

Introduction
Large language models (LLMs) have demonstrated remarkable capabilities in natural language understanding and generation tasks. However, their ability to directly answer questions about specific datasets is limited by the information contained in their training data and the capacity of their context window. Retrieval-augmented generation (RAG) approaches address this limitation by first retrieving relevant information from external data sources and then adding this information to the context window of the LLM along with the original query.
While effective for many tasks, existing RAG approaches face challenges when applied to global sensemaking tasks that require an understanding of entire datasets rather than specific facts or passages. In their paper, Microsoft introduces GraphRAG, a new approach that combines knowledge graph generation, RAG, and query-focused summarization. Their approach consists of the following key steps:
Indexing the source texts as a graph, with entities as nodes, relationships as edges, and claims as covariates on edges.
Detecting communities of closely related entities within this graph and generating summaries for each community.
Using these summaries as the knowledge source for a global RAG approach to answering sensemaking queries.
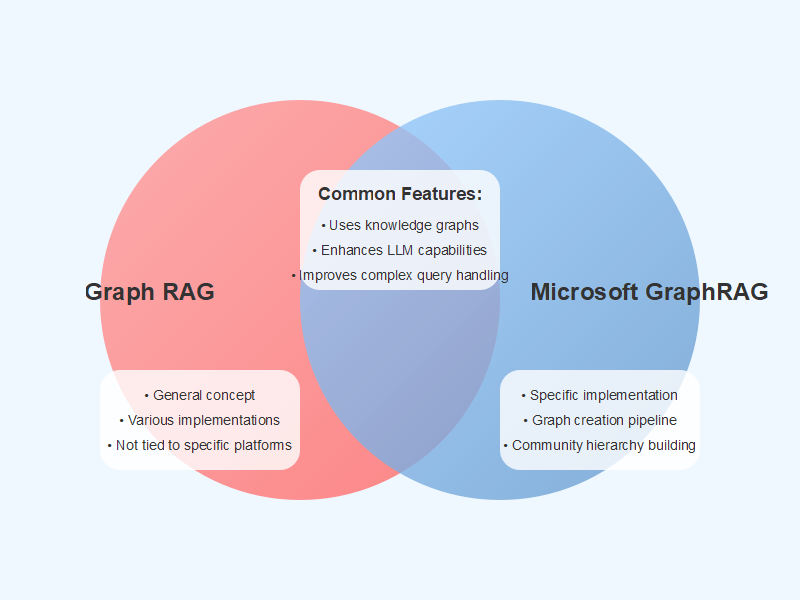
Before we dive deeper into the method, I want to make one thing clear that a lot of people seem to misunderstand: the main focus of GraphRAG is not RAG - it’s the graph construction and summarization pipeline. While the Graph RAG (graph-based RAG) part of GraphRAG is also important, most of the heavy lifting takes place before that. If you only take away one thing from this article, let it be this: Graph RAG (or graph-based RAG) is a general approach that leverages graph inputs for RAG while GraphRAG is a specific method from Microsoft. I try to make this clear in all of my content, but it’s still causing a lot of confusion.
Method
The GraphRAG workflow can be divided into 2 stages with 7 steps: the indexing stage (5 steps) and the query stage (2 steps). During indexing, documents are processed, information is extracted and graphs are created. At query time, first “local” answers are generated based on graph communities relevant to the query. The local answers are then fed as context for the “global” one (global = utilizing the full graph).
Let’s take a closer look at each of the steps and wrap our heads around it.
")
