
These Are the Papers You Should Know About
Get ahead of the curve with LLM Watch

Fastest way to become an AI Engineer? Building things yourself!
Get hands-on experience with Towards AI’s industry-focused course: From Beginner to Advanced LLM Developer (≈90 lessons). Built by frustrated ex-PhDs & builders for real-world impact.
Build production-ready apps: RAG, fine-tuning, agents
Guidance: Instructor support on Discord
Prereq: Basic Python
Outcome: Ship a certified product
Guaranteed value: 30-day money-back guarantee
Pro tip: Both this course and LLM Watch might be eligible for your company’s learning & development budget.
Depth Anything 3: Recovering the Visual Space from Any Views (paper)
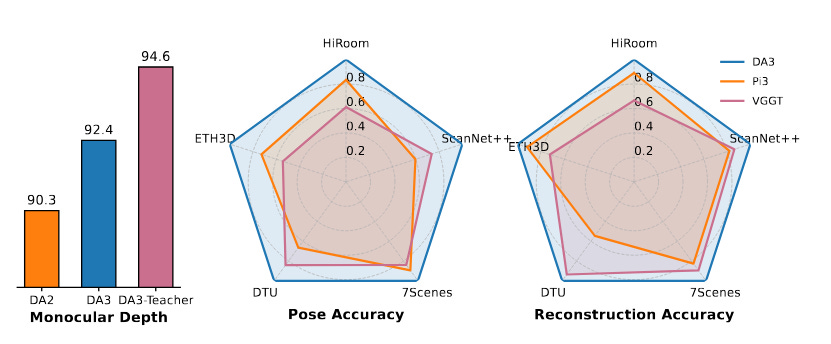
Depth Anything 3 (DA3) introduces a streamlined approach for multi-view 3D geometry estimation. It can predict spatially consistent depth and scene structure from an arbitrary number of input images, even without known camera poses. Instead of complex multi-task frameworks or specialized architectures, DA3 uses a single plain transformer backbone (e.g. a vanilla DINOv2 encoder) and a unified depth-ray prediction scheme. This minimalist design is trained in a teacher-student paradigm, achieving detail and generalization on par with its predecessor (Depth Anything 2) despite the simpler architecture.
State-of-the-art performance: DA3 establishes a new visual geometry benchmark (covering camera pose estimation, any-view geometry, and rendering) and outperforms prior methods by a large margin. For example, it improves camera pose accuracy by ~44% and geometric accuracy by ~25% over the previous SOTA model (VGGT). It even surpasses DA2 on monocular depth estimation, setting new state-of-the-art results across all tasks.
AgentEvolver: Towards Efficient Self-Evolving Agent System (paper/code)
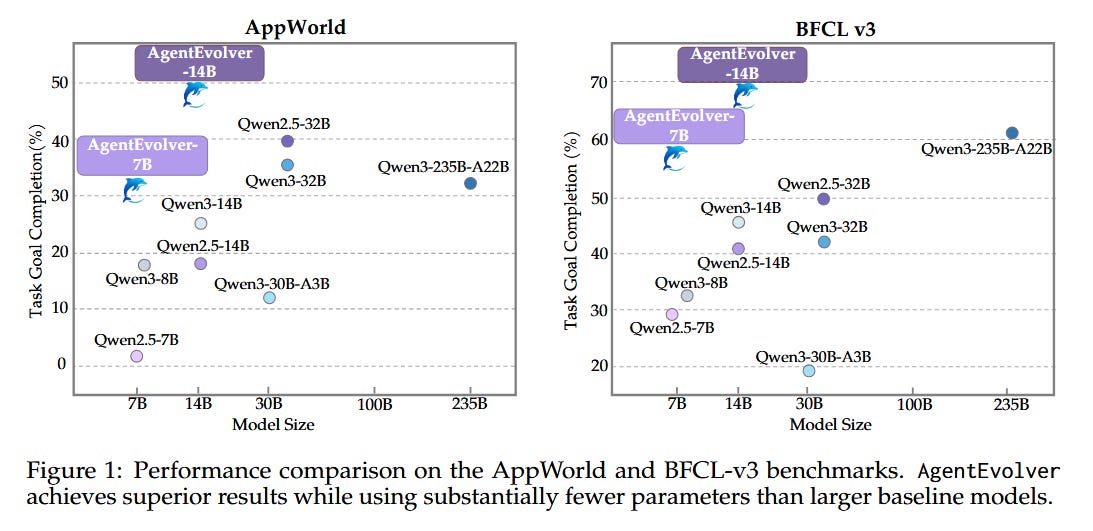
AgentEvolver proposes a self-evolving framework for autonomous agents built on large language models (LLMs), aiming to reduce the high costs and inefficiencies of current agent training. It leverages the reasoning ability of LLMs to generate and refine its own tasks and learning signals, rather than relying solely on hand-crafted task datasets and brute-force RL exploration.
