
🐋 This AI Makes Big Tech Panic
DeepSeek-R1 is a massive win for open source AI
In this issue:
Re-defining what’s possible in AI
DeepMind going even deeper
Self-training agents are coming

1. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Watching: DeepSeek-R1 (paper/reference for this week’s headline)

What problem does it solve? Large Language Models (LLMs) tend to fall short in their reasoning abilities, especially in STEM-related questions and complex problem-solving scenarios. Traditional approaches heavily rely on supervised fine-tuning (SFT), which might limit the model's ability to develop novel reasoning strategies.
How does it solve the problem? DeepSeek introduces two models: R1-Zero, trained purely through reinforcement learning without prior SFT, and R1, which combines multi-stage training with cold-start data before RL. This approach leads to emergent reasoning behaviors and particularly strong performance in STEM subjects, mathematical reasoning, and coding tasks. The R1 model achieves performance comparable to OpenAI's latest models while addressing the limitations of R1-Zero such as poor readability and language mixing.
What are the key findings? R1 achieved performance comparable to OpenAI-o1-1217 on reasoning tasks and showed superior performance on various benchmarks including MMLU, MMLU-Pro, and GPQA Diamond, particularly in STEM-related questions. The model also demonstrated strong capabilities in document analysis, fact-based queries, and math tasks, while maintaining concise outputs without length bias.
Why is this important? These findings are a huge deal because they demonstrate that reinforcement learning alone can produce models with strong reasoning capabilities, challenging the conventional wisdom that supervised fine-tuning is necessary. This opens new possibilities for training LLMs and suggests that focused RL training can lead to better performance across diverse domains while potentially reducing the need for extensive supervised datasets.
Bonus: I published an introductory overview of their paper earlier this week.
2. Evolving Deeper LLM Thinking
Watching: Mind Evolution (paper)
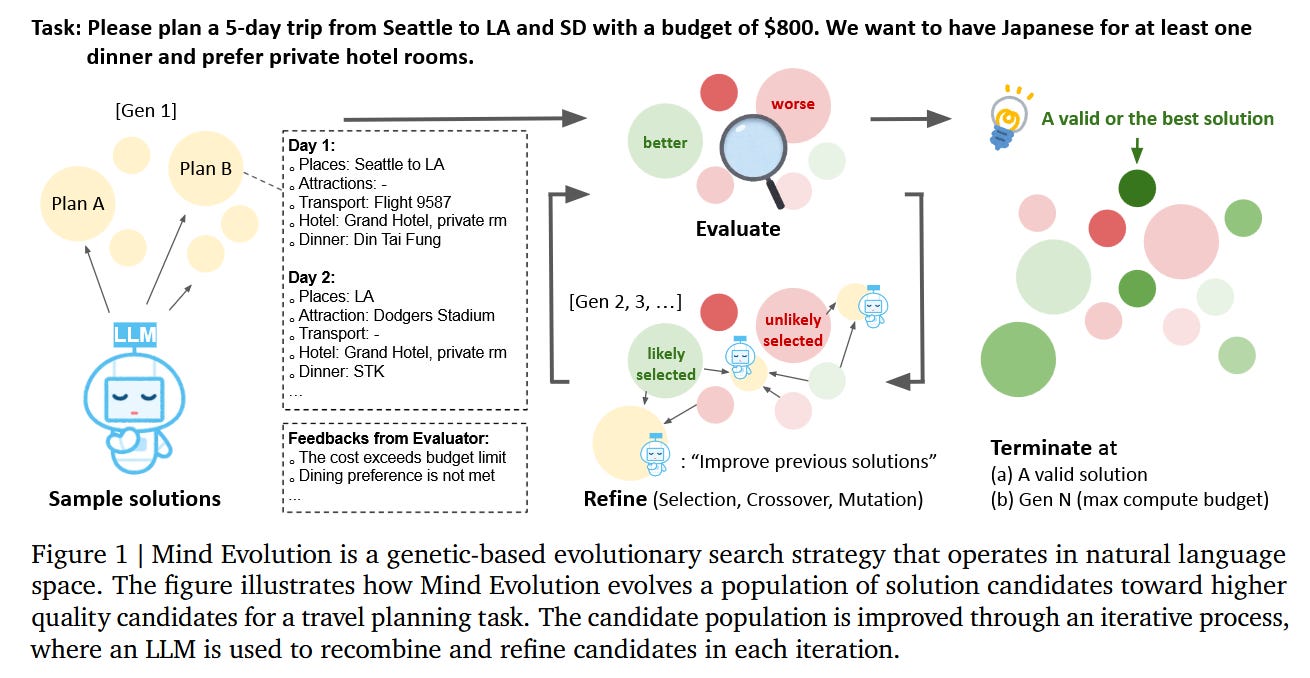
What problem does it solve? Finding the optimal solution in a Large Language Model’s (LLM’s) output space often requires significant computational resources and time. Traditional approaches like Best-of-N sampling or Sequential Revision may not always yield the best results efficiently. Mind Evolution aims to address this challenge by introducing an evolutionary search strategy that scales inference time compute in LLMs more effectively.
How does it solve the problem? Mind Evolution leverages the generative capabilities of LLMs to create, combine, and refine candidate responses iteratively. The approach starts by generating an initial population of candidate solutions using the LLM. These candidates are then evaluated using a solution evaluator, which assesses their quality without the need to formalize the underlying inference problem. The best-performing candidates are selected and undergo recombination and refinement processes, where the LLM generates new candidates by combining and improving upon the selected ones. This evolutionary cycle continues until a satisfactory solution is found or a computational budget is exhausted.
What are the key findings? Their approach significantly outperforms other inference strategies such as Best-of-N and Sequential Revision in natural language planning tasks, controlling for inference cost. In the TravelPlanner and Natural Plan benchmarks, Mind Evolution solves more than 98% of the problem instances using Gemini 1.5 Pro without the use of a formal solver.
Why is this important? This demonstrates that a more efficient and flexible approach to complex problem-solving with LLMs is possible. By eliminating the need for formal problem specifications while maintaining high performance, Mind Evolution could make LLMs more practical and effective for real-world planning and problem-solving applications.
3. Agent-R: Training Language Model Agents to Reflect via Iterative Self-Training
Watching: Agent-R (paper/code)

