
🧠 The Next Level of CoT Prompting
And small open source models continue to get more powerful

In this issue:
A more strategic way of prompting
Closing the open source gap for MoE models
The most powerful small code model… yet
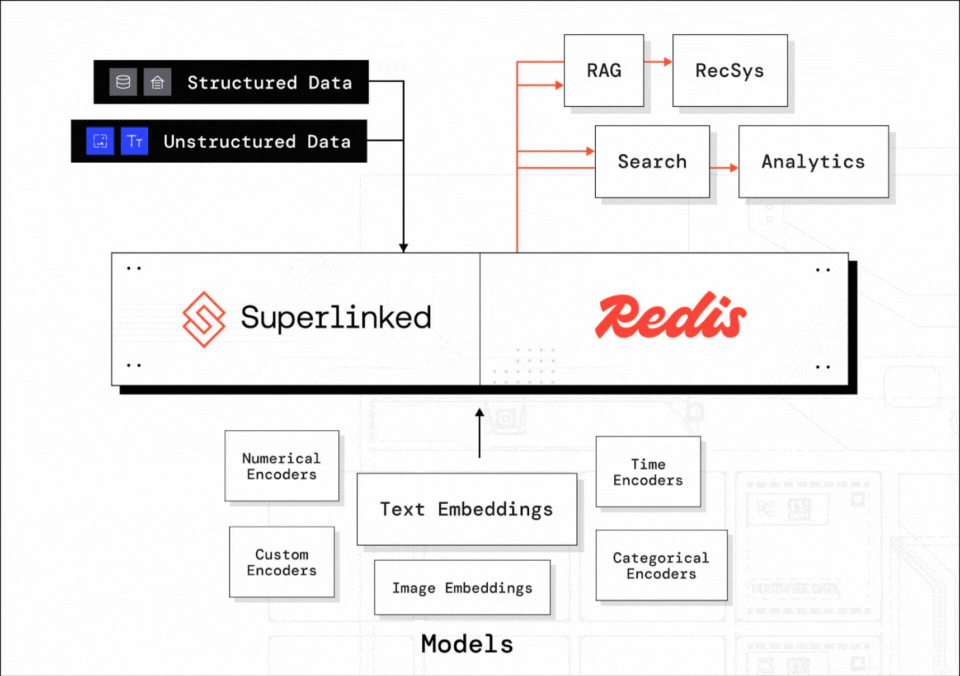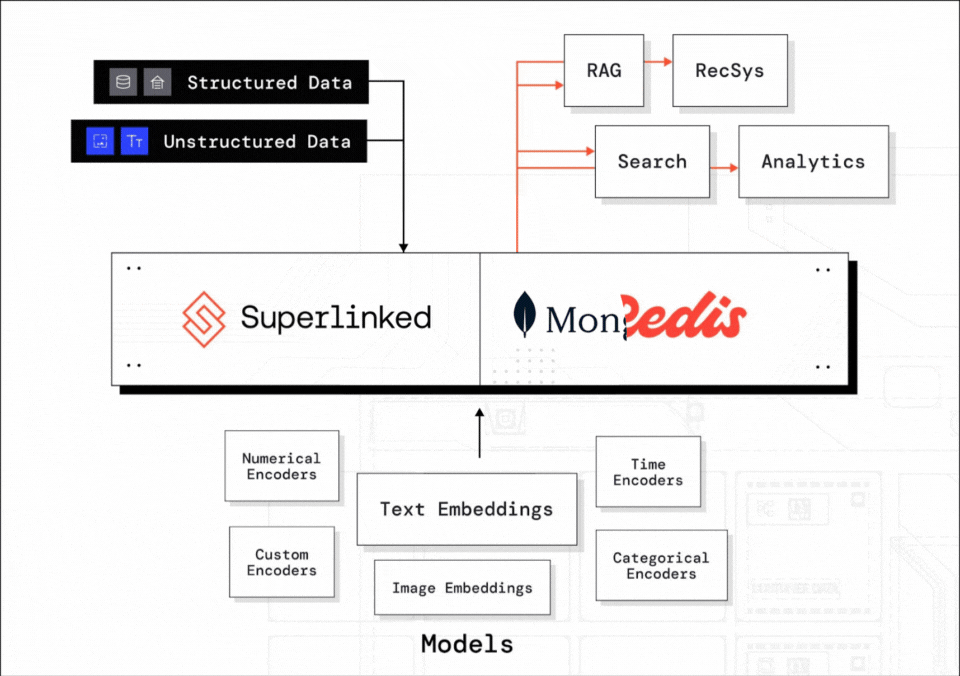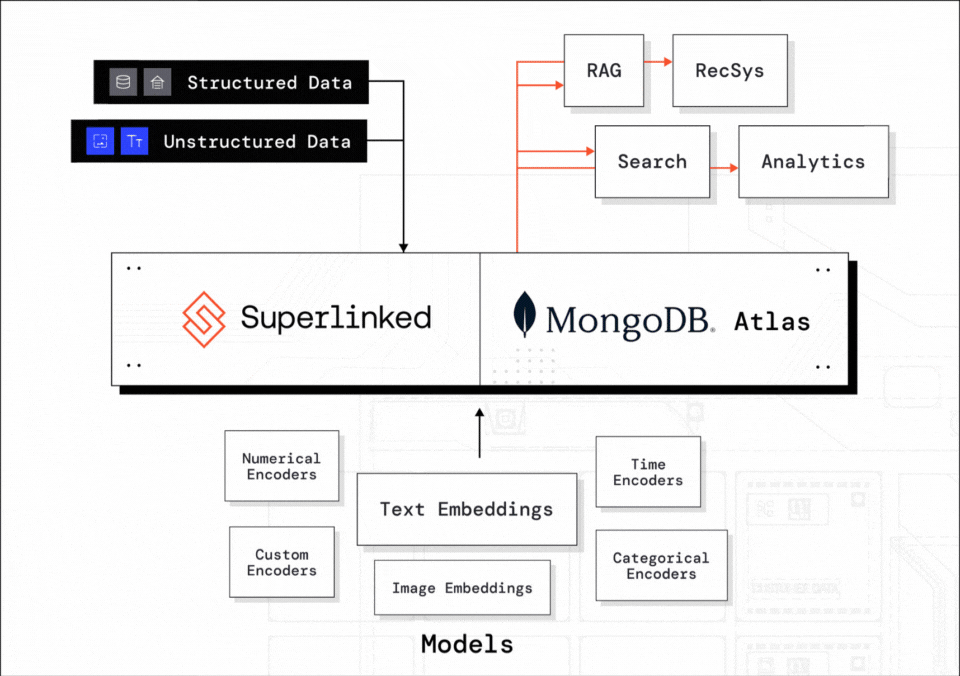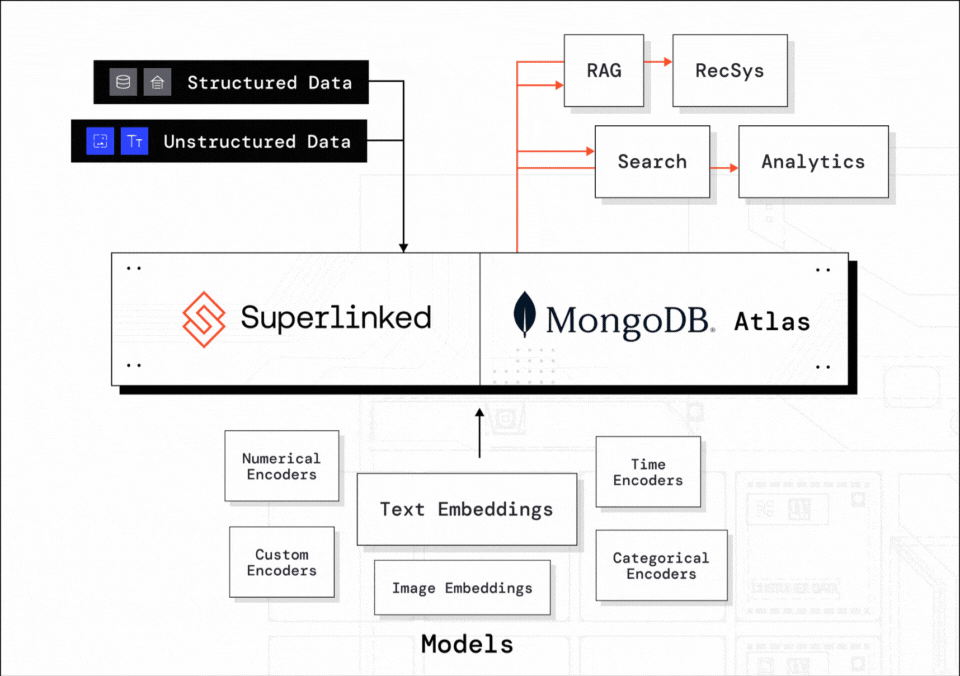
Vectors are everywhere these days and Superlinked is the compute framework for all your vector needs.
In partnership with Redis and MongoDB, they’ve just launched their new database connectors that enable easy and seamless integration with your existing stack.
This one really is worth giving a try if you want to get the most out of your AI systems in production.
Try it out yourself and don’t forget to give them a star on GitHub.