Curiosity-driven learning: AgentEvolver introduces three synergistic mechanisms that enable an agent to improve itself continually. (i) Self-questioning uses the LLM’s semantic understanding to create curiosity-driven new tasks in novel environments (reducing dependence on manual datasets), (ii) Self-navigating reuses past experiences and employs a hybrid policy to guide exploration more efficiently, and (iii) Self-attributing assigns differentiated rewards to actions based on their contribution, boosting sample efficiency. Together, these mechanisms allow the agent to generate rich learning experiences on its own.
Improved efficiency: By integrating these mechanisms, AgentEvolver enables scalable, cost-effective, continual improvement of the agent’s capabilities. Preliminary experiments show it achieves more efficient exploration, better sample utilization, and faster adaptation than traditional RL-based baselines, demonstrating the benefits of the self-evolving approach.
RF-DETR: Neural Architecture Search for Real-Time Detection Transformers (paper/code)
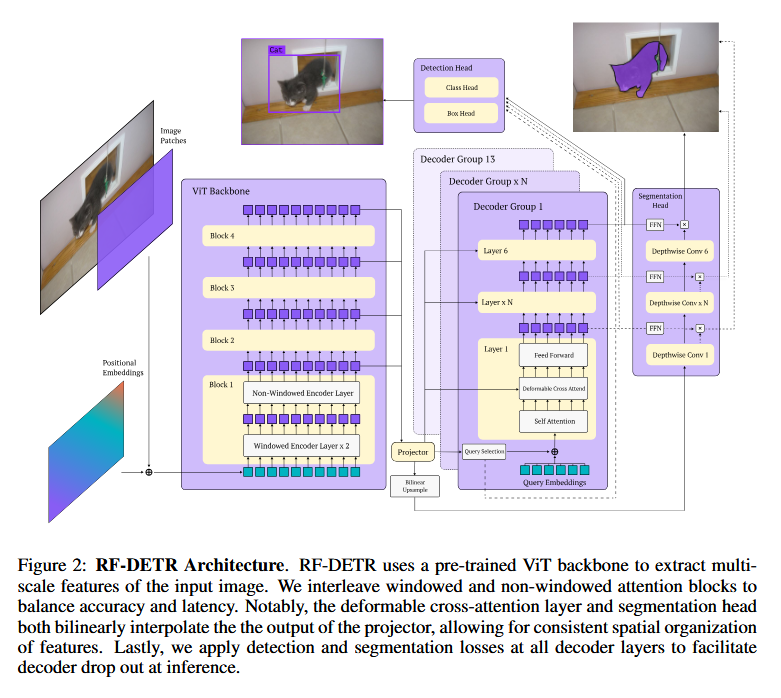
RF-DETR is a real-time object detector that uses neural architecture search (NAS) to optimize Detection Transformer models for any given target dataset. Rather than fine-tuning a large general vision-language model for every new domain, RF-DETR fine-tunes a base DETR on the target data and then rapidly explores thousands of architectural variations (via weight-sharing NAS) to find Pareto-optimal accuracy vs. latency configurations. The authors also adjust key architecture “knobs” to improve DETR’s transferability to diverse domains beyond COCO.
Domain-tuned NAS: This approach yields a family of lightweight, specialist DETR models that maintain high accuracy while meeting strict speed requirements. By revisiting tunable parameters (like encoder/decoder depths, embedding dimensions, etc.), RF-DETR finds architectures better suited for new data distributions without retraining from scratch for each candidate.
