
ThinkPRM: More Than Just Chain-of-Thought (CoT 2.0)
AI models that verify reasoning steps with Advanced Chain-of-Thought

As Artificial Intelligence (AI) advances, large language models (LLMs) like ChatGPT and Claude have become increasingly capable of solving complex problems through step-by-step reasoning. But their solutions are only as valuable as they are accurate. The ThinkPRM paper introduces a breakthrough approach to efficiently verify AI reasoning processes. This addresses a critical challenge in AI: how to reliably check if an AI's step-by-step reasoning is correct without requiring enormous amounts of human-labeled data.
Why Verification Is Hard
When an LLM solves a complex math problem or writes computer code, it produces a chain of reasoning steps. Ensuring these steps are correct is crucial for applications in education, scientific research, and critical decision-making. The traditional approach to this verification relies on process reward models (PRMs) – specialized AI systems that score each step in a solution.Until now, there have been two main verification approaches:
Discriminative PRMs: These models classify each reasoning step as correct or incorrect. They're effective but require massive datasets with step-by-step human annotations – often hundreds of thousands of labeled examples. Creating this data is time-consuming and expensive.
LLM-as-a-Judge: This approach prompts an existing LLM to evaluate solutions without additional training. While convenient, these models often struggle with complex reasoning tasks and can produce unreliable results. They frequently suffer from problems like "overthinking" (generating excessively long verifications) or getting stuck in repetitive loops.
Despite advances in both approaches, verification systems face persistent challenges. Discriminative PRMs depend on extensive labeled data that's costly to create, while LLM-as-a-Judge approaches often make errors in complex reasoning scenarios and struggle with consistency. These limitations have constrained progress in developing reliable verification systems that can handle sophisticated reasoning tasks efficiently.
ThinkPRM: A Potential Breakthrough
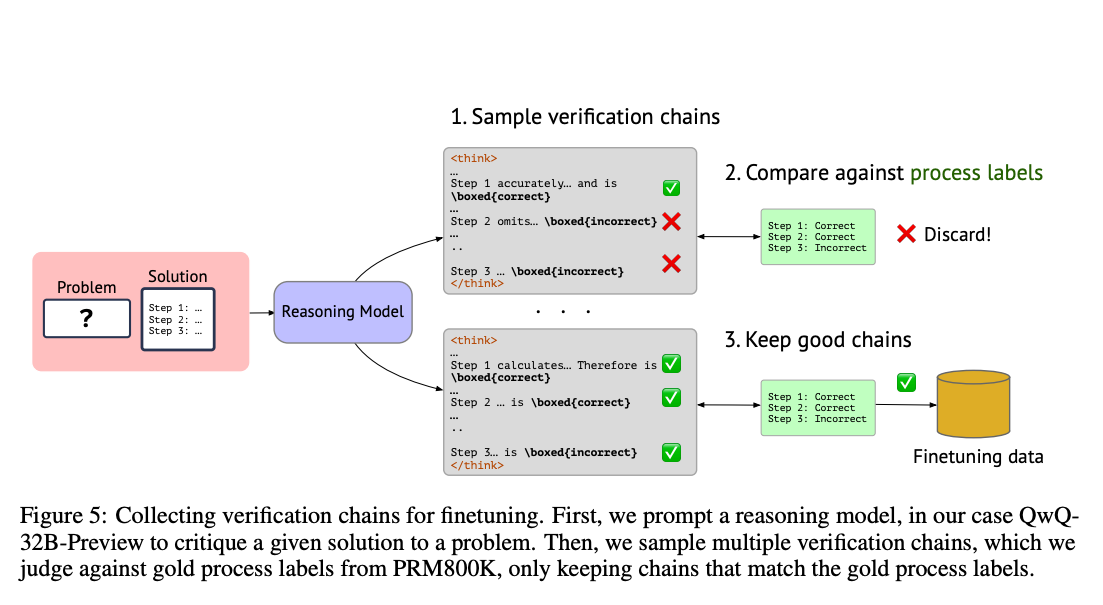
ThinkPRM (Process Reward Models That Think) is a new approach that fundamentally reimagines verification as a generative, reasoning-based task rather than a simple classification problem.
