
Watch#10: Knowledge Cut-Off? No problem, take my Knowledge Card
Knowledge-to-go for your LoRA army
In this issue:
1000 Models fit into a single A100
Finally: AI can generate text in images?
Plug-n-Play knowledge modules for your LLMs
Want to support me going professional as a content creator? Pledge now for future additional content. Your pledge will help me plan ahead and improve my content.
1. S-LoRA: Serving Thousands of Concurrent LoRA Adapters
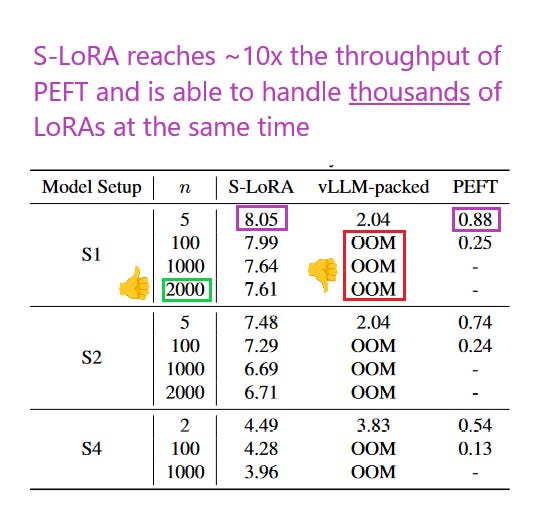
What problem does it solve? The prevalent "pretrain-then-finetune" approach for deploying large language models (LLMs) often leads to numerous LoRA (Low-Rank Adaptation) adapters being derived from a single base model. This multiplicity of adapters presents a unique challenge in efficiently serving them, especially in terms of memory usage and computational efficiency. Managing and serving these numerous adapters effectively without compromising performance or increasing hardware requirements is a significant problem in practical LLM applications.
How does it solve the problem? S-LoRA, the system introduced in the paper, addresses this challenge by storing all LoRA adapters in the main memory, while dynamically fetching the required adapters to the GPU memory for active queries. This approach is made efficient through the novel concept of Unified Paging, which manages a unified memory pool to handle adapter weights and KV cache tensors of varying sizes and ranks. This system not only maximizes GPU memory utilization but also minimizes fragmentation. Moreover, S-LoRA's implementation includes custom CUDA kernels and a unique tensor parallelism strategy, allowing for heterogeneous batching of computations across different LoRA adapters.
What’s next? The introduction of S-LoRA marks a significant advancement in the scalable deployment of LLMs with numerous adapters. Looking forward, the next steps could involve further optimization of this system for even larger-scale models and more complex deployment scenarios. Additionally, the principles and techniques developed in S-LoRA could inspire similar solutions in other areas of machine learning where dynamic memory management and efficient computation are critical. As the field of LLMs continues to evolve, systems like S-LoRA will be crucial in bridging the gap between advanced research models and their practical, real-world applications.
2. AnyText: Multilingual Visual Text Generation And Editing
Watching: AnyText (paper)

What problem does it solve? The integration of text into synthesized images has been a persistent challenge in diffusion model-based Text-to-Image generation. Current technologies, while adept at generating high-quality images, often struggle with accurately rendering text, particularly in multilingual contexts. This leads to images where the text appears unnatural or out of place, detracting from the overall fidelity and coherence of the generated image.
How does it solve the problem? AnyText addresses this issue through a novel diffusion pipeline that includes an auxiliary latent module and a text embedding module. The auxiliary latent module generates latent features for text generation or editing using inputs like text glyph, position, and masked image. The text embedding module, on the other hand, employs an OCR model to encode stroke data as embeddings, which are then blended with image caption embeddings from the tokenizer. This approach allows for the generation of texts that seamlessly integrate with the background in multiple languages. Training enhancements like text-control diffusion loss and text perceptual loss further bolster writing accuracy.
What’s next? The introduction of AnyText is a significant step forward in multilingual visual text generation, a field that has not been extensively explored until now. With the ability to plug into existing diffusion models, AnyText broadens the scope for accurate text rendering in image synthesis. The development of the AnyWord-3M dataset and the AnyText-benchmark sets the stage for further advancements and evaluation in this domain. Future work could explore refining these techniques for even more nuanced text integration, potentially expanding into more complex and varied linguistic contexts.
3. Knowledge Card: Filling LLMs' Knowledge Gaps with Plug-in Specialized Language Models
Watching: Knowledge Cards (paper)
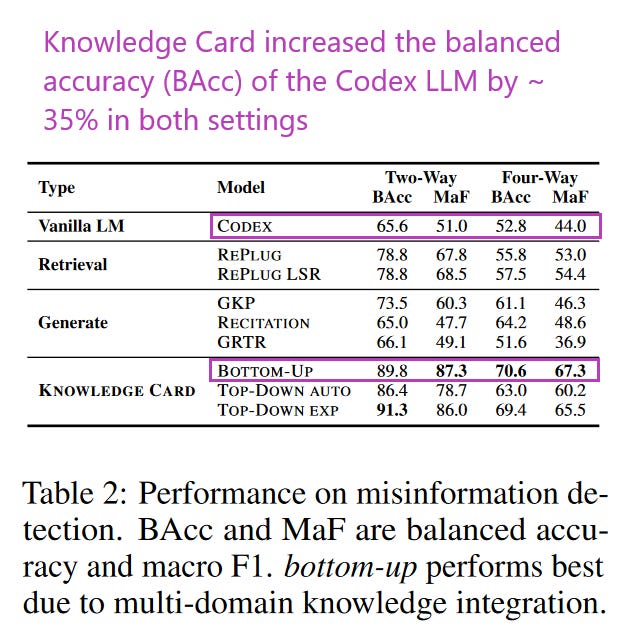
What problem does it solve? Large language models (LLMs), while powerful, face a significant challenge: they often fail to generate up-to-date, factual, and relevant knowledge due to their static nature and the high costs associated with frequent retraining or updating. This limitation is particularly problematic in knowledge-intensive tasks, where accuracy and currency of information are crucial. There's a growing need for a solution that allows LLMs to dynamically integrate fresh and accurate knowledge without the need for extensive retraining.
How does it solve the problem? The proposed framework addresses this issue innovatively. It introduces "knowledge cards," which are specialized language models trained on domain-specific corpora. These cards act as parametric knowledge repositories, selected during inference to provide the base LLM with accurate background knowledge. Additionally, it uses three content selectors to ensure the information provided by these knowledge cards is relevant, brief, and factual. By integrating these specialized models, the base LLM can dynamically synthesize and update knowledge from various domains, enhancing its performance on knowledge-intensive tasks.
What’s next? The modular design of knowledge cards sets the stage for continuous and collective updates to relevant knowledge by the research community. This approach not only promises improvements in the state-of-the-art performance of LLMs on benchmark datasets but also heralds a new era of collaborative and dynamic knowledge integration in language models. It will be fascinating to see how this framework evolves and what new capabilities it unlocks for LLMs in handling complex, evolving real-world information.
Papers of the Week:
FlashDecoding++: Faster Large Language Model Inference on GPUs
Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph
MarioGPT: Open-Ended Text2Level Generation through Large Language Models
Accuracy of a Vision-Language Model on Challenging Medical Cases