Real-time SOTA: RF-DETR significantly outperforms prior state-of-the-art real-time detectors. For instance, a tiny RF-DETR model (nano) achieves 48.0 AP on COCO, which is +5.3 AP higher than the previous best (D-FINE nano) at comparable latency. A larger RF-DETR (2×-large) surpasses 60 AP on COCO - the first time a real-time detector crosses this threshold - and on a domain adaptation benchmark (Roboflow100-VL), it beats GroundingDINO (tiny) by 1.2 AP while running 20× faster. These results establish RF-DETR as the new state of the art for real-time object detection.
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics (paper/code)
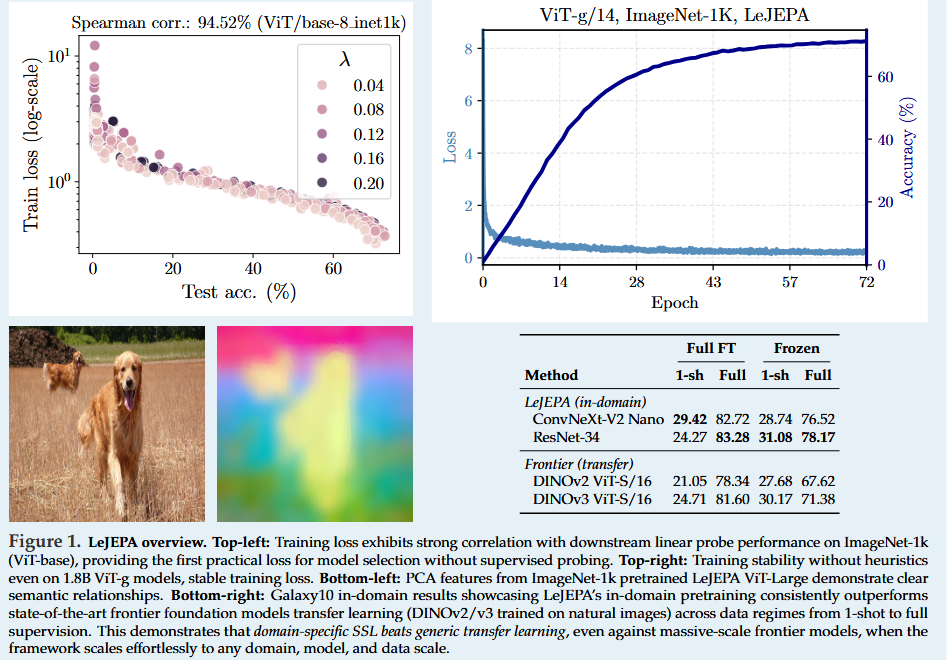
LeJEPA (Lean Joint-Embedding Predictive Architecture) is a self-supervised learning framework by Balestriero and LeCun that removes many ad-hoc tricks commonly used in representation learning. It provides a theoretical foundation for joint-embedding predictive architectures (JEPAs) by identifying the optimal target distribution for learned embeddings. In particular, the authors show that to minimize downstream prediction error, embeddings should follow an isotropic Gaussian distribution. Accordingly, LeJEPA introduces a novel regularization objective called Sketched Isotropic Gaussian Regularization (SIGReg) to enforce that the encoder’s output distribution is Gaussian.
Heuristics-free SSL: By combining the standard JEPA predictive loss with SIGReg, LeJEPA achieves stable and scalable self-supervised training without relying on brittle heuristics. Notably, it forgoes techniques like stop-gradient operations, teacher-student networks, or learning-rate schedulers. The framework has only a single hyperparameter to balance prediction vs. regularization, runs in linear time/memory, and works consistently across network architectures (ResNets, ViTs, ConvNets) and domains. Its implementation is also lightweight (≈50 lines of core code), making it friendly for distributed training.
Strong performance: Despite its simplicity, LeJEPA delivers competitive results. The authors validate it on 10+ datasets and 60+ model architectures. For example, with ImageNet-1k pretraining and a ViT-H/14 backbone, LeJEPA reaches about 79% top-1 accuracy in a frozen-feature linear probe - on par with state-of-the-art self-supervised methods. The work demonstrates that a principled, theory-driven approach can match the performance of heuristic-heavy methods, potentially reestablishing self-supervised pretraining as a core pillar of AI research.