What problem does it solve? LLM agents often struggle with error recovery in interactive environments. While behavior cloning from expert demonstrations can help improve performance, it doesn't adequately prepare agents for handling mistakes in real-world scenarios. Creating step-by-step critique data manually would be extremely costly and time-consuming, so there's a need for automated self-improvement mechanisms.
How does it solve the problem? Agent-R introduces an innovative self-training framework that uses Monte Carlo Tree Search (MCTS) to generate training data focused on error recovery. Instead of waiting until the end of a task to evaluate success, the system identifies errors as they occur and splices in correct alternative paths from the same decision point. This creates a dynamic learning environment where the agent learns to recognize and correct mistakes based on its current capabilities, leading to more efficient learning and better error recovery.
What are the key findings? The results show that Agent-R successfully improves agents' ability to recover from errors and enables timely error correction. In experiments across three interactive environments, Agent-R outperformed baseline methods by 5.59%, demonstrating effective error correction while avoiding loops.
Why is this important? They present a solution to one of the major challenges in LLM agents: the ability to autonomously recover from errors without requiring expensive human-annotated critique data. This advancement is crucial for deploying LLM agents in real-world applications where error recovery is essential for reliable performance.
Papers of the Week:
AirRAG: Activating Intrinsic Reasoning for Retrieval Augmented Generation via Tree-based Search
FRAG: A Flexible Modular Framework for Retrieval-Augmented Generation based on Knowledge Graphs
Accelerating Large Language Models through Partially Linear Feed-Forward Network
CDW-CoT: Clustered Distance-Weighted Chain-of-Thoughts Reasoning
Integrate Temporal Graph Learning into LLM-based Temporal Knowledge Graph Model
From Drafts to Answers: Unlocking LLM Potential via Aggregation Fine-Tuning
A Survey on Memory-Efficient Large-Scale Model Training in AI for Science
Advancing Language Model Reasoning through Reinforcement Learning and Inference Scaling
PIKE-RAG: sPecIalized KnowledgE and Rationale Augmented Generation