
The Papers You Should Know About
Get ahead of the curve with LLM Watch

Fastest way to become an AI Engineer? Building things yourself!
Get hands-on experience with Towards AI’s industry-focused course: From Beginner to Advanced LLM Developer (≈90 lessons). Built by frustrated ex-PhDs & builders for real-world impact.
Build production-ready apps: RAG, fine-tuning, agents
Guidance: Instructor support on Discord
Prereq: Basic Python
Outcome: Ship a certified product
Guaranteed value: 30-day money-back guarantee
Pro tip: Both this course and LLM Watch might be eligible for your company’s learning & development budget.
Diffusion Language Models are Super Data Learners (paper/code)
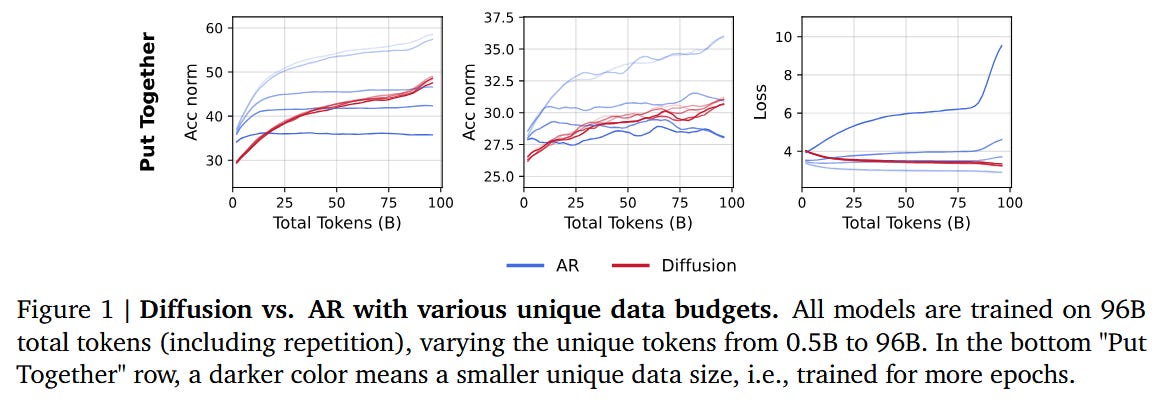
Under limited unique data, diffusion-based language models (DLMs) consistently outperform equally-sized autoregressive (AR) models when trained for more epochs – a point the authors call the Intelligence Crossover. This crossover occurs robustly across different data budgets, model scales, and even in sparse (Mixture-of-Experts) vs dense architectures. The authors find that DLMs can extract much more signal from repeated data before overfitting, whereas AR models plateau earlier.
Key factors for DLM gains: The superiority of DLMs under data scarcity is attributed to (1) Any-order modeling (removing AR’s fixed causal bias), (2) “Super-dense” compute (iterative bidirectional denoising uses far more FLOPs per token), and (3) Built-in Monte Carlo augmentation (training naturally averages over many noised versions of each sequence). While adding noise to AR inputs helps a bit, it cannot match the benefit that DLMs get from these factors.
Crossover at scale: Using a matched compute budget (~1.5 trillion token updates), a 1.7B-parameter DLM trained on 10B unique Python tokens overtook an AR code model trained under identical conditions. In other words, the DLM reached parity with state-of-the-art AR coders that were trained on orders of magnitude more unique data.
Small data, big results: Remarkably, a 1B-parameter DLM achieved >56% accuracy on HellaSwag and >33% on MMLU using only 1B tokens of training data (by repeating the data for many epochs). This significantly outperformed a larger 7B AR model trained on the same repeated dataset (which reached ~41% and 29% on those benchmarks). Even after 480 epochs on the 1B-token corpus, the DLM showed no saturation in performance, indicating it can continue squeezing signal from limited data. Notably, rising validation loss was found not to correlate with worse downstream accuracy in this regime (i.e. “overfitting” on val loss did not immediately harm actual task performance).