The Path Not Taken: RLVR Provably Learns Off the Principals (paper)

This study examines the inner workings of Reinforcement Learning with Verifiable Rewards (RLVR) for fine-tuning LLMs, and it uncovers why RL-based tuning often only changes a small fraction of model weights despite large gains in performance. The authors find that the apparent sparsity of RLVR updates is due to an optimization bias: given a fixed pretrained model, gradient updates tend to concentrate in certain “preferred” parameter subspaces that are consistent across different runs, datasets, and reward setups. In other words, RLVR avoids altering the model’s principal components (the major directions of variation in weight space) and instead makes off-principal adjustments that preserve the model’s core representations.
Three-Gate theory: To explain these dynamics, the paper proposes a Three-Gate Theory of RLVR’s learning process. Gate I (KL Anchor) imposes a Kullback-Leibler constraint that keeps updates close to the original model. Gate II (Model Geometry) causes the policy update to steer away from high-curvature principal directions, confining changes to low-curvature, spectrum-preserving subspaces. Gate III (Precision) means many tiny parameter updates get “hidden” in unimportant directions due to numerical precision limits, making the off-principal bias manifest as overall sparsity. Together, these gates ensure RLVR makes very targeted weight changes.
Distinct fine-tuning regime: Empirically, RLVR’s parameter updates produce minimal distortion of the model’s spectral properties - there is little drift in the major singular values, and the principal subspace orientation is largely preserved. In contrast, standard Supervised Fine-Tuning (SFT) tends to push weights along principal directions, significantly rotating the feature space and often degrading the pretrained spectral structure. RLVR even outperforms SFT in reasoning tasks, despite touching fewer weights. These results show that RL fine-tuning operates in a qualitatively different regime from SFT. Consequently, the authors caution that directly applying SFT-era fine-tuning techniques (e.g. LoRA or other parameter-efficient methods) to RL training can be misguided. The paper’s insights pave the way for designing new, geometry-aware fine-tuning methods tailored specifically to RLVR, rather than repurposing heuristics from the SFT paradigm.
AlphaResearch: Accelerating New Algorithm Discovery with Language Models (paper/code)
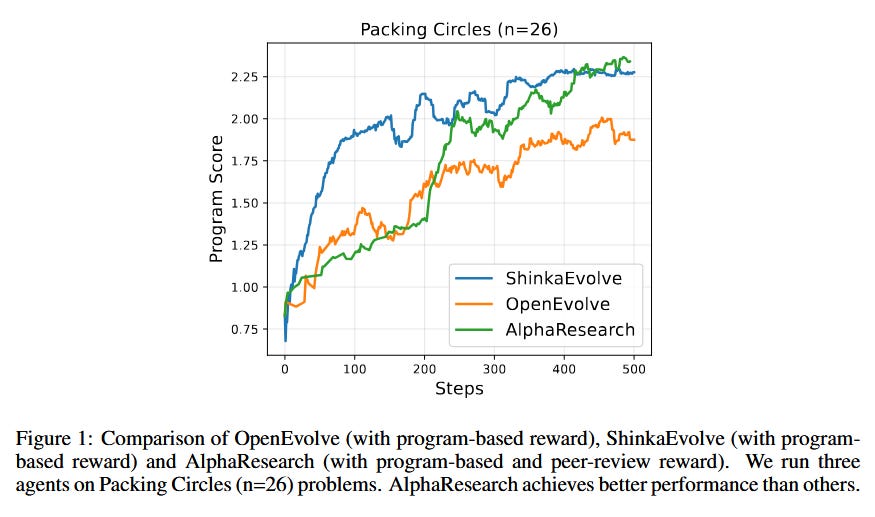
AlphaResearch explores using AI as a scientist - it’s an autonomous research agent built on an LLM that aims to discover novel algorithms for open-ended problems. The system frames algorithm discovery as an iterative loop where the AI proposes a new idea, tests it, and then refines the idea based on feedback. To support this, the authors set up a dual research environment: one part is execution-based (verifying candidate solutions by running them), and the other is a simulated “peer review” (critiquing and scoring the ideas, akin to a researcher’s intuition). This dual setup balances feasibility and creativity in the search for breakthroughs.
