
💻 ALE-Agent: AI Coding on Steroids
Learn about ALE-Agent, Autoregressive U-Nets, and DeepResearch Bench
Welcome, Watcher! This week in LLM Watch:
From AI Coding to Algorithm Engineering
Language Modeling without Tokenization
Evaluating Deep Research Agents
Don’t forget to subscribe to never miss an update again.
Courtesy of NotebookLM
1. ALE-Bench: A Benchmark for Long-Horizon Objective-Driven Algorithm Engineering
Watching: ALE-Bench (paper/code)
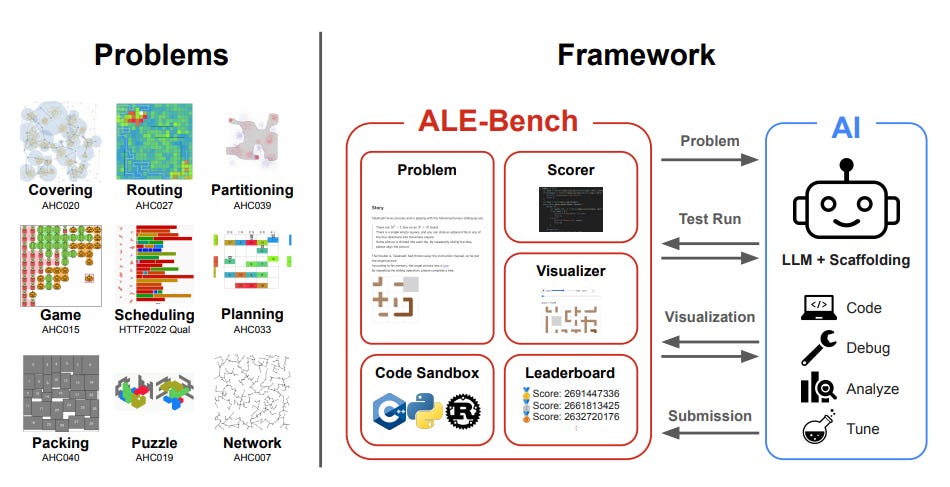
What problem does it solve? Current LLM benchmarks for competitive programming focus on short-duration, pass/fail problems with exact solutions. However, real-world algorithm engineering often involves NP-hard optimization problems where finding the true optimum is computationally infeasible. ALE-Bench is a new benchmark based on AtCoder Heuristic Contests, where participants spend weeks iteratively refining solutions to maximize scores rather than achieving binary correctness. This tests AI systems' ability for long-horizon reasoning and continuous improvement, essential for industrial optimization tasks like routing and scheduling.
How does it solve the problem? The authors developed ALE-Agent, which combines two key methods. Method 1 injects domain knowledge directly into prompts, providing guidance on standard algorithm engineering techniques like simulated annealing and beam search, including search space design and acceleration tricks. Method 2 employs diversity-oriented search using best-first search with a beam width of 30, generating multiple child nodes simultaneously to avoid local optima. This approach generated approximately 1000 solution codes compared to ~100 for standard iterative refinement, with parallelized candidate generation to manage API latency effectively.
What are the key findings? ALE-Agent dramatically outperformed other solutions, achieving an average performance of 1879 (top 6.8%) compared to sequential refinement approaches like o4-mini-high (1411), Gemini 2.5 Pro (1198), and GPT-4.1 mini (1016). The performance distribution showed remarkable consistency with 100% of problems achieving ≥400 performance and 70% achieving ≥1600 performance. Its greatest achievement was scoring 2880 on problem AHC039, placing 5th in the original human contest.
Why does it matter? These results demonstrate that sophisticated scaffolding can elevate AI performance from novice/intermediate levels to compete with human experts in algorithm engineering. The synergistic effect of combining domain knowledge with extensive search (61.1% improvement from base) shows that the right architectural choices matter more than raw model capability alone. This has immediate practical implications for deploying AI in industrial optimization domains like package delivery, crew scheduling, and power-grid balancing, where even small improvements can yield significant real-world impact.
