

Welcome everyone! It has been a while since I featured a guest, but here we are - this time with a piece from Maria. Maria is a Principal AI Expert at Siemens and runs the AI Realist on Substack where she offers her honest view on today’s AI technology. She has been around Natural Language Processing (NLP) for over 15 years and has witnessed the evolution of this field first-hand.
As always, keep in mind that I don’t choose guest posts to validate my own opinion - I choose posts that I personally find interesting and that I think will be valuable to my audience (which is you). Obviously, I wouldn’t pick something I fundamentally disagree with, but diversity of opinions is important for a healthy discourse and there are too few voices of reason in a room full of noise. Anyway, the stage is hers.
For the past year, we’ve heard on multiple occasions that AI agents are going to save the day. LLMs can’t count the “r’s” in strawberries? Agents will! LLMs can’t send your emails? Agents will! LLMs can’t stop hallucinating? Agents, agents, agents…
The “agentic this, agentic that” noise is so strong that managers simply hand their IT departments vague tasks - “build something with agents” - and then go full surprised Pikachu face when it turns out the agents aren’t particularly useful.

Andrej Karpathy recently said:
They just don’t work. They don’t have enough intelligence, they’re not multimodal enough, they can’t do computer use and all this stuff
Amen to this! Finally, a word of reason amid the endless hype!
He added:
They don’t have continual learning. You can’t just tell them something and they’ll remember it. They’re cognitively lacking and it’s just not working… they are just cognitively lacking and are not working… It will take about a decade to work through all of those issues

