
Watch#8: Extreme Teachers and Mixing Tokens, not Experts
A general trend of making LLM computation more efficient

Foreword:
I have received a few pledges recently and I want to say thank you for that! It’s reassuring to see the support. Both in pledges and messages.
I’m still not entirely sure what kind of additional content to produce for a future paid sub, so if you have ideas or strong opinions about this, please let me know!
Have a great day all,
Pascal
Want to support me going professional as a content creator? Pledge now for future additional content. Your pledge will help me plan ahead and improve my content.
In this issue:
Augmenting Knowledge Transfer with Retrieval
Making Mixture of Experts (MoE) fully-differentiable
In-context Learning for Temporal Graph Forecasting
1. Retrieval-based Knowledge Transfer: An Effective Approach for Extreme Large Language Model Compression
Watching: RetriKT (paper)
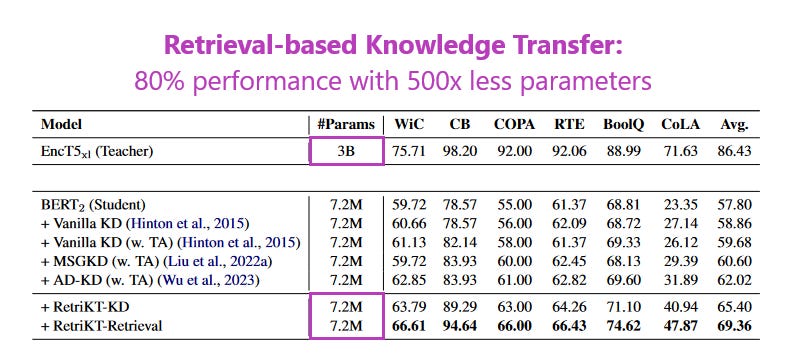
What problem does it solve? Deploying Large Language Models (LLMs) in real-world applications can be difficult due to their massive size. LLMs have achieved state-of-the-art results on a wide range of NLP tasks, but their size makes them computationally expensive to train and deploy. RetriKT addresses this problem by compressing LLMs to extremely small-scale models (e.g., 1%) while maintaining >80% performance.
How does it solve the problem? RetriKT works by extracting knowledge from LLMs to construct a knowledge store, from which the small-scale model can retrieve relevant information and leverage it for effective inference. The knowledge store is constructed by training a retrieval model to predict the most relevant passages from the LLM's training dataset for a given input query. The small-scale model is then trained to predict the next token in a sequence given the input query and the retrieved passages from the knowledge store.
What’s next? RetriKT is one of many compression and knowledge distillation methods that that each have their downsides. It might need a mix of several of these - and also complementary methods that focus on reducing hallucinations and other unwanted outcomes - to arrive at a mix that balances efficiency and robustsness. For a lot of real-world use cases, stakeholders are still worried about deploying even the best LLMs that exist. If one isn’t satisfied with the teacher, a student model won’t be the answer.
2. Mixture of Tokens: Efficient LLMs through Cross-Example Aggregation
Watching: Mixture of Tokens (paper)
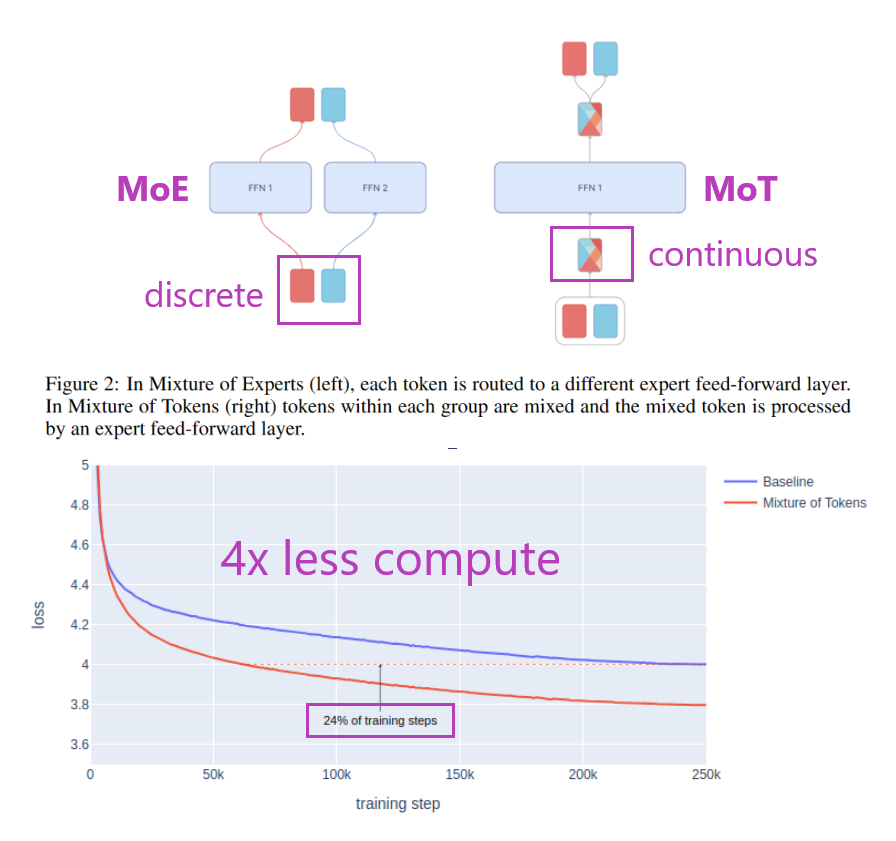
What problem does it solve? Mixture of Experts (MoE) models have shown promise in increasing parameter counts of Transformer models while maintaining training and inference costs. However, MoE models have a number of drawbacks, including training instability, uneven expert utilization, and difficulty in training with masked and causal language modeling.
