
9 Papers You Should Know About
Get ahead of the curve with LLM Watch

Welcome, Watcher! This week in LLM Watch, we will learn about LLM agent systems, reinforcement learning techniques, multimodal models, and theoretical analyses. The highlights include:
A method to diagnose failures in multi-agent LLM systems
Surveys of agentic RL and implicit reasoning in LLMs
A new medical LLM achieving state-of-the-art via interactive training
Insight into the limits of embedding-based retrieval
And many more! Feel free to check out the glossary below or jump straight to the paper section.
Quick Glossary (for the uninitiated)
Agentic RL: Using reinforcement learning to make LLMs act - plan, call tools, and adapt - rather than just generate text.
Failure attribution (in agents): Figuring out which step, tool call, or sub-agent caused a multi-agent pipeline to fail.
TIR (Tool-Integrated Reasoning): Letting a model iteratively invoke tools (code, search, calculators) across multiple turns to solve a problem.
Void turn (SimpleTIR): A step that produces no useful progress (no result, no final answer). Filtering these stabilizes RL for multi-turn tool use.
Generative judge (Stepwise judging): A “critic” model that reasons step-by-step with the solver to evaluate each intermediate step, not just the final answer.
Implicit reasoning: Useful internal computation the model performs without printing chain-of-thought - faster, cheaper, and sometimes more robust.
Pretraining optimizer: The algorithm (e.g., AdamW, Muon, Soap) that updates weights during large-scale training; real speedups depend on fair tuning at scale.
Embedding-based retrieval: Fetching items by nearest neighbors in a vector space, powerful but bounded by the embedding dimension’s expressivity.
Top-k set (retrieval): The k items an index returns for a query; theory shows a fixed-dimensional embedding can only realize a limited variety of these sets.
AgenTracer: Who Is Inducing Failure in the LLM Agentic Systems? (paper/code)
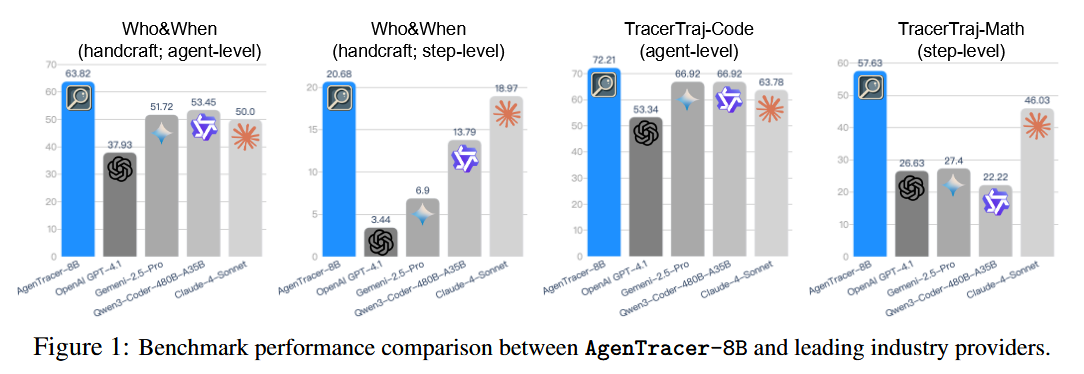
AgenTracer introduces a framework to pinpoint which agent or step causes errors in complex multi-agent LLM systems. Such systems (with multiple LLMs, tools, and orchestration) are powerful but fragile – identifying the culprit behind a failure (the failure attribution problem) has been very challenging (current LLMs succeed <10% of the time). The authors generate a specialized dataset of failed agent trajectories via counterfactual replays and fault injection, and train AgenTracer-8B (an 8-billion parameter tracer model) with reinforcement learning to efficiently diagnose errors in lengthy multi-agent interactions. On the Who&When benchmark, AgenTracer-8B significantly outperforms much larger proprietary LLMs (e.g. Gemini-2.5-Pro, Claude-4-Sonnet) by up to 18.2% in accuracy, setting a new state-of-the-art for failure attribution. Moreover, plugging AgenTracer-8B into existing multi-agent frameworks (like MetaGPT and MaAS) yields 4.8–14.2% performance improvements by providing actionable feedback, enabling these agentic systems to better self-correct and evolve.