2. From Bytes to Ideas: Language Modeling with Autoregressive U-Nets
What problem does it solve? Language models typically rely on tokenization schemes like Byte Pair Encoding (BPE) that chop text into fixed vocabulary units before training even begins. This creates a rigid system where models are locked into a specific granularity - they can't access individual characters when needed for tasks like spelling, yet they're forced to process common words as multiple tokens. The tokenizer becomes a bottleneck: models struggle with rare languages not well-represented in the vocabulary, fail at character-level reasoning, and require massive embedding tables that map each token ID to a vector while obscuring obvious relationships (like "strawberry" and "strawberries" sharing most letters).
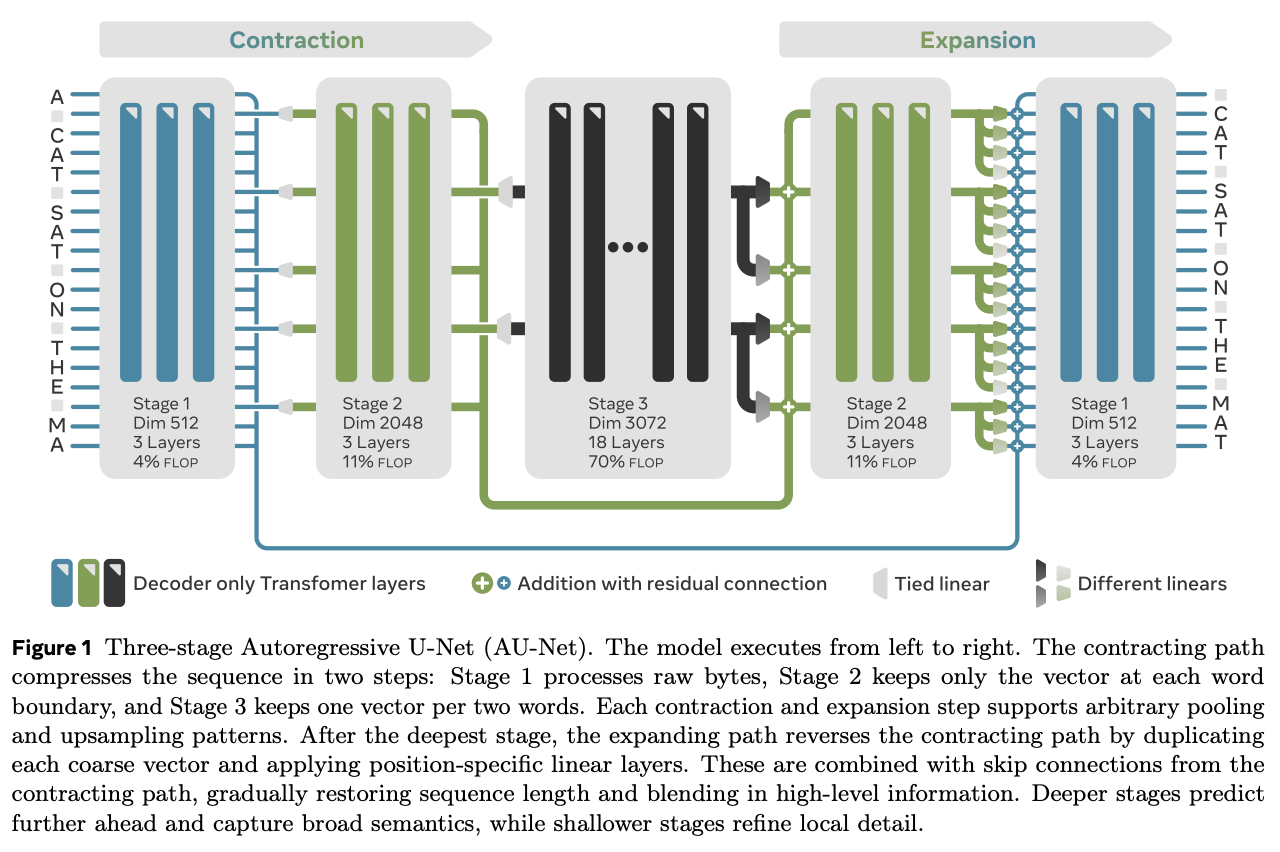
How does it solve the problem? AU-Net (Autoregressive U-Net) processes raw bytes directly and learns its own hierarchical tokenization during training. The architecture uses a U-Net design with contracting and expanding paths: Stage 1 processes individual bytes, Stage 2 pools at word boundaries, Stage 3 at word pairs, and Stage 4 at four-word chunks. Instead of using lookup tables, AU-Net employs attention mechanisms to create contextualized embeddings at each level. The key innovation is that deeper stages naturally predict further into the future - while Stage 1 predicts the next byte, Stage 4 effectively predicts the next four words, creating an implicit multi-scale prediction objective without auxiliary losses.