Let me break down what is cognitively lacking and not working, and why it is going to take at least a decade to fix. I hope that next time when a marketer tries to sell you another autonomous agent that will replace your employees, boost efficiency, and whatnot, you can use these arguments to challenge their claims.
But first, let me tell you about the one place where agents currently work well: coding. They are an absolute must to introduce to your developers. AI-assisted coding works incredibly well. Tools such as GitHub Copilot Agents, Claude Code, and others have shown that they can boost developers’ productivity, take over routine tasks, and help teams code faster.

What is an agent
The best way to cut through all the hype around “agents” being autonomous, proactive decision-makers, or whatever marketing label happens to be trending, is to look at how agents are actually trained and built. This approach quickly demystifies what they are and reveals almost immediately why they fall short of the hype.
Modern LLMs are trained to select and use tools [source, source], enabling what is often called agentic behavior or agentic workflows. Let’s take a look at a typical dataset used to train LLMs for tool selection:
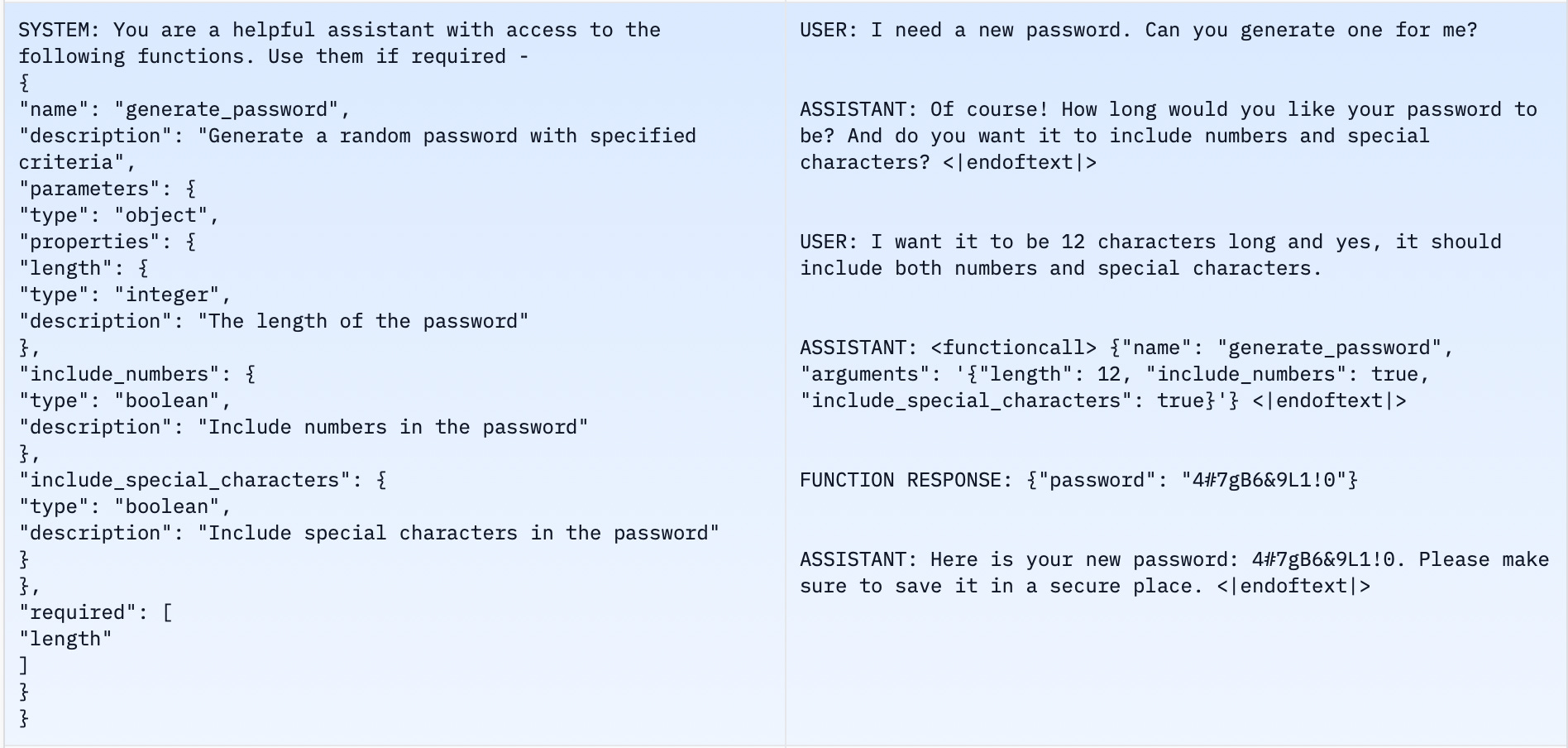
Here is an example from glaiveai/glaive-function-calling-v2, a commonly used open-source dataset for training function calling. As you can see in this dataset, the subset of tools is first defined in the system prompt. The system prompt lists the functions the model can access. Then there are examples of conversations that should trigger function execution. In effect, the model is trained to pick from a limited subset of tools specified in the system prompt.
More elaborated approach is proposed in the paper Plan-and-Act. The idea is basically straightforward, train a system that:
