
🎧 Vibe Coding + Knowledge Graphs = 10x Cheaper
Better AI coding, better tool calling, better multimodal integration
In this issue:
Repository-level software engineering
Chain-of-Tools for better tool calling
The most complete AI model to date

1. Enhancing Repository-Level Software Repair via Repository-Aware Knowledge Graphs
Watching: KGCompass (paper)
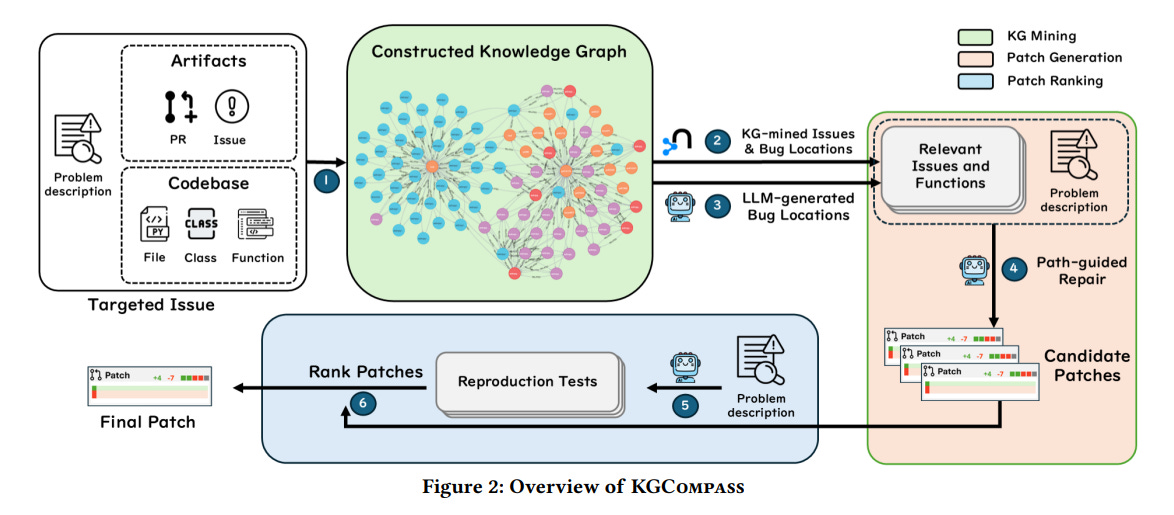
What problem does it solve? Large codebases are hard for AI to fix! When a bug report comes in, current LLM-based systems struggle to figure out which specific piece of code needs fixing among thousands of files and tens of thousands of functions. This paper identifies three key challenges: First, semantic ambiguity - when identical function names have different meanings in different contexts, LLMs get confused. Second, limited structural understanding - LLMs don't naturally connect issue descriptions with relevant code locations across the repository. Third, lack of interpretability - most AI repair systems work like black boxes, with no clear explanation for their decisions. Only 32% of bugs in their benchmark explicitly mention where the problem is, making bug localization a critical bottleneck in automated repair.
How does it solve the problem? The researchers created KGCompass, which introduces a clever "repository-aware knowledge graph" that acts like a map connecting issue reports to code locations. Instead of treating code and documentation as separate text chunks, their system builds a network of relationships between repository artifacts (issues, pull requests) and code entities (files, classes, functions). This graph can trace multi-hop connections, following chains like "issue → pull request → file → function" to identify the most likely bug locations. Using this knowledge graph, KGCompass narrows down the search space from thousands of functions to just 20 highly relevant candidates. Then, when generating patches, the system provides LLMs with these "entity paths" as context, helping them understand not just the code but the relationships between different repository components.
