
Watch#7: Small Tweaks with Big Impact
And how self-reflection can boost LLM training

Foreword:
The number of LLM papers published on arXiv is getting out of hand again. I will probably have to add more filters to my exploration approach in order to keep up with it in the future. A picture is worth a thousand words.
Have a great day all,
Pascal

Want to support me going professional as a content creator? Pledge now for future additional content. Your pledge will help me plan ahead and improve my content.
In this issue:
Autonomous self-improvers
𝘏𝘺𝘱𝘦𝘳 𝘏𝘺𝘱𝘦𝘳𝘈𝘵𝘵𝘦𝘯𝘵𝘪𝘰𝘯
𝘐𝘴 𝘵𝘩𝘪𝘴… 𝘢 𝘧𝘳𝘦𝘦 𝘭𝘶𝘯𝘤𝘩?
1. Reflection-Tuning: Data Recycling Improves LLM Instruction-Tuning
Watching: Reflection-Tuning (paper/code)
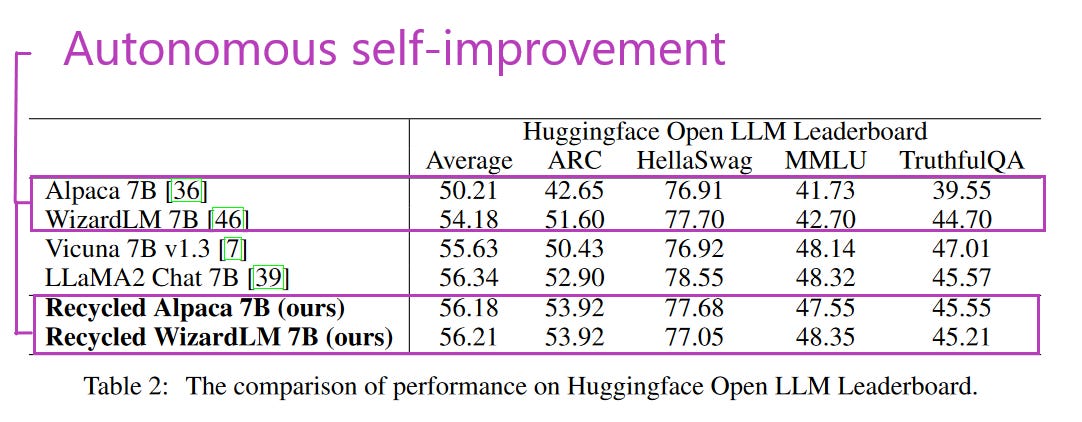
What problem does it solve? Instruction tuning, the prevalent method used in finetuning generative Large Language Models (LLMs), is reliant on the quality of instruction examples given. Unfortunately, such examples are often quite lengthy and sometimes non-trivial. This can massively increase the cost of both annotating and/or creating such datasets. For this reason, a lot of researchers have been exploring the use of synthetic data, sometimes utilizing datasets that have been generated entirely.
How does it solve the problem? Reflection-tuning draws on the evaluation and self-assessment capabilities of LLMs. Unlike previous self-alignment and self-enhancement methods, reflection-tunig does not only enhance the outputs of a model but also the inputs. Different criteria are used for input and output enhancement. For the instruction inputs, the model is guided by the following criteria: “the Complexity of the Topic”, “the Level of Detail Required for response”, “Knowledge Required for response”, “the Ambiguity of the Instruction” and whether “Logical Reasoning or Problem-Solving Involved”. For the outputs, “Helpfulness”, “Relevance”, “Accuracy”, and “Level of Details” are used.
What’s next? As most studies these days, the researchers started to evaluate their method on small LLMs in the 7B parameter category. Quite a few techniques have shown to asymmetrically help smaller models more than the larger ones. But if the ~10% performance boost from reflection-tuning could translate to something of the size of GPT4 - which I personally do not expect - then that would huge.
2. HyperAttention: Long-context Attention in Near-Linear Time
Watching: HypterAttention (paper)
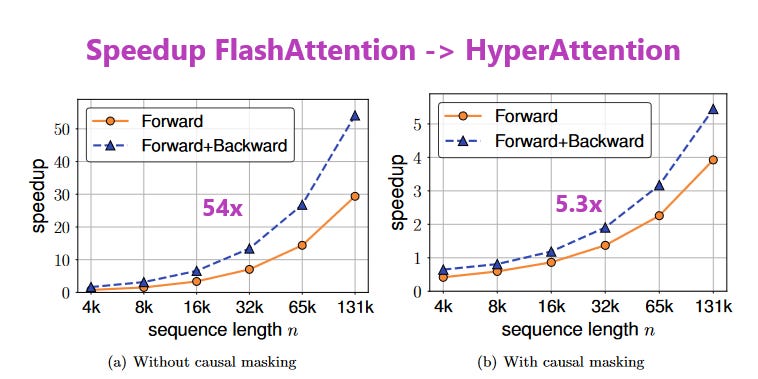
What problem does it solve? One of the main building blocks of Large Language Models (LLMs) and more generally, Transformers, is the attention mechanism. For a basic introduction to how attention works, I can recommend this popular article that explains self-attention in Vanilla Transformers. While the mechanisms has proven to perform well and be somewhat reasonable in terms of compute, it’s still far from optimal. There has been ongoing work on inventing more efficient implementations, such as the popular FlashAttention.
How does it solve the problem? HyperAttention utilizes Locality Sensitive Hashing (LSH) to identify large input examples. LSH can be used to sort keys and queries within an attention layer in a way that is much more aligned with the parallel computing paradigm of GPUs. More specifically, large inputs get shifted towards the diagonal of the attention matrix, which results in equal-sized attention blocks along the diagonal. The potential speed ups from HyperAttention vary quite a bit between models that utilize causal masking and those that don’t. Taking a look at the chart above, we can also see that HyperAttention mostly pays off in the long context domain (64k+ tokens) beyond what most popular vendors are currently offering (16-32k tokens).
What’s next? There are two scenarios that are very likely in my opinion: context lengths will most likely keep increasing fruther and - just like previous implementations of attention - HyperAttention will probably get even better with time. The real question is if there will be enough use cases for these very long contexts that seem to massively benefit from this new method.
3. NEFTune: Noisy Embeddings Improve Instruction Finetuning
Watching: NEFTune (paper/HF implementation/picture source)

What problem does it solve? Unstructured data tends to have a lot of variation in it and covering the full range of possible inputs in quality and quantity is often not feasible. Data Augmentation can help to the improve robustness of models trained on such data and generative models, particularily LLMs, are not only lowering the threshold for data augmentation at scale, they can also benefit from augmentation themselves.
How does it solve the problem? They say there are no free lunches. But apparently, there are? Similar to how two weeks ago, we saw a few semantically irrelevant tokens help LLMs keep their focus, NEFTune simply adds noise to the embedding vectors during training. The main difference to previous work is that NEFTune is adding noise on the embedding- and not sentence- or gradient-level.
What’s next? HuggingFace already implemented the method in their Transformer Reinforcement Learning (TRL) library and we might actually see this becoming a new baseline. It’s kind of exciting to see these seemingly small tricks like NEFTune and Attention Sinks still popping up after years of research on Transformers and modern Deep Learning in general. It goes to show that there’s much more left to explore in terms of this technology.
Papers of the Week:
Creating specialized tools and then retrieving them on demand
MetaTool: to use or not to use a tool - that is the question
Found in the Middle: Improving performance deficits of LLMs for long contexts
Have LLMs Advanced Enough? A Challenging Problem Solving Benchmark
FActScore: Fine-grained Evaluation of Factual Precision in Long Form Text Generation