Kosmos: An AI Scientist for Autonomous Discovery (paper/demo)
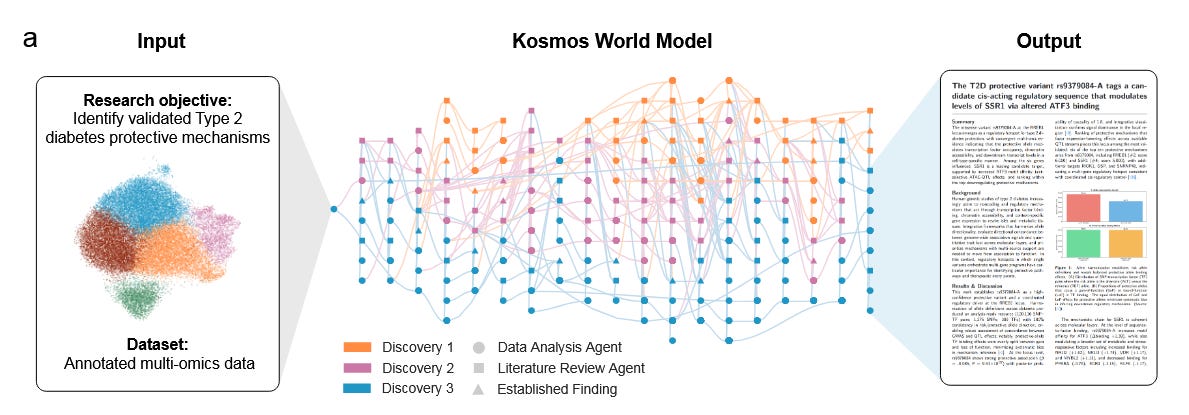
Kosmos is a new AI agent designed to perform fully autonomous scientific research. Given an open-ended research goal and a dataset, Kosmos runs up to 12 hours, iterating through cycles of data analysis, literature search, and hypothesis generation, then synthesizing its findings into a report. Unlike prior agents that quickly lose coherence, Kosmos uses a structured “world model” to share information between a data-analysis sub-agent and a literature-search sub-agent, allowing it to maintain focus over 200 consecutive agent steps. This enables Kosmos to execute around 42,000 lines of code and read ~1,500 research papers in a single run while staying on task. It also citations every statement in its final reports with either code or literature sources, ensuring traceable reasoning.
Research effectiveness: In evaluations, independent domain experts judged about 79.4% of statements in Kosmos’s reports to be factually accurate, indicating a high reliability. Scientists who collaborated with Kosmos reported that a single 20-cycle run (roughly 12 hours) accomplished the equivalent of ~6 months of their manual research work. Moreover, the number of valuable findings grew roughly linearly with the number of cycles (tested up to 20 cycles), suggesting longer runs keep yielding new insights.
Notable discoveries: The paper highlights seven discoveries made by Kosmos across diverse fields – including metabolomics, materials science, neuroscience, and genetics. Impressively, three of these discoveries independently reproduced results that were in preprints or unpublished manuscripts (which Kosmos did not have access to), essentially “rediscovering” known science. The other four findings were novel, contributing new scientific knowledge that had not yet been published. These results demonstrate that Kosmos can go beyond rote retrieval – it can generate new hypotheses and insights, marking a step towards AI as an autonomous scientific collaborator rather than just a tool.
MemSearcher: Training LLMs to Reason, Search and Manage Memory via End-to-End Reinforcement Learning (paper/code)
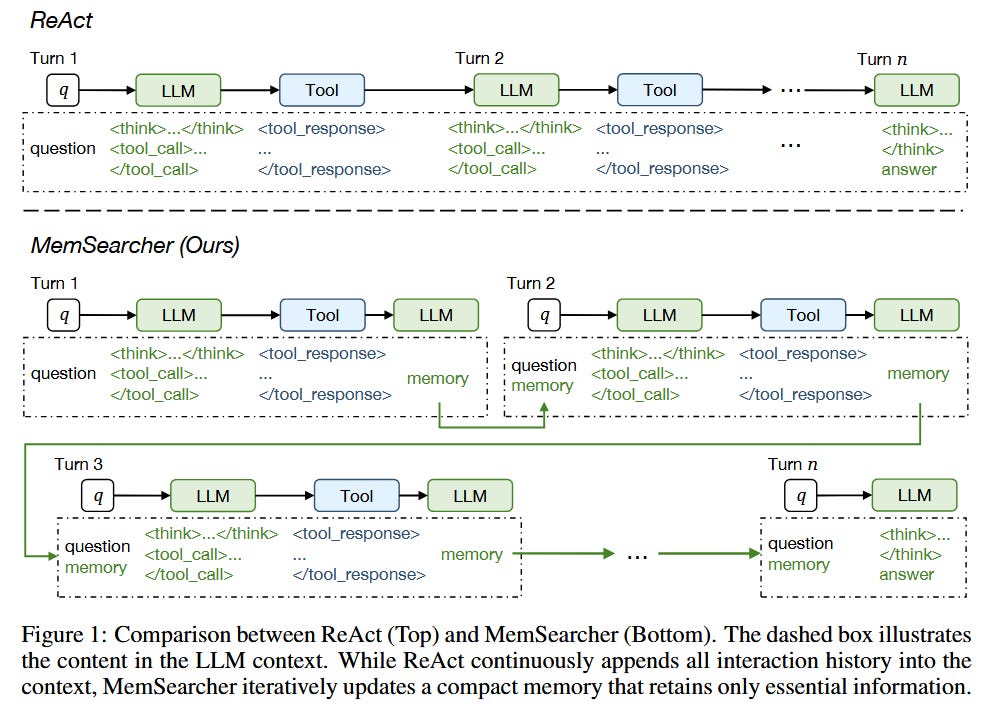
MemSearcher introduces an LLM-based agent architecture designed for more efficient multi-turn question answering and web search tasks by actively managing its memory context. Typical search agents either stuff the entire interaction history into the prompt (maintaining context at the cost of very long inputs), or only use the latest query (saving tokens but forgetting important info). MemSearcher strikes a balance: at each turn, it combines the user’s current question with a compact memory state that it continuously updates. The model’s reasoning process involves generating chain-of-thought reasoning traces, deciding when and what to search, and refining the memory – keeping only the information essential for solving the overall task. This design stabilizes the context length over a dialogue, greatly improving efficiency without sacrificing accuracy.