What are the key findings? KGCompass achieved state-of-the-art repair performance (45.67%) and function-level localization accuracy (51.33%) on the SWE-bench-Lite benchmark, while costing only $0.20 per repair - about 10x cheaper than competing approaches. Their most striking finding was that 69.7% of successfully fixed bugs required multi-hop traversals through the knowledge graph, revealing why traditional LLMs struggle with this task - they can't easily model these indirect relationships. The system significantly reduced the search space while maintaining high coverage of ground truth bug locations (84.3% file-level, 58.8% function-level). KGCompass uniquely fixed 19 bugs that no other open-source approach could handle and 11 bugs that even commercial solutions missed. Impressively, the approach worked well with different LLMs, including open-source models like Deepseek V3 and Qwen2.5 Max.
Why does it matter? By creating a structured representation of the connections between issues and code, KGCompass addresses a fundamental limitation in current approaches that rely solely on text understanding. The 10x cost reduction makes automated repair much more practical for real-world development teams, and the knowledge graph's interpretable nature increases trust by providing clear reasoning paths. Since the approach is language-agnostic and can be incrementally updated as code changes, it's highly adaptable to various programming languages and development workflows. Perhaps most importantly, by showing how properly structured knowledge can compensate for LLM limitations, this research opens the door to more accessible and effective software maintenance tools that can work with a wide range of models, not just the most expensive proprietary ones.
Caveat: There’s no repository yet and it’s unclear to me if they’ll release KGCompass to the public. However, if this approach will prove as promising as it sounds, someone will surely replicate it very soon.
2. Chain-of-Tools: Utilizing Massive Unseen Tools in the CoT Reasoning of Frozen Language Models
Watching: Chain-of-Tools (paper/code)
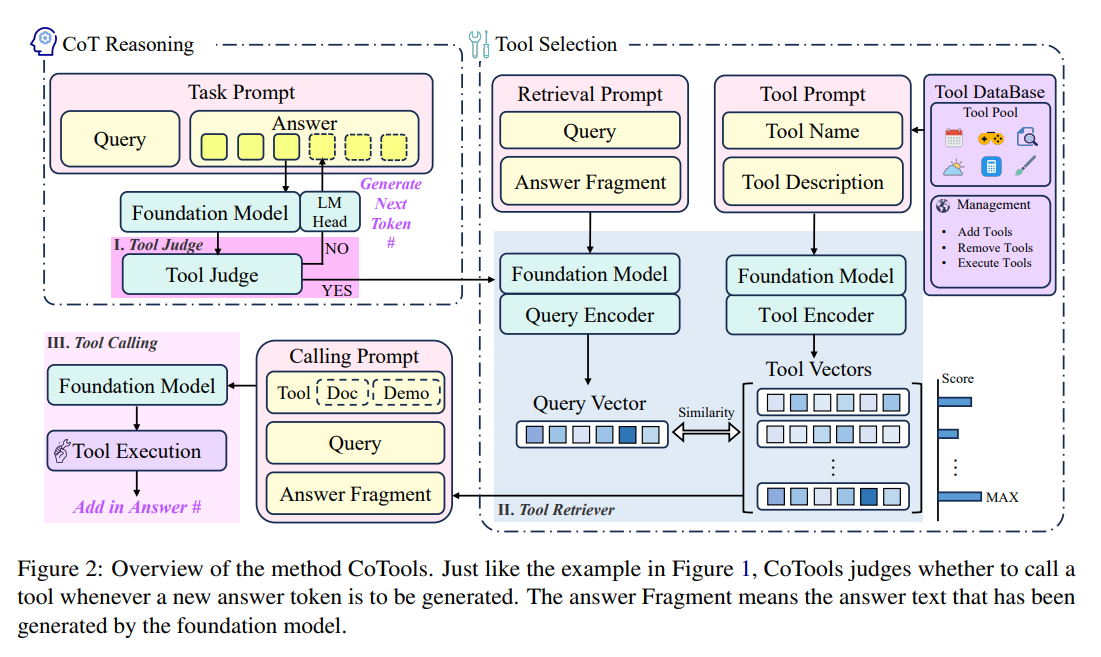
What problem does it solve? Current tool learning methods for Large Language Models (LLMs) face significant limitations. Fine-tuning approaches like ToolLLM restrict models to using only tools seen during training, while in-context learning methods like HuggingGPT become inefficient when dealing with many tools. This creates a challenging dilemma: either sacrifice flexibility (can't use new tools) or sacrifice efficiency (performance degrades with more tools). Real-world applications need LLMs that can efficiently reason with a massive, ever-growing toolkit, including tools they've never seen before, while maintaining their powerful reasoning abilities.
