
🤏 The Small Model Revolution
Are data quality and effective prompting all we need?

In this issue:
Phi-2: another win for data quality
Towards as few human labels as possible
A unified benchmark for prompting techniques
Want to support me going professional as a content creator? Your pledge will help me make that a reality.
1. Phi-2: The surprising power of small language models
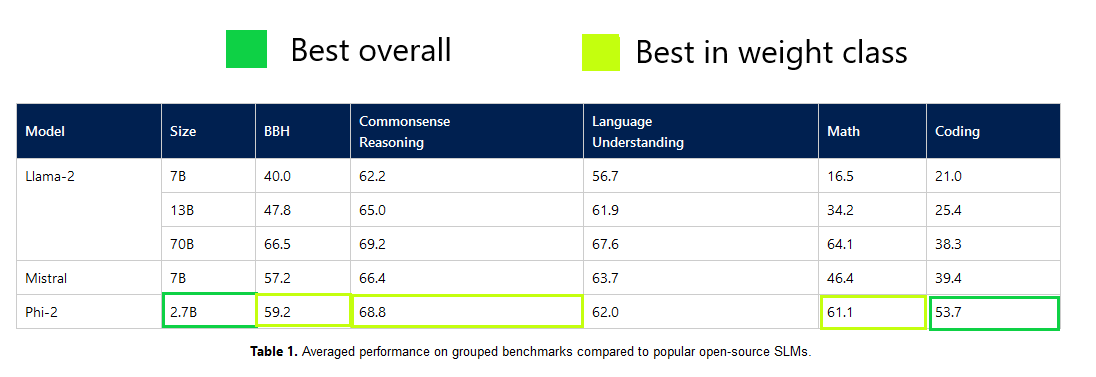
What problem does it solve? Microsoft's Research team has been addressing inefficiencies in Large Language Models (LLMs), specifically the trade-off between size and performance. Smaller models traditionally underperform in tasks like coding, common-sense reasoning, and language understanding compared to their larger counterparts. By advancing a suite of Small Language Models (SLMs), named "Phi", Microsoft aims to bridge this performance gap, ensuring that more compact models can still deliver high levels of accuracy and utility in various applications.
How does it solve the problem? The Phi series of models scale down the number of parameters without a proportional loss in performance. Phi-1 showcased this in coding benchmarks, performing on par with larger models. With Phi-1.5 and the latest Phi-2, Microsoft has implemented novel model scaling techniques and refined training data curation to achieve results comparable to models many times their size. The success of Phi-2, a 2.7 billion-parameter language model, signifies a leap in optimization that allows it to demonstrate state-of-the-art reasoning and language understanding, matching or exceeding models with up to 25 times more parameters.
What’s next? Providing access to Phi-2 via Huggingface opens a wealth of opportunities for further research. Smaller yet high-performing models like Phi-2 present an ideal testbed for experiments in mechanistic interpretability and safety, reducing the computational resources required for fine-tuning and exploring new tasks. Their more manageable size also makes them suitable for applications where deploying larger models is impractical. The ongoing work from Microsoft Research signals continuous improvements in SLMs, which could redefine industry benchmarks and open new avenues for widespread adoption of sophisticated AI tools in diverse fields.
2.Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models
Watching: ReSTEM (paper)

What problem does it solve? Training language models typically requires vast quantities of human-generated text, which can be scarce or of variable quality, especially for specialized domains like mathematics or programming. This scarcity limits the model's ability to learn diverse patterns and hinders its performance. ReSTEM addresses this problem by reducing the reliance on human-curated datasets and instead exploring the potential of fine-tuning models using self-generated data validated through scalar feedback mechanisms.
How does it solve the problem? ReSTEM employs an iterative self-training process leveraging expectation-maximization. It first generates outputs from the language model, then applies a filtering mechanism based on binary correctness feedback—essentially sorting the wheat from the chaff. Subsequently, the model is fine-tuned using these high-quality, self-generated samples. This cycle is repeated several times, thus iteratively enhancing the model's accuracy and performance on tasks by self-generating and self-validating the training data.
What’s next? With ReSTEM showing promising results, especially in larger models, one can anticipate further exploration in applying self-training techniques to various other domains beyond math and coding tasks. The significant improvement over fine-tuning on human data implies that future models can be made more efficient, less reliant on extensive datasets, and potentially achieve better performance.
3. PromptBench: A Unified Library for Evaluation of Large Language Models
Watching: Data-constrained Scaling Law (paper)

What problem does it solve? Accurately evaluating Large Language Models (LLMs) is a complex challenge, requiring an understanding of their performance across a variety of tasks and ensuring that their deployment does not pose security risks. Previously, there was no standardized way to assess LLMs, resulting in fragmented efforts and a lack of comparability across studies. PromptBench addresses this by providing a comprehensive library that unifies the varied aspects of LLM evaluation, from prompt construction to adversarial testing, paving the way for more systematic and robust LLM assessment.
How does it solve the problem? PromptBench simplifies the evaluation process with its modular design, offering tools for prompt construction, engineering, dataset and model loading, and more. This flexibility allows researchers to easily mix and match components to tailor evaluations to their specific research needs. For example, through its adversarial prompt attack module, researchers can probe for vulnerabilities in a model's response to prompts designed to deceive or confuse it. Dynamic evaluation protocols facilitate the creation of benchmarks that reflect real-world applications, thus ensuring that the evaluation of LLMs is not just thorough but also relevant.
What’s next? PromptBench’s open-source nature encourages collaboration and continuous improvement within the research community. We can expect new benchmarks to emerge, tailored to the evolving capabilities of LLMs. Additionally, the field will likely see more advanced downstream applications and evaluation protocols developed using the framework. The fact that Microsoft is committed to supporting PromptBench underscores the importance of this work and assures its growth and refinement over time.
Papers of the Week:
Making LLMs Worth Every Penny: Resource-Limited Text Classification in Banking
ThinkBot: Embodied Instruction Following with Thought Chain Reasoning
Hallucination Augmented Contrastive Learning for Multimodal Large Language Model
Enabling Fast 2-bit LLM on GPUs: Memory Alignment and Asynchronous Dequantization
Foundation Models in Robotics: Applications, Challenges, and the Future