SimpleTIR: End-to-End Reinforcement Learning for Multi-Turn Tool-Integrated Reasoning (paper/code)
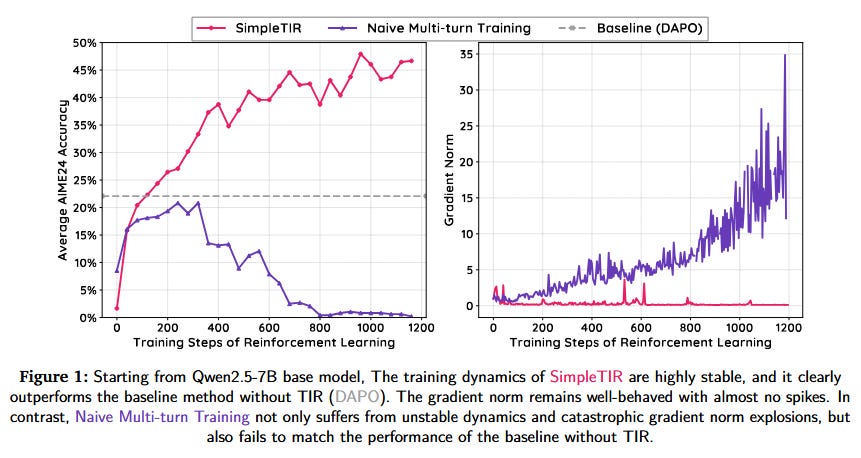
SimpleTIR proposes a solution to train LLMs to use tools over multiple turns via reinforcement learning without the typical instability and collapse. Multi-turn Tool-Integrated Reasoning (TIR) lets an LLM iteratively call external tools (e.g. code execution) to improve reasoning, but prior RL attempts often diverged due to feedback-induced distribution drift – the model generates low-probability tokens, compounding over turns and blowing up gradients. SimpleTIR stabilizes training by filtering out “void” turns (turns that produce neither a code result nor a final answer). By removing these no-progress trajectories from the RL policy updates, it prevents the harmful gradient spikes and keeps learning on track. Experiments on challenging math reasoning tasks show dramatic gains: starting from a Qwen2.5-7B base, SimpleTIR boosts the AIME24 competition score from 22.1 to 50.5, far above a text-only baseline. Notably, because it avoids the constraints of supervised fine-tuning, the RL-trained model exhibits emergent behaviors like self-correction and cross-validation of its answers, demonstrating more robust and diverse reasoning patterns.
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey (paper/code)
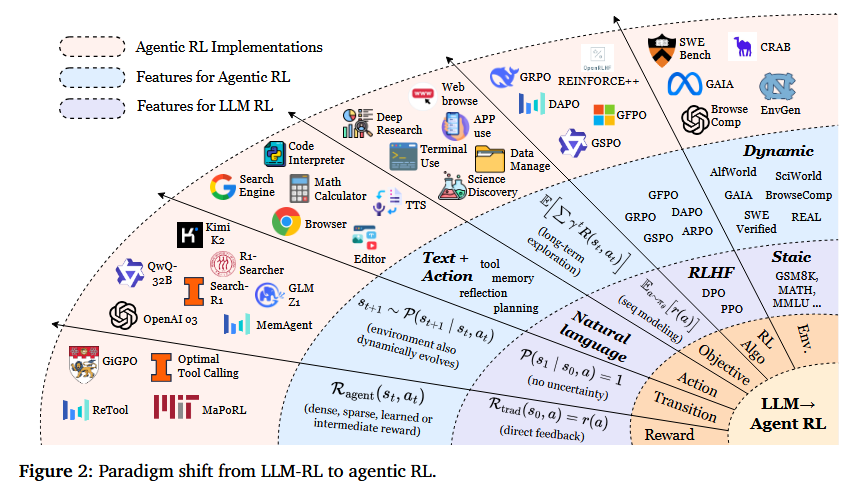
This survey charts the rapidly evolving field of “Agentic RL,” where large language models are treated not just as passive text generators but as autonomous agents that plan, act, and interact in dynamic environments. The authors formalize the conceptual shift from conventional LLM reinforcement learning (which can be seen as a degenerate single-step MDP) to agentic RL framed as a temporally extended, partially observable MDP, better capturing the decision-making setting of LLM agents. They propose a two-part taxonomy: one dimension categorizes core capabilities needed for agentic behavior (planning, tool use, memory, reasoning, self-improvement, perception), and the other covers applications across diverse task domains. Central to their thesis is that reinforcement learning is the critical mechanism to turn these capabilities from static, heuristic modules into adaptive, robust behaviors. The survey consolidates over 500 recent works, along with open-source environments, benchmarks, and frameworks, into a practical compendium. It highlights current opportunities and challenges that will shape progress toward more scalable, general-purpose AI agents in the future.