How does it solve the problem? Chain-of-Tools (CoTools) is a new method that keeps the foundation LLM completely frozen while adding specialized modules for tool integration. Their approach has three key components: 1) A Tool Judge that determines when to call tools during text generation by analyzing the hidden states of the LLM, 2) A Tool Retriever that selects appropriate tools by matching query vectors with tool vectors derived from tool descriptions, and 3) A Tool Calling component that handles parameter filling and execution. This design allows the model to maintain its original reasoning capabilities while efficiently incorporating new tools through their descriptions without requiring additional training.
What are the key findings? CoTools outperforms baseline methods across multiple benchmarks, with particularly impressive results on the newly created SimpleToolQuestions dataset containing 1,836 tools (999 seen and 837 unseen). The method maintained high performance even with hundreds or thousands of tools, showing 10-20% better accuracy than the ToolkenGPT baseline. For unseen tools specifically, CoTools achieved 10.4% top-1 accuracy and 33.7% top-5 accuracy, while the baseline couldn't handle unseen tools at all (0% accuracy). The authors also identified specific dimensions in the LLM's hidden states that play crucial roles in tool selection, enhancing model interpretability.
Why does it matter? By enabling efficient use of massive tool libraries including unseen tools, CoTools bridges a critical gap between theoretical capabilities and practical applications. This approach allows for "plug-and-play" tool integration without compromising reasoning abilities or requiring expensive retraining. As new tools emerge daily in real-world scenarios, the ability to dynamically incorporate them is invaluable. Additionally, the insights into which hidden state dimensions influence tool selection improve our understanding of how LLMs make decisions, potentially leading to further improvements in tool learning systems.
3. Qwen2.5-Omni Technical Report
Watching: Qwen2.5-Omni (paper/code)

What problem does it solve? Current AI systems typically specialize in either understanding or generating specific modalities (text, images, audio, or video), but struggle to seamlessly integrate multiple input and output formats in real-time. This paper addresses the challenge of creating a unified multimodal system that can simultaneously perceive diverse inputs (text, images, audio, and video) while generating both text and speech responses in a streaming manner. The researchers identified three key challenges: synchronizing temporal aspects of multimodal inputs (especially audio-video alignment), preventing interference between different output modalities, and designing architectures that support real-time understanding and response with minimal latency.
How does it solve the problem? The authors introduced a novel architecture called "Thinker-Talker," reminiscent of how humans use different organs to produce various signals simultaneously while coordinating them through the same neural networks. The "Thinker" functions like a brain, handling perception and text generation, while the "Talker" operates like a mouth, converting high-level representations into speech. To synchronize audio and video inputs, they developed TMRoPE (Time-aligned Multimodal RoPE), a position embedding approach that explicitly incorporates temporal information to align the modalities. For streaming capabilities, they modified encoders to support block-wise processing and implemented a sliding-window attention mechanism in the speech generation component, significantly reducing initial latency and enabling real-time interactions.
What are the key findings? Qwen2.5-Omni demonstrates performance comparable to similarly sized single-modality models in their respective domains while excelling at multimodal tasks. It achieved state-of-the-art results on multimodal benchmarks like OmniBench (56.13%) and performed strongly on vision tasks like MMMU and MMBench. Notably, its performance on speech instruction following nearly matches its text input capabilities, closing a gap that existed in previous systems. For speech generation, it achieved impressive word error rates (1.42%, 2.33%, and 6.54% on different test sets), outperforming many specialized streaming and non-streaming speech synthesis systems in both robustness and naturalness.