What are the key findings? When evaluated under identical compute budgets, AU-Net matches or exceeds strong BPE baselines across multiple benchmarks, with deeper hierarchies (2-3 stages) showing particularly promising scaling trends. The architecture excels at character-level manipulation tasks on the CUTE benchmark and demonstrates superior cross-lingual generalization on FLORES-200, especially for low-resource languages that share orthographic patterns with better-represented languages. For instance, on a 1B parameter model trained on 370B tokens, AU-Net-3 achieves 72.9% on HellaSwag compared to 70.2% for the BPE baseline, while AU-Net-4 reaches 31.7% on MMLU versus 27.0% for BPE.
Why does it matter? This challenges the assumption that tokenization must be a separate preprocessing step, showing that models can learn their own adaptive representations while maintaining competitive performance. By operating on raw bytes, AU-Net eliminates vocabulary constraints, enabling better handling of morphologically rich languages, code switching, and character-level reasoning - all without sacrificing the efficiency benefits of hierarchical processing. The approach is particularly valuable for multilingual applications and low-resource languages, where traditional tokenizers often fail. More broadly, it suggests that many "fixed" components of the LLM pipeline might benefit from being learned end-to-end, opening new avenues for more flexible and capable language models.
3. DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents
Watching: DeepResearch Bench (paper/code)

What problem does it solve? Deep Research Agents (DRAs) have emerged as one of the most widely deployed categories of LLM-based agents, capable of autonomously orchestrating web exploration, retrieval, and synthesis to transform hours of manual desk research into minutes. However, evaluating these agents comprehensively remains a major challenge. Current benchmarks focus on isolated capabilities like web browsing or text generation, but fail to assess the end-to-end performance of agents conducting actual deep research. Moreover, evaluating the quality of lengthy research reports is inherently subjective - there's no clear "ground truth" for complex research queries, and the agents' internal reasoning processes remain opaque.
How does it solve the problem? DeepResearchBench was built by first analyzing 96,147 real user queries to understand actual research needs, ultimately identifying 44,019 that qualified as deep research tasks. They recruited PhD-level experts across 22 domains to craft 100 high-quality benchmark tasks that reflect this real-world distribution. To evaluate DRAs, they developed two novel frameworks: RACE dynamically generates task-specific evaluation criteria and weights, then uses reference-based scoring to compare reports - essentially asking "how does this report compare to a high-quality reference?" rather than scoring in isolation. FACT extracts statement-URL pairs from reports and verifies whether cited sources actually support the claims made, measuring both citation accuracy and the total volume of verifiable information retrieved.
What are the key findings? When evaluating leading DRAs, Gemini-2.5-Pro Deep Research achieved the highest overall performance with a RACE score of 48.88 and an impressive 111.21 effective citations per task - far exceeding other models. However, citation accuracy varied significantly: while Perplexity Deep Research achieved 90.24% citation accuracy, Gemini and OpenAI's offerings lagged at around 77-81%. The RACE framework demonstrated remarkable human alignment, achieving 71.33% pairwise agreement with expert evaluators - actually exceeding the 68.44% agreement between human experts themselves. Among general LLMs with search tools, Claude-3.7-Sonnet performed surprisingly well, even outscoring some specialized DRAs.
Why does it matter? The high human consistency of the evaluation frameworks means developers can now reliably benchmark their systems without expensive human evaluation at scale. The results reveal a critical trade-off: models that retrieve the most information don't necessarily cite it most accurately, highlighting different architectural strengths. Perhaps most importantly, by grounding the benchmark in real user needs and making both the dataset and evaluation tools open-source, this research provides a concrete target for advancing DRAs toward practical, trustworthy systems that can genuinely augment human research capabilities.

Papers of the Week:
TableRAG: A Retrieval Augmented Generation Framework for Heterogeneous Document Reasoning
VideoDeepResearch: Long Video Understanding With Agentic Tool Using
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
AceReason-Nemotron 1.1: Advancing Math and Code Reasoning through SFT and RL Synergy