
Watch #4: Lack of Scientific Rigor, Ranking the Rankers and a Small Model with Big Results
This time from Europe of all places
Foreword:
We’re wrapping up the first month with this issue!
Let’s jump straight into it,
Pascal
In this issue:
Few months old European start-up delivering the best 7B model yet
Small Open Source models are all you need for Document Ranking
The Reversal Curse: between myth, ideology and facts
1. Mistral 7B: The best 7B model to date, Apache 2.0
Watching: Mistral 7B (blog/code)

What problem does it solve? GPT-4 ist still considered to be the best LLM overall. A lot of people are concerned about the recent trend of companies closing off their giant models, only sharing what they want the public to know. This basically adds a black box to a black box. Meta - formerly known as Facebook - is taking an opposing stance to OpenAI and tries to share their foundation models and advancements with the Open Source (OS) community. There’s hope that OS will catch up and make the coming generation of AI much more accessible and efficient - just as it did with the previous one.
How does it solve the problem? Smaller OS models are getting better and better. With Mistral 7B, we’re not only getting a new champion in this weight category, it’s also one of the first competitive models coming out of Europe. Mistral, the company behind it, has been making headlines earlier this year when they closed a $100m+ investment for their seed round. It’s good to see the ecosystem grow and diversify.
What’s next? Mistral 7B was only their debut, a teaser of what to expect from the team. They plan to release much larger models soon and if they live up to the performance of their 7B version, then things could get really exciting. Mistral could become one of the Top 5 foundation model companies not even a year after the company’s founding.
2. RankVicuna: Zero-Shot Listwise Document Reranking with Open-Source Large Language Models
Watching: RankVicuna (paper)
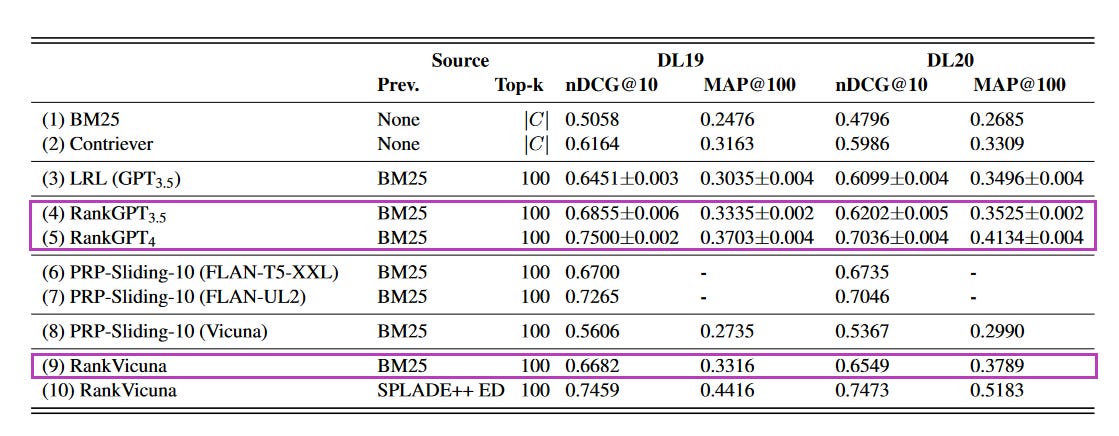
What problem does it solve? Ranking is one of the cornerstones of the modern internet. Google ranks pages, Amazon ranks products, Netflix ranks movies - basically, any company in the digital space is performing some kind of ranking at scale. One of the most important ranking tasks is Document Ranking. Because this technology is usually tied to search and other features that require low latency, the models used in production have to be rather small. LLMs like GPT-4 can be excellent rankers, but using them can get very costly under such latency requirements and often on-premise software is prefered for core business features.
How does it solve the problem? Not only is RankVicuna roughly 100x smaller than GPT-4 (and 25x smaller than GPT-3.5), it can also be deployed locally without too much of a hassle. As we can see in the chart above, RankVicuna even beat GPT-4 when combined with SPLADE++ ED, a BERT-based sparse retrieval model.
What’s next? Applications of LLMs on downstream tasks are always lagging behind by a bit. Vicuna isn’t the most performant Open Source (OS) model anymore and as we’ve discussed in the previous section, OS models are improving steadily while the big proprietary releases of companies such as OpenAI are happening at a much slower rate. Depending on when GPT-5 will be released and how much of an improvement it will be, certain downstream tasks could soon be overtaken by other models.
3. The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A"
Watching: LLM capabilities (paper)
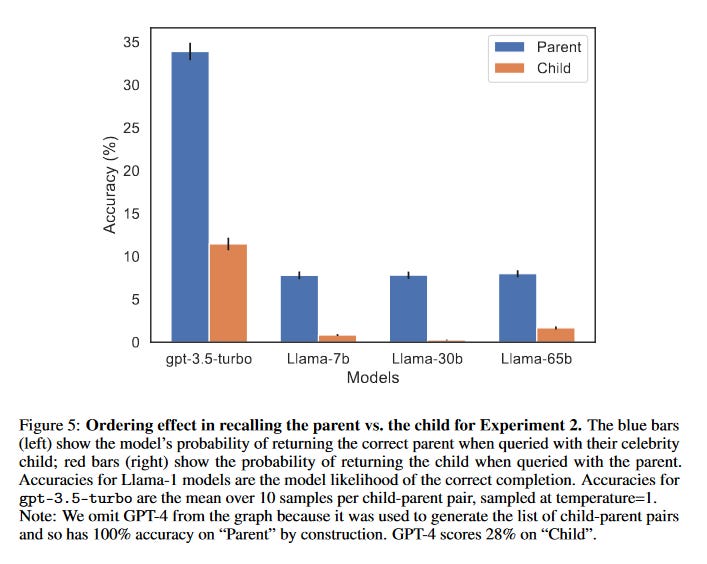
What problem does it solve? Ever since the release of GPT-3, discussions about emerging capabilities of Large Language Models (LLMs) have become more and more heated. Can LLMs understand? If yes, in what way? How robust is this understanding? If no, how can the unreasonable effectiveness of large Deep Learning (DL) models be explained then? When OpenAI released the paper “Sparks of General Artificial Intelligence”, the research community was split and the extremes on both sides are trying to profit off the hopes and fears of the audience.
How does it (not) solve the problem? For this reason, these discussions are often loaded with ideology and emotions. Solid research on this topic is rare, as companies such as OpenAI have little interest in communicating results in ways that potentially calm the hype and people that have made a living from criticizing Deep Learning will try to continue doing so. In times like these, any work that prioritizes scientific rigor helps to navigate all the noise. While the paper in discussion brings up some valuable directions, the team’s approach seemed to be highly unscientific from the start. They admit in their conclusion that “In this paper, we set out to prove a negative result” - a statement that is diametrically opposed to the fundamentals of Empirical Science.
What’s next? Their work is still under review and making simple changes like adding a control group to the experiments, balancing their prompts and re-thinking the strength of their claims would massively upgrade the study. The effect they found might be valid. But without solid experimentation, we can’t tell.
Papers of the Week:
Evaluating the robustness of LLMs to word-level perturbations
MindGPT: Interpreting What You See with Non-invasive Brain Recordings
Evaluation of human capabilities to detect AI-generated misinformation
DeepSpeed-VisualChat: Making multimodal multi-image dialogues feel seamless
ChatGPT-BCI: Word-Level Neural State Classification Using GPT, EEG, and Eye-Tracking Biomarkers