Quick explanation: With “previous” format I mean the highlight sections that I used for most of this newsletter’s lifespan - “What problem does it solve?”, “How does it solve the problem?”, “What are they key findings?” and “Why does it matter?” - and the current format, obviously, is referring to the one used in this (and the last few) issue(s).
Jointly Reinforcing Diversity and Quality in Language Model Generations (paper)
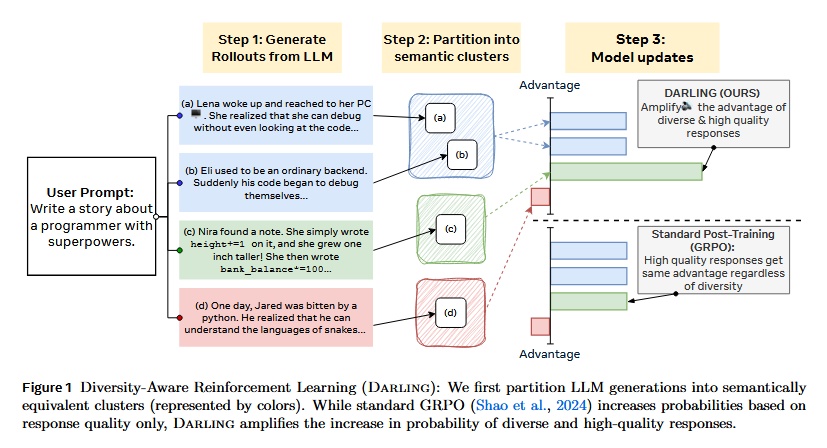
Modern LLM fine-tuning often improves accuracy and helpfulness at the cost of diversity – models become safer and more correct, but also more predictable and prone to repetitive answers. This paper tackles that trade-off by introducing DARLING (Diversity-Aware Reinforcement Learning), a framework to jointly optimize for high-quality and high-diversity outputs. Instead of naively measuring diversity by lexical differences, DARLING learns a partition function that captures deeper semantic diversity beyond surface-level variation. During RL fine-tuning, a reward for this semantic diversity is combined with the quality reward, encouraging the model to explore a broader space of responses. Experiments show that DARLING achieves the best of both worlds: on five creative tasks (open-ended instruction following, storytelling, brainstorming), it produces responses that are not only more novel but also higher quality than those from standard RL fine-tuning. Even on verifiable tasks like math problem solving, explicitly optimizing for diversity yields higher solution accuracy (pass@1) and a greater variety of correct solutions (pass@k). Interestingly, the authors note that fostering diversity actually improves quality – by incentivizing exploration, the model uncovers better solutions, illustrating how diversity can catalyze learning in online RL.