End-to-end RL training: The agent is trained with a custom reinforcement learning algorithm called multi-context GRPO, which optimizes the policy over reasoning, search, and memory-update decisions together. The training involves sampling groups of conversations with different context configurations and propagating rewards at the conversation level, teaching MemSearcher how to handle information across multiple turns coherently.
Performance gains: MemSearcher, when trained on the same data as a strong baseline agent (Search-R1), achieved significant improvements on 7 benchmark datasets. For example, a MemSearcher built on a 3B parameter base LLM outperformed even 7B parameter baseline models, yielding an ~+11% accuracy gain on Qwen2.5-3B-Instruct and +12% on Qwen2.5-7B-Instruct benchmarks. In practice, the 3B MemSearcher outperformed a 7B baseline, showing that smarter memory and reasoning can beat brute-force model size. This approach thus yields better accuracy while using far fewer tokens and compute per turn, pointing to a path for making LLM-based agents more efficient through learned memory management.
ThinkMorph: Emergent Properties in Multimodal Interleaved Chain-of-Thought Reasoning (paper/code)
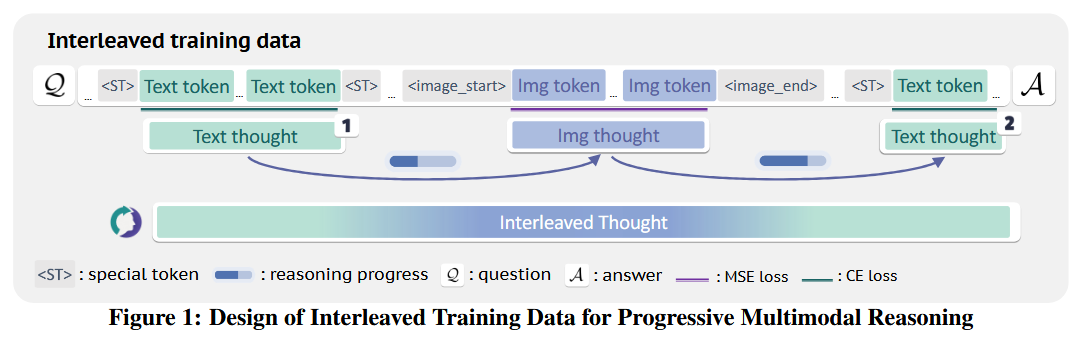
ThinkMorph is a vision–language reasoning model that pioneers interleaved chain-of-thought (CoT), mixing text and image “thought” steps to solve multimodal tasks. The key idea is that during reasoning, language and vision components should complement each other rather than operate in isolation or simply mirror one another. The ThinkMorph model was fine-tuned on ~24,000 high-quality examples of interleaved text-image reasoning traces (covering tasks with varying degrees of visual involvement). Guided by the principle that textual and visual thoughts should each do what they’re best at, ThinkMorph learns to produce reasoning chains that “concretely manipulate” visual content (e.g. drawing on images or imagining transformations) while maintaining coherent verbal logic.
Improved multimodal performance: On several vision-centric benchmarks, ThinkMorph delivers large performance gains, averaging a +34.7% improvement over its base model. It even generalizes to entirely new tasks (not seen in training), often matching or exceeding the performance of much larger proprietary vision-language models. This suggests that a 7B-sized open model with better reasoning can rival models many times its size by using multimodal CoT effectively.