plans,
acts,
observes,
repeats
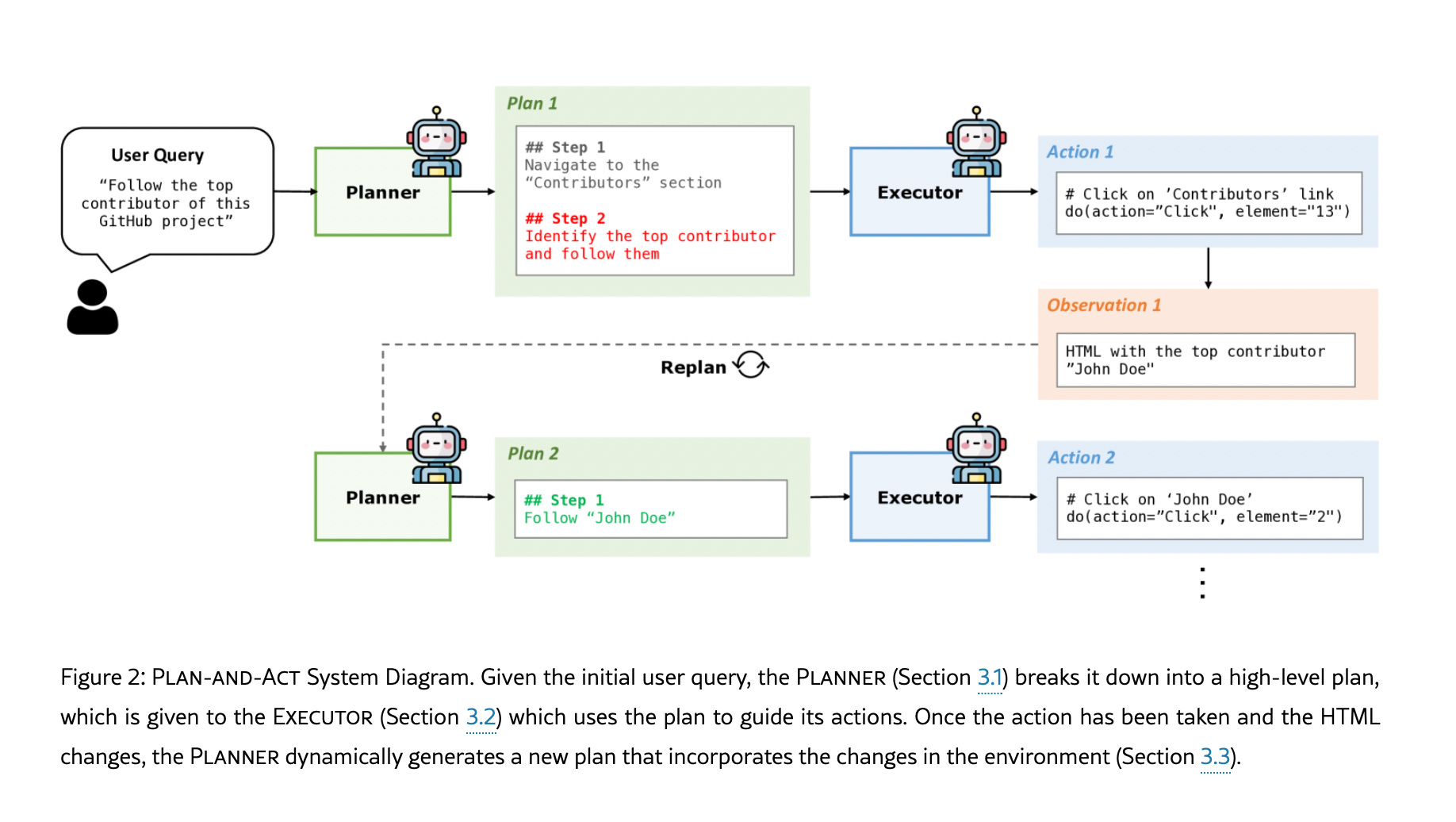
In theory, these systems can self-correct. When planning incorporates chain-of-thought reasoning, it offers a sort of “explanation” of why a tool was selected, but not an actual explanation because it all is just generation and can be hallucinated. These approaches are used for coding agents, and they work well in that setting. Unfortunately, that is not yet the case for general agents beyond coding.
In practice, an agent as currently built is far less intelligent than one might expect. It is essentially a next-token predictor that performs a sequence of reasoning steps and then selects from a predefined tool set. This can be powerful when tasks reduce to clear IF…THEN rules, instructions are simple, and the tool set and its combinations are relatively small.
And, indeed, recent studies show how poorly the agents perform in real world settings:
The paper WebArena: A Realistic Web Environment for Building Autonomous Agents notes that much prior evaluation occurs in sanitized, synthetic settings; when agents are tested in a more realistic web environment, success drops to about 11–14%, compared with 78% for humans.
Another paper, ASSISTANTBENCH: Can Web Agents Solve Realistic and Time-Consuming Tasks? (EMNLP 2024), confirms these results, showing that no agent surpasses roughly 26% accuracy on realistic web tasks.
Now let’s go through the challenges:
Lack of proactive learning
As you can see, nothing in this architecture assumes proactive learning. Suppose you ask the model once to find the best contributors on GitHub. It thinks for a while, makes mistakes, plans an approach, executes it with a few errors, corrects them, you help correct it, and finally it produces the right answer.