Implicit Reasoning in Large Language Models: A Comprehensive Survey (paper/code)
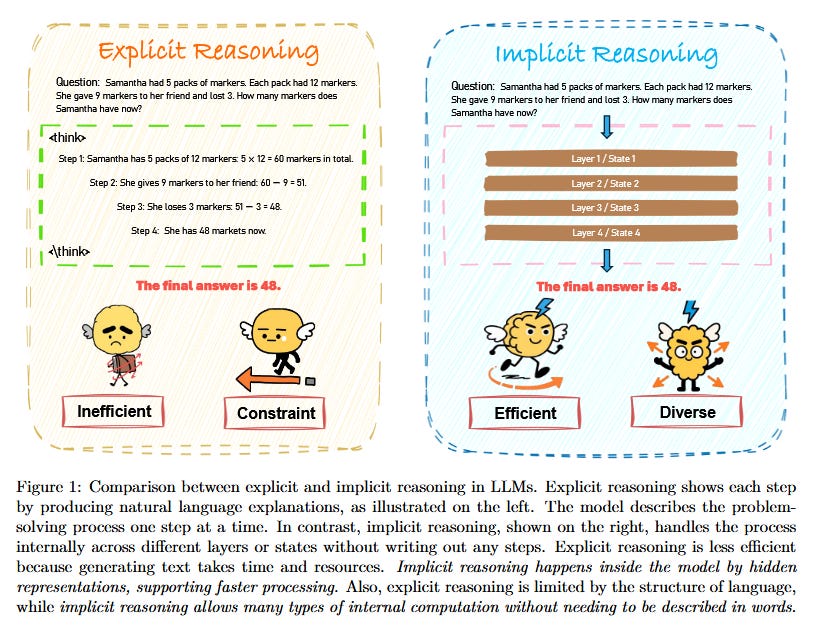
This survey examines how large language models can perform reasoning “under the hood”, without externalizing intermediate chain-of-thought steps. While prompting strategies like Chain-of-Thought explicitly ask the model to generate reasoning steps, implicit reasoning happens silently inside the model’s latent computations, never surfacing as text. Such implicit reasoning is appealing because it can reduce generation cost and latency, and avoid distractions or inconsistencies in the output. The authors point out that, despite some prior discussions of latent representations, there hasn’t been a dedicated mechanism-level analysis of how LLMs reason internally. This survey fills that gap by proposing a taxonomy focused on how and where internal computation unfolds in the model. They classify implicit reasoning methods into three execution paradigms: (1) latent optimization (the model internally optimizes a hidden objective or plan), (2) signal-guided control (external signals or hints influence hidden states to guide reasoning), and (3) layer-recurrent execution (iterative reasoning steps implemented across layers or through recurrent passes within the model). The survey also reviews various structural and behavioral evidence that LLMs do carry out implicit reasoning, and it compiles the evaluation metrics and benchmarks used to assess reasoning quality and reliability. A continually updated project page of resources is provided for researchers interested in this emerging area.
Baichuan-M2: Scaling Medical Capability with Large Verifier System (paper)
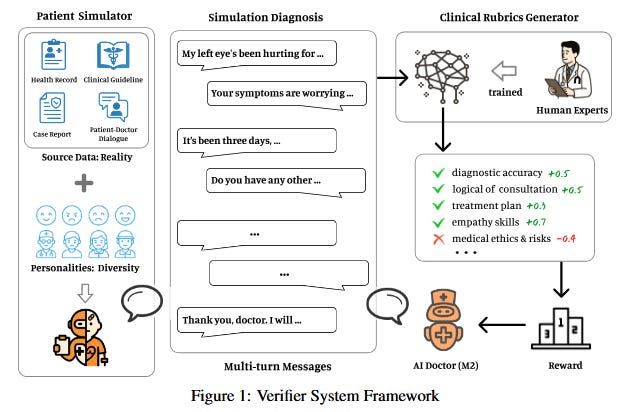
Baichuan-M2 is a new open-source 32B-parameter medical LLM that closes the gap between exam-style benchmark performance and real-world clinical decision-making. The authors note that existing medical LLMs often excel at static benchmarks like USMLE exams, yet struggle with the dynamic, interactive nature of actual medical consultations. To bridge this discrepancy, Baichuan-M2 is trained within a dynamic verifier framework instead of relying on static answer checking. This framework consists of two key components: a Patient Simulator that generates realistic clinical interaction scenarios from de-identified medical records, and a Clinical Rubrics Generator that produces multi-dimensional, context-dependent evaluation metrics on the fly. Together they create a large-scale, high-fidelity interactive RL environment for training the model. Using a multi-stage RL strategy (with a customized Group Relative Policy Optimization algorithm), Baichuan-M2 learns to converse and reason like a clinician. The result is a model that sets a new state-of-the-art on the HealthBench suite: Baichuan-M2 not only outperforms all other open-source medical LLMs, but even surpasses most proprietary models, achieving a score above 32 on the hardest HealthBench subset (a level previously reached only by GPT-5). This work shows that a robust dynamic verifier system is crucial for aligning LLM capabilities with practical clinical use, establishing a new Pareto frontier in the performance–model size trade-off for medical AI.