Emergent abilities: Beyond raw accuracy, ThinkMorph exhibits striking emergent multimodal intelligence. The authors report that it learned previously unseen visual manipulation skills – for instance, performing transformations on images or spatial reasoning that it wasn’t explicitly trained to do. It can adaptively switch between modalities in its reasoning (knowing when to use image-based reasoning vs. text) and shows improved performance when allowed more inference time by generating diversified multimodal thoughts. These behaviors hint at a new class of capabilities unique to interleaved reasoning. The work suggests that carefully blending modalities in CoT not only improves results, but also unlocks new problem-solving strategies that neither modality could achieve alone.
Tongyi DeepResearch Technical Report (paper/code)
Alibaba’s Tongyi DeepResearch is a 30.5B-parameter “agentic” large language model tailored for long-horizon, deep information-seeking research tasks. The emphasis is on enabling the LLM to act as an autonomous research agent, capable of complex multi-step reasoning and web interaction to gather information. To train this capability, the team developed an end-to-end framework with two special stages: agentic mid-training and agentic post-training. Essentially, after the base LLM pre-training, the model is further trained in custom interactive environments that simulate research scenarios – all without human annotators, using a highly scalable automatic data synthesis pipeline. By constructing tailored simulation environments for each training stage, Tongyi DeepResearch learns to conduct stable and consistent long-term interactions (e.g. browsing documents, asking follow-up questions, retrieving evidence) in pursuit of research goals.
Mixture-of-Experts efficiency: Tongyi DeepResearch uses a Mixture-of-Experts-like architecture – it has 30.5B total parameters, but only ~3.3B are “activated” per token on average. This design allows scaling the model’s overall capacity while keeping inference efficient, as only a subset of experts are used at each step. The result is a model that can carry out extensive reasoning without incurring the full compute cost of 30B parameters each time.
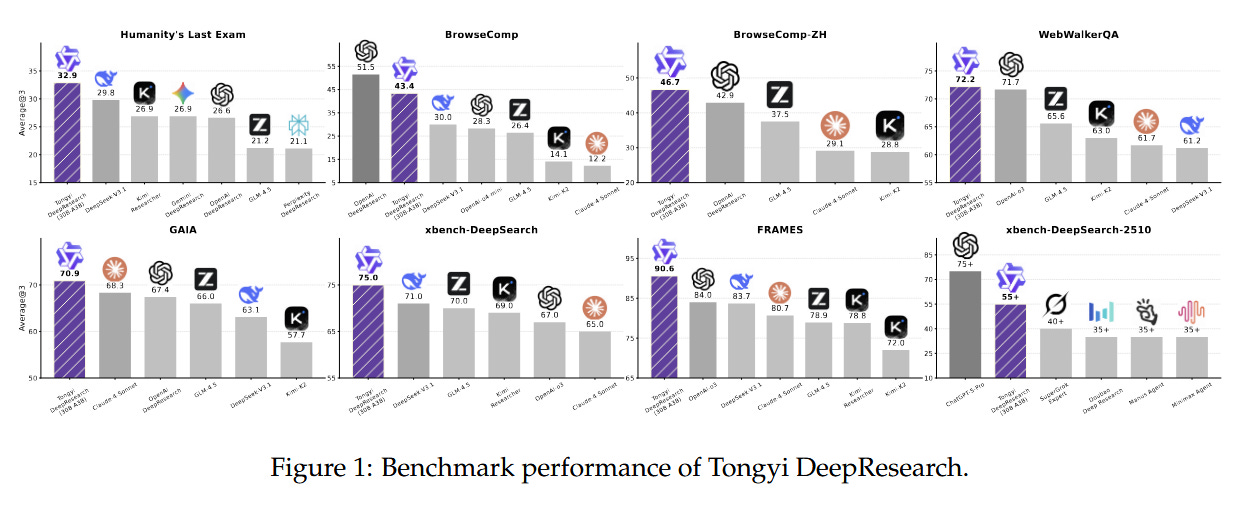
Benchmark leader & open source: The model achieves state-of-the-art performance on a suite of agent-based deep research benchmarks. For instance, it tops the leaderboard on evaluations like Humanity’s Last Exam, BrowseComp (and BrowseComp-ZH), WebWalkerQA, xBench-DeepSearch, and FRAMES – tasks that involve web browsing, long-form QA, and complex multi-hop reasoning. These results indicate a new level of proficiency in autonomous research for LLMs. Moreover, the Tongyi team has open-sourced the entire project, including the model weights, training framework, and “complete solutions,” to encourage community development in agentic LLMs. This release provides a valuable resource for further research into large LLM-based agents that can perform real-world research tasks.