How does it solve the problem? Mixture of Tokens (MoT) is a fully-differentiable model that retains the benefits of MoE architectures while avoiding the aforementioned difficulties. Instead of routing tokens to experts, MoT mixes tokens from different examples prior to feeding them to experts. This enables the model to learn from all token-expert combinations and avoids the problems of training instability and uneven expert utilization. Additionally, MoT is fully compatible with both masked and causal language modeling training and inference.
What’s next? MoT has the potential to significantly improve the performance and efficiency of LLMs. Being fully-differentiable also makes it easier to train and deploy than MoE. But with how little we know about robust and efficient LLM finetuning yet, it’s hard to make predictions about the adaption of specific techniques without excessive empiric evaluation.
3. Temporal Knowledge Graph Forecasting Without Knowledge Using In-Context Learning
Watching: LLMs for TKG (paper/code)
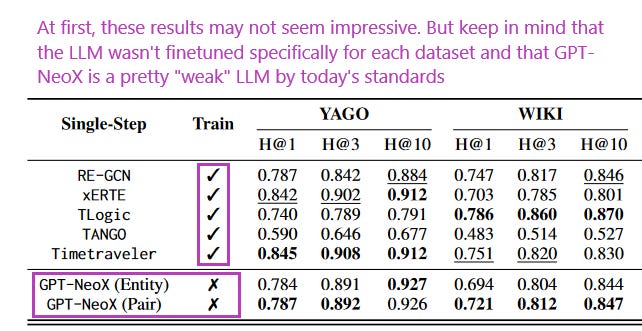
What problem does it solve? Temporal Knowledge Graph (TKG) forecasting benchmarks challenge models to predict future facts using knowledge of past facts. The goal is to investigate whether and to what extent Large Language Models (LLMs) can be used for TKG forecasting, especially without any fine-tuning or explicit modules for capturing structural and temporal information.
How does it solve the problem? The proposed framework converts relevant historical facts into prompts and generates ranked predictions using token probabilities. Surprisingly, they observe that LLMs, out-of-the-box, perform on par with state-of-the-art TKG models carefully designed and trained for TKG forecasting. For their experiments, they present a framework that converts relevant historical facts into prompts and generates ranked predictions using token probabilities.
What’s next? The researchers plan to explore how to improve the performance of LLMs on TKG forecasting tasks by using fine-tuning and explicit modules for capturing structural and temporal information. They also plan to investigate the use of LLMs for TKG forecasting tasks in other domains, such as social media and financial markets.
Papers of the Week:
Democratizing Reasoning Ability: Tailored Learning from Large Language Model
Systematic Assessment of Factual Knowledge in Large Language Models
Explainable Claim Verification via Knowledge-Grounded Reasoning with
Towards Better Evaluation of Instruction-Following: A Case-Study in Summarization
MuSR: Testing the Limits of Chain-of-thought with Multistep Soft Reasoning