Clinical Prediction?: ClinicalBench compares 14 general-purpose LLMs, 8 medical LLMs, and traditional ML models across two databases using various prompting strategies. Despite testing on clinical prediction, reasoning, and decision-making tasks, traditional models like SVM and XGBoost outperform LLMs. The benchmark's evaluation of medical licensing exams and healthcare applications suggests caution with LLM implementation.