Fantastic Pretraining Optimizers and Where to Find Them (paper/code)

Despite numerous new optimizers claiming to significantly speed up transformer training, AdamW remains the de facto standard for LLM pretraining. This study investigates why these “fantastic” optimizers haven’t been widely adopted, and conducts a fair, systematic comparison of 10 popular deep learning optimizers under controlled settings. The authors identify two issues that plagued prior comparisons: (i) unequal hyperparameter tuning – often new optimizers were compared using suboptimal settings for AdamW or vice-versa, and (ii) misleading evaluation setups – e.g. measuring progress at intermediate checkpoints rather than after full training. In their experiments across four model scales (from 100M to 1.2B params) and varying data sizes, they rigorously tune each optimizer and evaluate at end-of-training. The findings reveal a more nuanced picture: many optimizers’ actual speedups over a well-tuned AdamW are smaller than advertised, and the gain shrinks with model size. For 1.2B-parameter models, the fastest optimizers only offer about a 1.1x speedup over AdamW (far from the 1.4–2x sometimes claimed). Moreover, performance rankings can flip during training (due to different learning rate decay behaviors), so judging too early can be misleading. Interestingly, the truly top-performing optimizers (like Muon and Soap) share a trait: they use matrix-based preconditioning (applying a matrix to adjust gradient updates rather than simple elementwise scaling). These matrix methods do offer faster convergence for smaller models (e.g. ~1.4x at 100M), but their advantage diminishes as models grow, down to ~1.1x at billion-plus scale. Overall, this 100+ page study provides a grounded assessment of optimizer performance and emphasizes the importance of fair tuning when seeking real training speedups.
OpenVision 2: A Family of Generative Pretrained Visual Encoders for Multimodal Learning (paper/code)
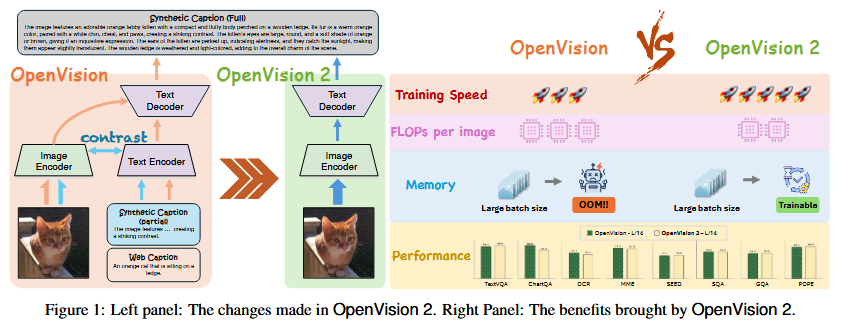
OpenVision 2 is a next-generation open-source visual encoder that achieves CLIP-like multimodal performance with far less training cost. It simplifies the original OpenVision architecture by removing the text encoder and the contrastive loss, using only a single generative objective (image-to-caption) for pretraining. In other words, OpenVision 2 is trained only to caption images (using synthetic and web-crawled captions) and does not explicitly learn to align images with separate text embeddings. Despite this drastic simplification, the model matches the original OpenVision on a broad suite of vision-language benchmarks. Crucially, it is much more efficient: for a ViT-L/14 backbone, OpenVision 2 cuts training time by ~1.5× (from 83 hours to 57 hours) and reduces GPU memory usage by ~1.8× (24.5 GB → 13.8 GB), which allows using much larger batch sizes (up to 8k images). This improved efficiency enabled the authors to scale up the vision encoder to billion-plus parameters, far beyond the largest in the original OpenVision family. The success of this captioning-only, generative pretraining paradigm suggests a compelling direction for future multimodal foundation models – the authors argue that a lightweight generative encoder can achieve strong vision-language performance without the overhead of dual encoders and contrastive training.