It works by leveraging the inherent reasoning abilities of language models to verify reasoning. Instead of merely classifying steps as correct or incorrect, it "thinks through" each step, generating detailed verification chains-of-thought (CoT) that explain why a step is right or wrong.Here's the innovative process:
Foundation: The researchers start with open-source reasoning models like R1-Distill-Qwen.
Synthetic Data Generation: Rather than requiring extensive human annotations, they prompt a larger language model (QwQ-32B-Preview) to generate verification chains for a sample of problem solutions.
Quality Filtering: They only keep verification chains that match known step-level labels, ensuring high-quality training data.
Lightweight Training: The model is fine-tuned on this small but high-quality dataset – just 1,000 carefully filtered examples (representing about 8,000 step-level annotations).
The result is a model that can carefully analyze each step in a solution, explaining its reasoning process and providing a judgment about correctness. Here's an abbreviated example of ThinkPRM verifying a math problem solution:

This "thinking" process provides transparency into the verification, making it easier to understand why a particular step is judged correct or incorrect.
Multi-Agent Failure: What It Is and How to Prevent It

Multi-Agent Systems built using Large Language Models (LLMs) have emerged as a promising approach to complex problem-solving. By orchestrating multiple specialized agents working in concert, these systems aim to accomplish tasks that might be challenging for a single agent. However, despite growing enthusiasm and investment in these Multi-Agent LLM Systems (MAS), research reveals that their performance often falls short of expectations.
Convincing Results
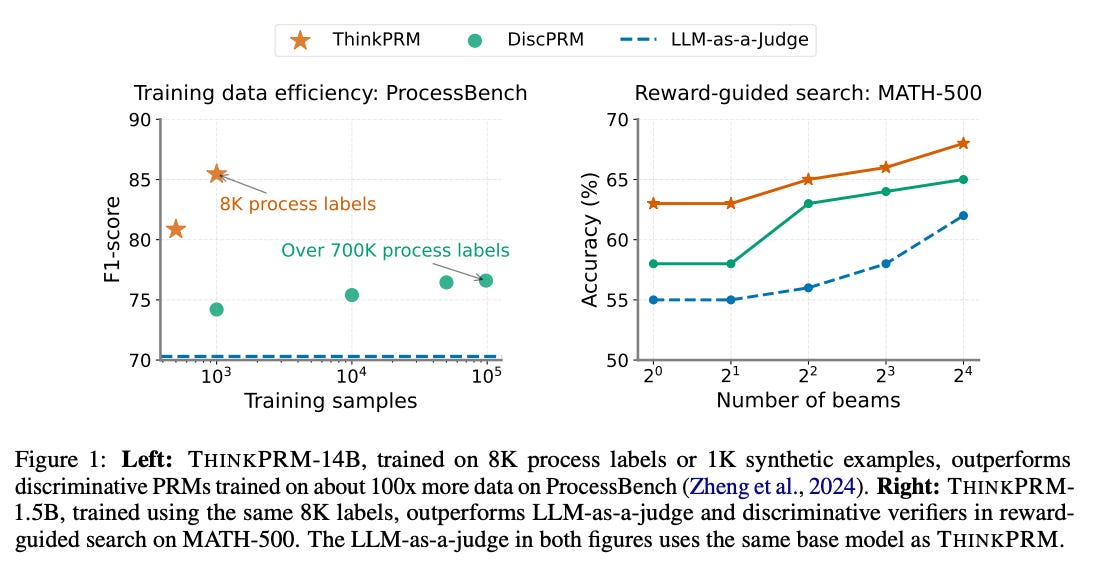
ThinkPRM achieves exceptional performance while using drastically less training data:
1. Data Efficiency
Perhaps the most striking finding is that ThinkPRM performs better than discriminative PRMs trained on 100 times more data. While traditional models required 700,000+ step-level annotations, the method achieves superior results with just 8,000 annotations.