Iterative discovery loop: AlphaResearch runs through repeated cycles of (1) proposing new algorithmic ideas, (2) verifying those ideas in the dual environment (to see if they work and how well), and (3) optimizing the proposals for better performance. Through this self-driven research loop, the LLM can explore a wide solution space and learn from failures. The process is evaluated on AlphaResearchComp, a benchmark consisting of eight challenging algorithm-design competition tasks curated with executable tests and objective metrics.
Human-competitive results: Remarkably, the AlphaResearch agent managed to beat human researchers in 2 out of 8 problems on this benchmark. In particular, for a difficult circle packing problem, the algorithm devised by AlphaResearch achieved the best-known performance to date, surpassing all prior human-devised solutions and even outperforming a strong automated baseline from recent work (AlphaEvolve). These successes demonstrate the potential of LLMs to not just solve known problems but actually propose new algorithms. The authors also analyze the cases where the agent fell short (the other 6 tasks), identifying current limitations and guiding future improvements in AI-driven scientific discovery.
Beyond Fact Retrieval: Episodic Memory for RAG with Generative Semantic Workspaces (paper)
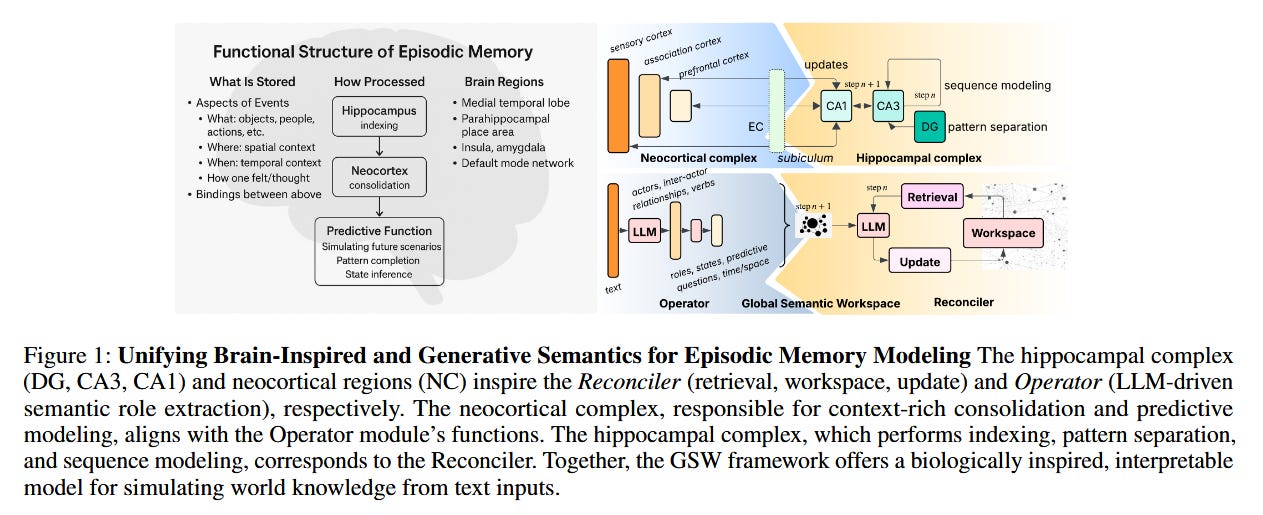
Large language models struggle with long-context reasoning, especially in understanding narratives that span many documents or events over time. This work introduces the Generative Semantic Workspace (GSW), a neuro-inspired memory framework that gives LLM-based agents a form of episodic memory for better long-horizon reasoning. Unlike standard Retrieval-Augmented Generation (RAG) methods that fetch discrete facts, GSW builds a structured, evolving representation of the world (a “workspace”) as the model reads through a story or a stream of observations. It explicitly tracks entities, their states, and their relations across space and time, enabling the model to maintain context over an episode.
Structured generative memory: The GSW framework consists of two main components. An Operator module maps incoming text or observations into intermediate semantic structures (for example, converting a paragraph into a mini knowledge graph of the events and entities). A Reconciler module then integrates these structures into a persistent global workspace, enforcing temporal, spatial, and logical coherence as the narrative progresses. This persistent workspace serves as an interpretable memory that the LLM can query and update, much like a human’s episodic memory. It allows the model to reason about evolving roles, actions, and contexts rather than just static facts.