On the Theoretical Limitations of Embedding-Based Retrieval (paper/code)
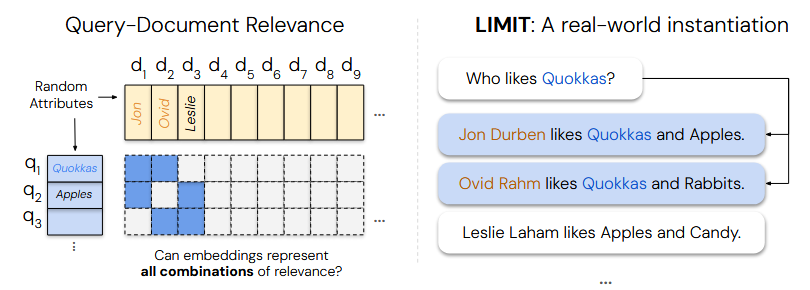
This paper delivers a theoretical wake-up call for embedding-based retrieval methods. Vector embeddings are now used to fetch not just relevant documents, but code snippets, reasoning chains, etc., for virtually any query – raising the question of whether a single fixed-dimensional embedding space can truly handle “any notion of relevance”. Prior works had noted certain theoretical limitations (e.g. the curse of dimensionality or linear separability issues), but many assumed these only manifest on contrived queries and that scaling up models and data would overcome them. Here, the authors prove that fundamental limits arise even in realistic settings: specifically, the number of distinct top‑k sets a similarity search can produce is bounded by the embedding dimension. In simple terms, no matter how good the model is, a $d$-dimensional embedding can only realize a limited variety of retrieval outcomes (top‑k document rankings) – a limit that exists even for very basic queries. They demonstrate this empirically for k=2 on a synthetic task by optimally training embeddings: even with free rein to learn, a low-dimensional embedding cannot distinguish all the needed retrieval cases. To stress-test real models, the authors construct a dataset called LIMIT that embodies these theoretical constraints, yet uses straightforward queries and document relationships. On LIMIT, even state-of-the-art embeddings struggle, failing to retrieve the correct items in cases that the theory predicts they should fail. This work shows that the single-vector retrieval paradigm has an inherent ceiling in what it can represent. It calls for research into new retrieval methods (e.g. higher-dimensional, multi-vector, or adaptive approaches) to bypass this fundamental limitation and handle the growing demands on retrieval systems.
Wrap-Up
If last month was about “bigger brains,” this week is about “better habits.” We saw tools to diagnose agent failures, RL recipes that make multi-turn tool use finally stable, and judges that keep chain-of-thought honest. Two surveys (agentic RL and implicit reasoning) that identify what practitioners are already doing in the wild - turning pattern matchers into adaptive actors.
On the application side, medicine gets a lift from interactive verifier systems that reward real clinical reasoning, not just trivia recall. Under the hood, a careful look at pretraining optimizers reminds us that claimed speedups often shrink at scale. Meanwhile, caption-only visual encoders show we can simplify multimodal pretraining and still hit SOTA. And for everyone building RAG: theory says single-vector retrieval has ceilings - time to explore multi-vector and adaptive retrievers.
The bottom line? The next gains won’t come from one trick, they’ll come from systems thinking - better critics, steadier training loops, smarter memory, and retrieval that matches the task. If you’re shipping agents, this is your blueprint to make them faster, safer, and more reliable.