The next time you ask the question, the model will know nothing about what happened previously and may repeat the same mistakes or make new ones. There is currently no built-in proactive learning for AI agents.
Error propagation through LLMs
The pipeline relies heavily on planning, and the steps are sequential. It plans, executes, observes, and can repeat this cycle several times. If it makes a mistake in an early cycle, that error can propagate while the system tries to self-correct. There is no native mechanism to roll back to the failure point; an LLM simply keeps generating the next token. It cannot jump back N tokens and restart generation from there, so it may keep producing output and drift further off course.
There are mitigation mechanisms (branching search, self-consistency, Tree-of-Thought style exploration, self-critique and replanning, multi-agent debate, external memory) that can be built on top of the LLM, for example, with prompting. This should be rather viewed as a bandaid. And therefore, peer-reviewed and recent papers show that errors still snowball in multi-step reasoning and planning, and these methods often do not prevent accumulation of earlier mistakes. Also, a very recent analyses of multi-agent debate report that agents can amplify one another’s mistakes and decrease final accuracy, for example by conforming to persuasive but incorrect reasoning.
Absence of multimodality
Coding agents work well also because they do not rely heavily on multimodality. They might occasionally consult a diagram, but most of the necessary information is expressed in natural language or code. Even better, much of it can usually be found in the same environment (e.g., your IDE), which helps the model complete its task.
It is different with real-world agents. Imagine an agent performing annual financial audit checks - this is, for now, unrealistic. Such an agent would need access to many systems: structured logs, invoices, receipts, regulations and laws, and possibly the employee directory. These data types span multiple modalities: text, speech, tables, charts, images, videos, and they do not all reside in one environment. You might need to email vendors for invoices; receipts could be stored in a database; logs might be in the cloud; and relevant laws may need to be retrieved from the internet.
The current agents simply lack the ability to juggle modalities and adapt to processes that cannot be easily defined with a small set of planned steps. In a scenario where an agent discovers that certain receipts are missing or unreadable, the best case is that it stops processing; the worst case is that it behaves sycophantically and tries to finish the process anyway, hallucinating details and ultimately producing inaccuracies that are hard to trace.