Long-context gains: On the new Episodic Memory Benchmark (EpBench) - with narrative corpora ranging from 100k up to 1M tokens - the GSW approach significantly outperforms traditional RAG-based baselines (by up to 20% in accuracy). Moreover, GSW is highly efficient: by storing knowledge in the workspace, it cuts down the tokens needed at query time by 51% compared to the next best method, greatly reducing inference cost for long documents. In essence, GSW provides LLMs with a human-like ability to remember and make sense of event sequences, paving the way for more capable agents that can reason over long narratives and complex, evolving situations.
IterResearch: Rethinking Long-Horizon Agents via Markovian State Reconstruction (paper/code)
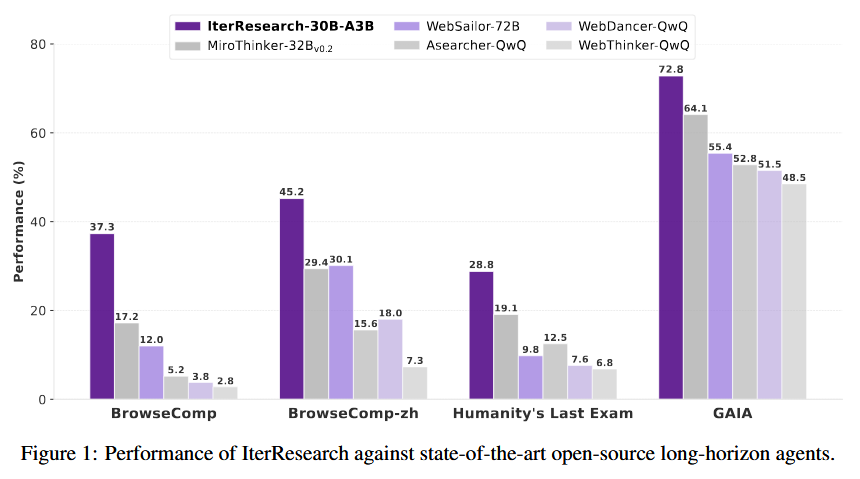
IterResearch proposes a novel paradigm to extend the effective reasoning horizon of AI agents by overcoming the context window limitation. Today’s “deep-reasoning” agents (e.g. an LLM agent doing multi-step research) often accumulate an ever-growing chat or memory, which leads to context suffocation and noise as the task gets longer. IterResearch rethinks this by reformulating a long-horizon task as a Markov Decision Process where the agent’s state is a reconstructible workspace rather than a raw history of all past interactions. In practice, the agent maintains an evolving report or intermediate summary of findings as it works, and it periodically synthesizes this report to refresh the context, thereby making the next decision based on a concise state rather than the entire history. This iterative state reconstruction keeps the reasoning process consistent and scalable no matter how deep the task goes.
Markovian context management: By periodically compressing knowledge into a stable state, IterResearch ensures the agent’s reasoning remains focused and does not degrade over thousands of steps. The approach effectively creates a sliding window of relevant information (a Markov state) instead of a single ever-expanding context. This eliminates the “invisible wall” that traditional agents hit when their context overflow leads to repetitive or shallow reasoning. The paper also introduces an Efficiency-Aware Policy Optimization (EAPO) algorithm to train such an agent: it uses geometric reward discounting to favor efficient exploration and adaptive downsampling to stabilize training across many iterations.
Unprecedented long-horizon performance: Extensive experiments show that IterResearch yields substantial improvements over existing open-source agent baselines, with an average +14.5 percentage points in success rate across six benchmarks. The paradigm demonstrates unprecedented scalability in interactive tasks - the agent was run for up to 2048 dialogue interactions, where naive agents would normally fail. Impressively, IterResearch’s performance at 2048 steps was 42.5%, up from just 3.5% when using a conventional approach, showing that it actually improves as the interaction count grows. Furthermore, the IterResearch method can be applied on top of existing powerful models as a prompting strategy: used with a state-of-the-art closed-source LLM, it boosted long-horizon task performance by up to 19.2 points over the standard ReAct prompting technique. These results position IterResearch as a versatile solution for long-horizon reasoning - effective both as a trained autonomous agent and as an prompting framework to keep advanced models “on track” during very extended reasoning sessions.

https://arxiv.org/abs/2511.08042
This one moved the needle