2. Superior Performance
ThinkPRM outperforms both discriminative PRMs and LLM-as-a-judge approaches across multiple challenging benchmarks:
On ProcessBench (a benchmark for identifying reasoning errors), ThinkPRM-14B achieves 86.5% F1 score compared to 73.7% for the LLM-as-a-judge approach using the same base model.
When used to guide search processes in solving MATH-500 problems, ThinkPRM-1.5B outperforms discriminative PRMs by approximately 5 percentage points.
3. Generalization to New Domains
Despite being trained only on math problems, ThinkPRM demonstrates remarkable generalization to entirely different domains:
On physics questions from GPQA-Diamond, ThinkPRM outperforms discriminative PRMs by 8 percentage points.
On code generation tasks from LiveCodeBench, it achieves a 4.5% advantage.
This ability to generalize suggests that ThinkPRM is learning fundamental reasoning verification skills rather than domain-specific patterns.
4. Scalable Verification
A unique advantage of ThinkPRM is its ability to scale verification compute in two ways:
Parallel Scaling: Sampling multiple verification chains independently and aggregating their decisions improves accuracy by ~5 percentage points.
Sequential Scaling: The model can "think longer" by extending its verification process, checking and revising its initial judgment. This capability allows ThinkPRM to continue improving as it's given more computation time.
How This Changes AI Verification
ThinkPRM represents a fundamental shift in how we approach verification of complex reasoning:
From Classification to Reasoning
Traditional PRMs treat verification as a classification task – binary decisions about step correctness. ThinkPRM reframes verification as a reasoning task, where a model must think through and justify its evaluation. This approach is not just more data-efficient but also more aligned with how humans verify reasoning.
Transparency and Interpretability
Unlike black-box discriminative models, ThinkPRM's verification process is fully transparent. Users can read the model's verification chain to understand why it judged a step correct or incorrect. This transparency is crucial for applications where understanding the rationale behind verification decisions matters.
Low-Resource Adaptation
The remarkable data efficiency of ThinkPRM opens possibilities for creating specialized verifiers for niche domains where extensive labeled data is unavailable. This could democratize access to high-quality verification systems across diverse fields of expertise.
Challenges and Limitations
Despite its improvements, ThinkPRM still faces challenges:
Calibration: Like many LLMs, ThinkPRM can be overconfident, with scores clustering at extremes (near 0 or 1) rather than expressing appropriate uncertainty.
Step Label Interference: Errors in verifying earlier steps can cascade, influencing the verification of later steps in the solution.
Computational Overhead: Generating detailed verification chains requires more computation than simple discriminative judgments, though the performance benefits often justify this cost.
The Broader Significance
ThinkPRM demonstrates a powerful principle: models can "think to verify" rather than simply "classify to verify." This represents a move toward more human-like verification systems that reason through solutions rather than making opaque judgments.The implications extend beyond academic research. As AI systems take on increasingly complex reasoning tasks in healthcare, scientific research, and critical infrastructure, reliable verification becomes essential. ThinkPRM's approach offers a path toward more trustworthy AI systems that can not only reason but also rigorously verify their reasoning processes.
Looking Forward
The ThinkPRM approach opens several exciting research directions:
Cross-domain verification: Further exploring how these models can generalize across different domains and types of reasoning tasks.
Interactive verification: Developing systems that can ask clarifying questions when verification is uncertain.
Self-correction: Using verification feedback to improve initial reasoning processes in a closed loop.
Human-AI collaboration: Creating verification systems that can effectively collaborate with humans in complex reasoning tasks.
Conclusion
ThinkPRM represents a significant advancement in AI verification technology, demonstrating that process reward models can achieve superior performance with dramatically less training data by leveraging generative, chain-of-thought reasoning. This "thinking verifier" approach aligns more closely with human verification practices and offers greater transparency into the verification process.
As AI systems tackle increasingly complex reasoning challenges, the ability to efficiently and reliably verify their work becomes ever more crucial. ThinkPRM shows that by teaching verification models to think through their judgments step by step, we can create more efficient, effective, and transparent verification systems – an essential step toward more trustworthy artificial intelligence.