Towards Robust Mathematical Reasoning (paper/code)
This work by Luong et al. addresses the challenge of evaluating and improving advanced mathematical reasoning in AI models. A key insight is that many existing math benchmarks are too easy or only test short answers, which doesn’t reflect true mathematical problem-solving ability. To push the frontier, the authors introduce IMO-Bench, a suite of benchmarks at the level of the International Mathematical Olympiad (IMO) – one of the most difficult math competitions for high school students. IMO-Bench has two main components: IMO-AnswerBench (400 diverse Olympiad problems with verifiable short answers) and IMO-ProofBench (a set of Olympiad-level problems that require writing full proofs, along with detailed grading rubrics for automatic evaluation). These benchmarks were vetted by top mathematicians to ensure they truly reflect IMO difficulty. The authors argue that using such challenging, rigorously evaluated benchmarks is crucial as a “north-star” for advancing math reasoning in AI.
Historic achievement: Using IMO-Bench to guide development, the team’s model (nicknamed Gemini Deep Think) became the first AI system to achieve “gold medal” performance on the IMO 2025 competition problems. Concretely, their model scored 80.0% on IMO-AnswerBench (short answers) and 65.7% on IMO-ProofBench (detailed proofs), which surpassed the best non-Gemini models by 6.9% and a whopping 42.4% respectively. These are huge margins, especially the jump in proof-solving ability, suggesting a major advance in machine reasoning.
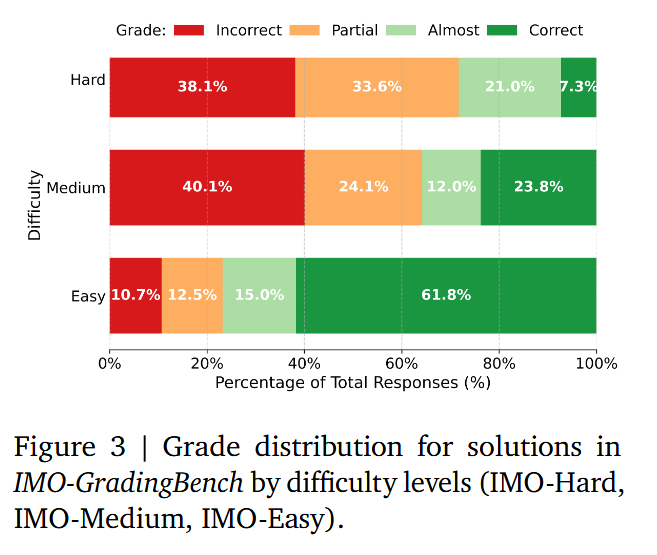
Automated grading and future work: To facilitate progress in this area, they also built an automatic proof grader using an LLM (leveraging the model’s own reasoning abilities for grading). They compiled IMO-GradingBench, a dataset of 1,000 human-graded proof solutions, and showed that the AI-based grader’s scores correlate well with human judgments. This is an important step toward reliably evaluating long-form, step-by-step reasoning. The authors are releasing IMO-Bench publicly, aiming to rally the community around truly robust mathematical reasoning – moving beyond just getting the right answer, to actually showing the work as a human mathematician would.
Kimi Linear: An Expressive, Efficient Attention Architecture (paper/code)
The Kimi Linear architecture proposes a novel attention mechanism that achieves the best of both worlds: it retains the efficiency of linear (low-rank) attention approximations while actually outperforming standard full attention on accuracy. This is significant because until now, linear or efficient transformers (which scale to long contexts) often had to trade off some accuracy for speed. Kimi Linear introduces a module called Kimi Delta Attention (KDA), which extends the ideas from DeltaNet by adding a more fine-grained gating mechanism. Essentially, it’s a hybrid approach: part RNN-based (finite-state) and part Transformer, where the gating allows more effective use of the RNN-style state memory. The authors also developed a custom “chunkwise” computation algorithm that makes this architecture highly hardware-efficient. They leverage a specialized form of Diagonal-Plus-Low-Rank (DPLR) matrices to drastically cut down compute, while still closely emulating the full expressiveness of the classic delta rule networks.