1. Strategic Chain-of-Thought: Guiding Accurate Reasoning in LLMs through Strategy Elicitation
Watching: SCoT (paper)
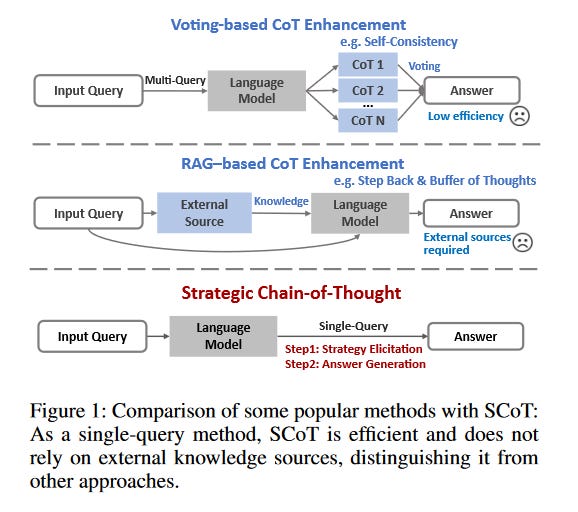
What problem does it solve? Chain-of-Thought (CoT) prompting has become a popular technique for eliciting multi-step reasoning capabilities from Large Language Models (LLMs). By providing intermediate reasoning steps, CoT enables LLMs to solve complex problems more effectively. However, the quality and consistency of the generated reasoning paths can be unstable, leading to suboptimal performance in reasoning tasks.
How does it solve the problem? Strategic Chain-of-Thought (SCoT) addresses the instability issue by incorporating strategic knowledge into the CoT process. SCoT employs a two-stage approach within a single prompt. First, it elicits an effective problem-solving strategy from the LLM. Then, it uses this strategy to guide the generation of high-quality CoT paths and final answers. By integrating strategic knowledge prior to generating intermediate reasoning steps, SCoT ensures more consistent and reliable reasoning performance.
What's next? The authors demonstrate the effectiveness of SCoT across eight challenging reasoning datasets, showing significant improvements over traditional CoT methods. They also extend SCoT to a few-shot learning setting with automatically matched demonstrations, further enhancing its performance. As LLMs continue to be used fore more complex tasks, incorporating strategic knowledge and improving the consistency of reasoning paths will be crucial. SCoT provides a promising framework for future research in this direction.
2. OLMoE: Open Mixture-of-Experts Language Models

What problem does it solve? Mixture of Experts (MoE) is a promising approach to building more efficient and scalable language models. By using a set of specialized "expert" models and a gating mechanism to route inputs to the most relevant experts, MoEs can potentially achieve better performance with fewer parameters compared to dense models. However, despite ongoing research and improvements in MoE architectures, most state-of-the-art language models, such as Llama, still rely on dense architectures. The lack of fully open-source, high-performing MoE models has hindered the adoption and further research of this approach.
How does it solve the problem? OLMOE-1B-7B is introduced as the first fully open-source, state-of-the-art Mixture of Experts language model. With 1B active and 7B total parameters, OLMOE-1B-7B achieves impressive performance, outperforming even larger dense models like DeepSeekMoE-16B and Llama2-13B-Chat. The authors conduct extensive experiments to provide insights into training MoE language models and overtrain OLMOE-1B-7B for 5T tokens, making it the best testbed for researching performance saturation of MoEs compared to dense models. By releasing the model weights, training data, code, and logs, OLMOE-1B-7B facilitates further research and helps uncover the optimal configuration for incorporating MoEs into future language models.
What's next? The fully open-source release of OLMOE-1B-7B is a significant step towards making state-of-the-art MoE models more accessible and encouraging further research in this area. As the field continues to explore the potential of MoEs, we can expect to see new iterations of OLMOE and other open-source MoE models that aim to close the performance gap between frontier models and fully open models. With more researchers and developers able to experiment with and build upon high-quality MoE architectures, we may see a shift towards wider adoption of MoEs in future language models, potentially leading to more efficient and scalable solutions.
3. Meet Yi-Coder: A Small but Mighty LLM for Code
Watching: Yi-Coder (blog/code)

What problem does it solve? Yi-Coder is a series of open-source code LLMs that deliver state-of-the-art coding performance with fewer than 10 billion parameters. It addresses the need for efficient and high-performing code LLMs that can handle long-context modeling and excel in various coding tasks such as code generation, editing, completion, and mathematical reasoning. Yi-Coder aims to push the boundaries of small code LLMs and unlock use cases that could accelerate and transform software development.
How does it solve the problem? Yi-Coder leverages a combination of techniques to achieve its impressive performance. It is trained on a vast repository-level code corpus sourced from GitHub and code-related data filtered from CommonCrawl, amounting to 2.4 trillion high-quality tokens across 52 major programming languages. Additionally, Yi-Coder employs long-context modeling with a maximum context window of 128K tokens, enabling project-level code comprehension and generation. Despite its relatively small size (1.5B and 9B parameters), Yi-Coder outperforms larger models in various coding benchmarks and tasks.
What's next? The open-source release of Yi-Coder 1.5B/9B, in both base and chat versions, presents exciting opportunities for the community to explore and integrate these powerful code LLMs into their projects. Developers can leverage Yi-Coder's capabilities to enhance software development processes, automate coding tasks, and push the boundaries of what small code LLMs can achieve. The Yi-Coder team encourages developers to explore the provided resources, such as the Yi-Coder README, and engage with the community through Discord or email for inquiries and discussions.
Papers of the Week:
Configurable Foundation Models: Building LLMs from a Modular Perspective
Bioinformatics Retrieval Augmentation Data (BRAD) Digital Assistant
ChartMoE: Mixture of Expert Connector for Advanced Chart Understanding