Absence of suitable processes for agent integration
The process above is essentially built with a human in mind as the actor. Humans have common sense; they know when to send an email and when to look in the database.
They learn proactively: If they emailed Martin once and he said he has no idea where the invoices are, they won’t email him again 30 seconds later with the same question.
Agents cannot do that. They need processes defined for agentic workflows: the best case is when the process can be written as IF…THEN rules; the next tier is when you can define the process in natural language with instructions. If none of this is possible and much of what you do depends on the outcome of each step, you then decide dynamically what action to take. That action might be completely new - like realizing that all the invoices were moved from Martin’s PC to a newly introduced database -and you need to request permissions to access it. No agent can do this, obviously.
Here’s how the processes should be adjusted to the current agents:

Let us briefly look at the levels of automation:
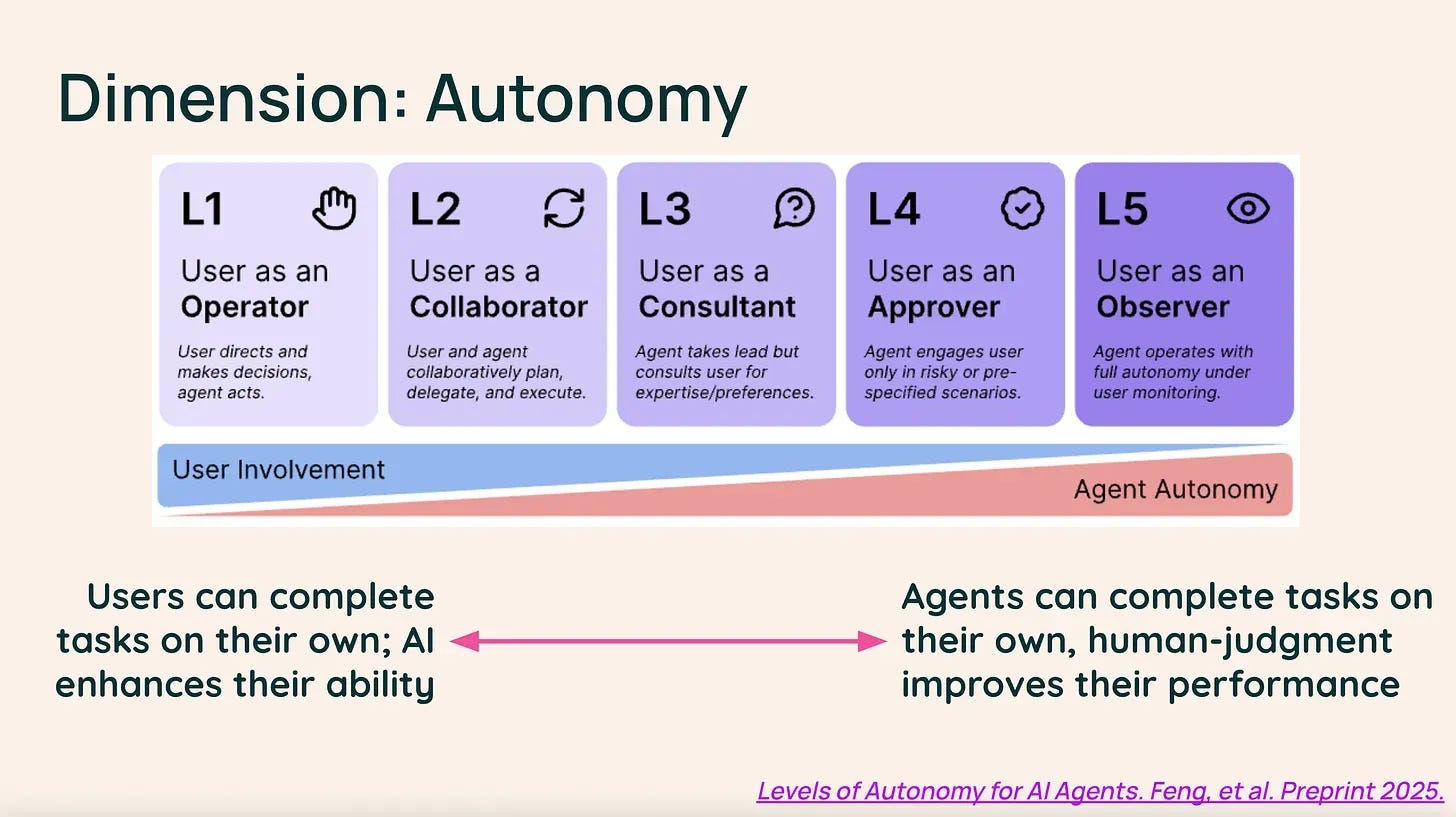
Many companies’ marketing pitches for agentic solutions create the false impression that automation is already near the observer level. That would be exciting, but in reality the level of automation is closer to collaborator at best, probably at the very beginning. Coding agents are somewhat further along, crossing to the consultant level.
It will take a long time for expectations to be met, and progress slows as we approach the finish line - the so-called “last-mile” problem.

Reaching full automation, where the human is merely an observer, is extremely challenging and represents the true last mile of agentic AI.
Andrej Karpathy estimates 10 years; I would be surprised if I see it in my lifetime.
I hope you enjoyed this article. Don’t fall for hype and false promises. We can profit from technology only if we understand its limits and apply it to the right use cases.
❤️ If you enjoyed this guest article, give it a like and share it with your peers
 | A guest post by
|
Nice read from the bed at 4am. While lot of things are hyped because the hypers themselves don't understand the technology we are using (including myself), we should take into consideration a progressive advancing factor, since AI indeed accelerated our technology. Look what happened with coding/programming, and I believe only few could predict that 10 or even just a few years ago. Yes we started realising that AI is not a god yet, but with all the advantages that is giving us right now, we might come to the point you are talking faster. But indeed, 10 years period is a solid guess, it whispers like a moment. Good morning 🌻!