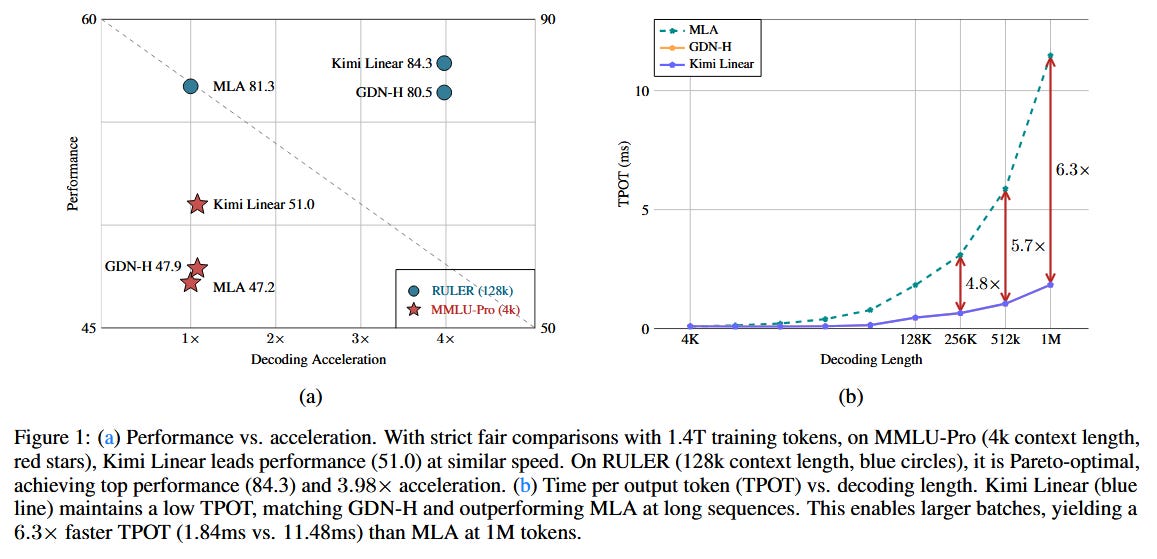
Beating full attention: In experiments across a variety of settings – including short context tasks, long-context tasks up to 1M tokens, and even reinforcement learning scenarios – Kimi Linear models consistently outperformed equivalent models using full attention. The team pre-trained a large Kimi Linear model with 48B total parameters (with 3B parameters active per token), using a mix of KDA and standard multi-head latent attention layers. With the same training data and hyperparameters, this 48B (3B active) Kimi model beat a standard Transformer of the same size on all evaluated tasks.
Efficiency gains: Apart from accuracy, Kimi Linear is much more resource-friendly in deployment. It reduces the key-value cache memory by up to 75% compared to a vanilla Transformer, which is a huge savings for long sequences. Moreover, for extremely long contexts (e.g. generating text with a context of 1 million tokens), it achieved up to 6× faster decoding throughput than the baseline full-attention model. These improvements mean that one can swap in Kimi Linear in place of standard attention to get both better speed/memory usage and better task performance – a rare win–win. To encourage adoption and further research, the authors have open-sourced the core KDA kernels and provided implementations in the vLLM library, along with releasing their pre-trained 48B model and an instruction-tuned checkpoint.
Continuous Autoregressive Language Models (paper/code)
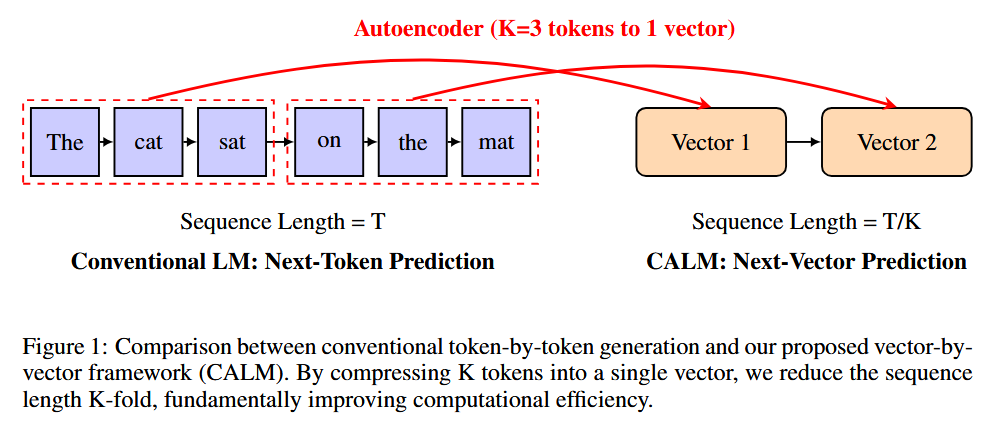
The paper introduces Continuous Autoregressive Language Models (CALM), which fundamentally rethink the generation process of LLMs to overcome the inefficiency of one-token-at-a-time decoding. The idea is a paradigm shift from discrete tokens to continuous vectors: instead of predicting the next word/token, the model predicts a continuous embedding that represents a whole chunk of text. A high-fidelity neural autoencoder compresses a sequence of K tokens into a single vector, which can later be decoded back to the original tokens with 99.9%+ accuracy. By doing this, the language sequence is transformed into a sequence of continuous vectors, and the model needs only 1 step to generate K tokens worth of content (effectively increasing the “bandwidth” of each generation step by a factor of K). This drastically cuts down the number of forward passes required to produce a given length of text.