Why does it matter? This represents a significant step toward more general AI systems that can interact with the world in ways similar to humans - perceiving multiple streams of information simultaneously and responding through different channels. By unifying multiple modalities in a single model with streaming capabilities, Qwen2.5-Omni bridges the gap between specialized systems and demonstrates that we can build AI that processes information more holistically without compromising performance. This approach could fundamentally improve human-computer interaction by enabling more natural, responsive, and context-aware AI assistants that can smoothly transition between different modalities. The streaming architecture also makes these capabilities practical for real-world applications where latency is crucial.
Papers of the Week:
Current and Future Use of Large Language Models for Knowledge Work:
LLMs enable knowledge workers to use natural language for task automation (code generation, text improvement), boosting productivity via workflow integration. A systematic study using survey data explores current and future LLM usage, discussing implications for generative AI technologies' adoption. LLMs mark a paradigm shift in AI interaction.
WindowKV: Task-Adaptive Group-Wise KV Cache Window Selection for Efficient LLM Inference:
WindowKV optimizes long-context LLM inference by addressing semantic coherence and task-specific characteristics in KV cache compression, crucial for reducing GPU memory usage. It uses task-adaptive window selection and intra-group layer sharing. On LongBench, WindowKV achieves comparable performance to full KV retention using 12% of the original KV cache and excels in Needle-in-a-Haystack evaluations.
REALM: A Dataset of Real-World LLM Use Cases:
LLMs (e.g., GPT series) drive industry/economic shifts, but impacts are unclear. REALM, a dataset of 94,000 use cases from Reddit/news articles, catalogs applications, user demographics, and societal roles. It categorizes applications, exploring links between user occupations and LLM use. A dedicated dashboard presents the data, facilitating research on LLM adoption.
ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning:
LLMs struggle with external search for multi-hop questions. ReSearch uses reinforcement learning to train LLMs, integrating search operations into the reasoning chain, guided by text-based thinking. Trained on Qwen2.5-7B and Qwen2.5-32B, ReSearch shows generalizability, eliciting reflection and self-correction during learning.
MARS: Memory-Enhanced Agents with Reflective Self-improvement:
The Memory-Enhanced Agents with Reflective Self-improvement framework addresses LLM limitations—poor decision-making, short context windows in dynamic environments, and absent long-term memory—using three agents: User, Assistant, and Checker. Utilizing iterative feedback and a memory optimization mechanism based on the Ebbinghaus forgetting curve, it enhances multi-tasking and long-span information handling.
Enhancing the Robustness of LLM-Generated Code: Empirical Study and Framework:
LLM code lacks robustness: missing input validation, error handling, and conditional checks (low 'if' token probabilities). RobGen, employing model-agnostic techniques (RobGen-Adj and RobGen-Ins), enhances code quality without retraining. RobGen-Adj adjusts token probabilities; RobGen-Ins inserts missing conditionals, improving the dependability of generated code and mitigating robustness problems.
MemInsight: Autonomous Memory Augmentation for LLM Agents:
MemInsight, an autonomous memory augmentation method, enhances LLM agents' semantic data handling and long-term memory for better contextual responses in conversational recommendation, question answering, and event summarization. It boosts persuasiveness by 14% on LLM-REDIAL and outperforms a RAG baseline by 34% in recall for LoCoMo retrieval.
ResearchBench: Benchmarking LLMs in Scientific Discovery via Inspiration-Based Task Decomposition:
LLMs can assist scientific research, but their hypothesis discovery ability lacks evaluation. This article introduces a scientific discovery benchmark for LLMs, evaluating sub-tasks like inspiration retrieval and hypothesis composition via an automated framework with expert validation, using 2024 papers to prevent data contamination. LLMs excel at inspiration retrieval, positioning them as "research hypothesis mines" for automated scientific discovery.