New modeling framework: Moving to continuous predictions required the authors to develop a likelihood-free training and evaluation framework. Traditional language models maximize likelihood of discrete token sequences; by contrast, CALM operates in a continuous space where notions of probability and decoding differ. The paper presents methods for training these models, measuring their performance, and even doing controllable generation entirely in the continuous domain.
Results – speed vs. performance: Experiments show that CALM can achieve the same level of performance as strong token-based LLMs with far less computation. For example, if a baseline needs N transformer steps to generate N tokens, a CALM model with compression factor K might need only N/K steps – yielding a significant speedup. The authors report that the performance-compute trade-off is markedly improved: for a given compute budget, CALM models outperform their discrete counterparts. This establishes next-vector prediction as a promising path toward ultra-efficient LLMs. The work is still early (since we need highly accurate text autoencoders for this to work), but it suggests that in the future we might abandon word-by-word generation altogether. The code and project details have been released, indicating an invitation for the community to build on this paradigm.
The Era of Agentic Organization: Learning to Organize with Language Models (paper)
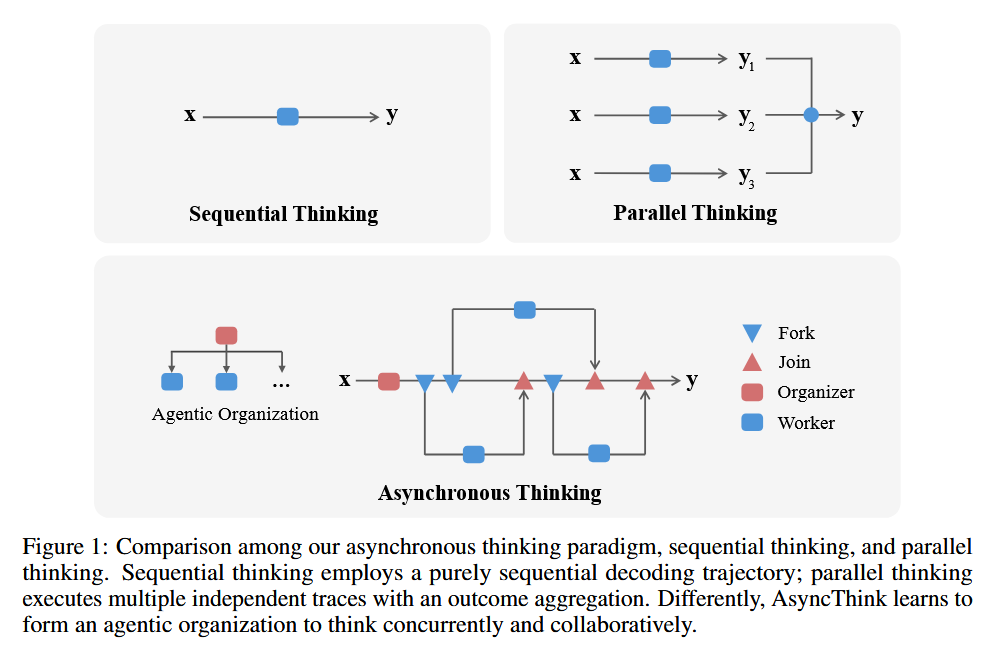
Chi et al. propose a vision of AI problem-solving that goes beyond a single AI agent thinking sequentially – instead, they describe an “agentic organization” where multiple agents work concurrently and collaboratively on different aspects of a complex problem. In this paradigm, AI agents can achieve outcomes that no individual could, by effectively organizing their teamwork. The authors implement this idea via a new reasoning framework called Asynchronous Thinking (AsyncThink). In AsyncThink, a central Organizer agent orchestrates the process: it dynamically breaks down a task into sub-queries and assigns these to multiple Worker agents in parallel. The workers pursue their subtasks (querying a knowledge base, computing partial solutions, etc.), and the organizer then merges their intermediate results into a final answer. Crucially, the structure of this thinking process – how to split the problem and when to coordinate – can itself be optimized via reinforcement learning, rather than being hand-designed.
Speed and accuracy gains: Experiments on complex reasoning tasks showed that AsyncThink achieved a 28% reduction in inference latency compared to a baseline parallelism approach (where multiple reasoning threads run without a learned organizer). By intelligently scheduling sub-tasks asynchronously, it solves problems faster than purely sequential chains-of-thought, but also avoids the pitfalls of naive parallel thinking. Moreover, accuracy on mathematical reasoning improved when using AsyncThink, indicating that the learned organization leads to better solutions, not just faster ones.
Generalization: A notable finding is that the AsyncThink framework, once trained, could generalize to tackle entirely new tasks without additional training. The agents learned a form of reasoning organization that is transferable: they can effectively self-organize on unseen problems. This suggests the emergence of a more abstract skill – learning how to “think together” – which could be applied broadly. The work heralds a new direction where instead of scaling a single model’s size, we may achieve greater intelligence by scaling how models organize themselves as a collective. It’s a step toward treating an AI system as a coordinated team of specialized problem-solvers.
Context Engineering 2.0: The Context of Context Engineering (paper/code)
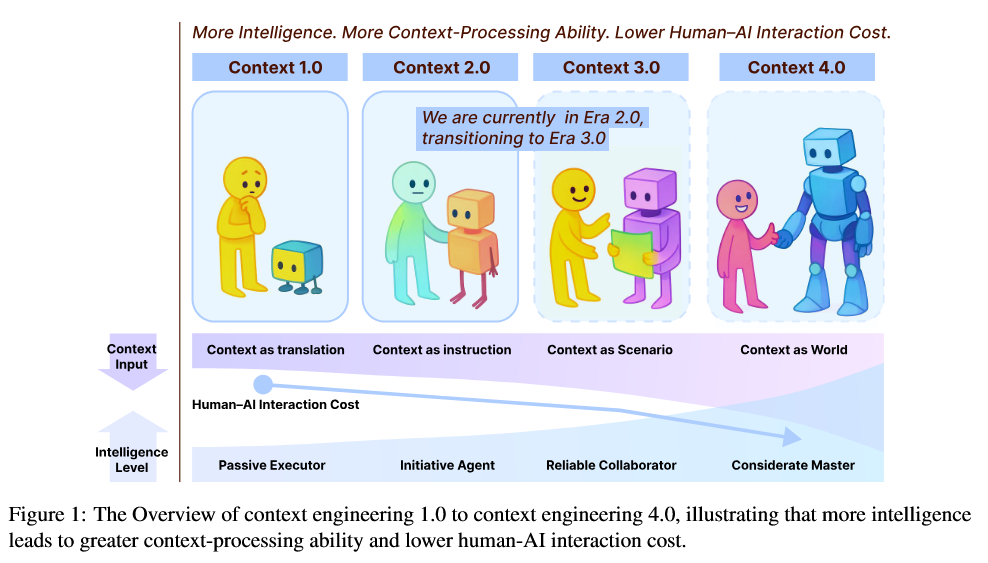
This paper provides a comprehensive conceptual and historical perspective on “context engineering” in AI systems. Context engineering refers to designing AI systems that deeply understand and leverage the context of their interactions (whether human context or situational context) to behave appropriately. The authors note that while the term has gained popularity recently in the age of advanced AI agents, the underlying idea has roots stretching back decades. They trace how, since the early 1990s, researchers have incrementally built ways for machines to grasp context: from early human-computer interaction frameworks with relatively simple computers, to today’s sophisticated human–AI agent interactions, and looking forward to scenarios with human-level or superhuman AI in the future. In essence, as machines have grown more intelligent, the approaches to context have evolved through distinct phases – and we are now in a new phase (“Context Engineering 2.0”) focusing on AI agents.
Defining context engineering: The paper offers a formal definition and taxonomy of context engineering, grounding it in prior work and clarifying its scope. It examines the historical milestones in the field, showing that many techniques (like memory networks, user modeling, environment simulation, prompt engineering, etc.) are all part of a continuum of efforts to give AI a better understanding of the situation it operates in. By situating today’s practices in this historical context, the authors argue that context engineering is not just a buzzword but a field with rich lineage and principles.
Design considerations & future outlook: Importantly, the report discusses key design considerations for practical context engineering. This includes how to represent contextual knowledge, how to update context dynamically, privacy and ethical concerns in using contextual data, and how to evaluate an AI’s contextual understanding. The authors aim to provide a conceptual foundation that will guide researchers and developers in systematically incorporating context into AI systems. Rather than ad-hoc prompt tweaks or heuristic approaches, they advocate for a principled approach to context in AI. The paper is essentially a call to arms for the community to recognize context engineering as a first-class discipline – one that will be crucial as we design AI agents that interact fluently with humans and complex real-world environments.
