
🕵️ The Dawn of Foundation Agents
And how symbolic expressions can help LLMs with reasoning

In this issue:
From foundation models to foundation agents
Symbolic expressions meet CoT
When fine-tuning on new knowledge goes wrong

1. Foundation Agents as the Paradigm Shift for Decision Making
Watching: Foundation Agents (paper)

What problem does it solve? Foundation models like large language models (LLMs) have demonstrated remarkable adaptability to various tasks with minimal fine-tuning. However, decision-making agents often struggle with sample efficiency and generalization due to the complex interplay between perception, memory, and reasoning required to determine optimal policies. The authors propose the development of foundation agents as a paradigm shift in agent learning, drawing inspiration from the success of LLMs.
How does it solve the problem? The proposed foundation agents are characterized by their ability to rapidly adapt to new tasks, similar to LLMs. The roadmap for creating foundation agents involves collecting or generating large interactive datasets, employing self-supervised pretraining and adaptation techniques, and aligning the agents' knowledge and values with those of LLMs. By leveraging the strengths of foundation models, agents can potentially overcome the challenges of sample efficiency and generalization.
What's next? The authors outline critical research questions and trends for foundation agents, addressing both technical and theoretical aspects. They emphasize the need for real-world use cases to drive the development and evaluation of these agents. As the field progresses, foundation agents may revolutionize decision-making processes by enabling more comprehensive and impactful solutions, ultimately leading to agents that can effectively navigate complex environments and adapt to novel situations.
2. Faithful Logical Reasoning via Symbolic Chain-of-Thought
Watching: SymbCoT (paper/code)
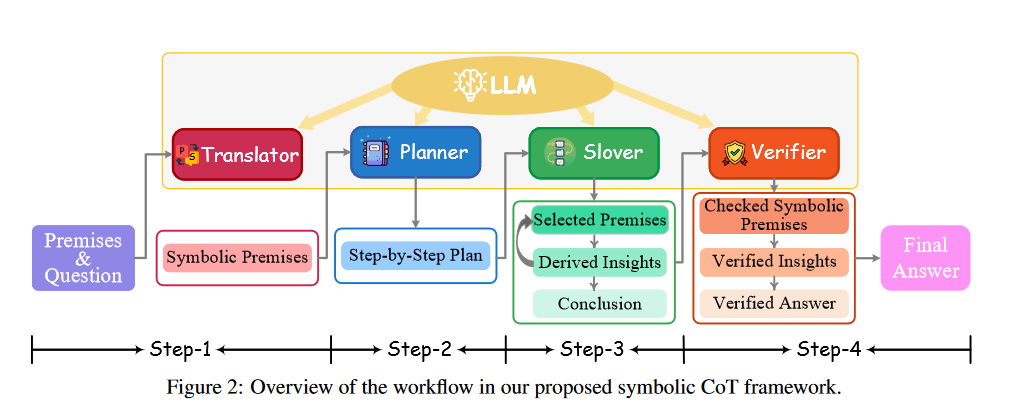
What problem does it solve? Chain-of-Thought (CoT) prompting has been a popular approach for enhancing the reasoning capabilities of Large Language Models (LLMs). However, CoT still struggles with tasks that heavily rely on symbolic expressions and strict logical deduction rules. While LLMs excel at understanding and generating natural language, they often lack the ability to perform rigorous logical reasoning in a symbolic manner.
How does it solve the problem? SymbCoT addresses this limitation by integrating symbolic expressions and logic rules into the CoT prompting framework. It consists of three key steps: 1) Translating the natural language context into a symbolic format, 2) Deriving a step-by-step plan to solve the problem using symbolic logical rules, and 3) Employing a verifier to check the correctness of the translation and reasoning chain. By incorporating symbolic representations and explicit logical reasoning steps, SymbCoT enables LLMs to handle tasks that require strict adherence to logical deduction rules.
What's next? Future research could explore expanding the range of symbolic expressions and logic systems that can be integrated with CoT prompting. Additionally, investigating the scalability and generalizability of SymbCoT to more complex and diverse reasoning tasks would be valuable. As LLMs continue to advance, the combination of symbolic reasoning and natural language understanding could lead to more faithful, flexible, and explainable AI systems capable of tackling a wider range of logical reasoning challenges.
3. Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
Watching: Fine-Tuning on New Knowledge (paper)

What problem does it solve? Large Language Models (LLMs) are known to be inconsistent in their outputs and sometimes "hallucinate" facts that are not grounded in reality. This is a major issue for applications that require factual accuracy, such as question answering systems or chatbots providing information to users. The problem is often attributed to the fine-tuning process, where the model is exposed to new information that may contradict its pre-existing knowledge acquired during pre-training.
How does it solve the problem? The researchers designed a controlled experiment to study the impact of introducing new factual knowledge during fine-tuning on the model's ability to utilize its pre-existing knowledge. They focused on closed-book question answering and varied the proportion of fine-tuning examples that introduce new knowledge. The results show that LLMs struggle to acquire new factual knowledge through fine-tuning, as examples with new knowledge are learned significantly slower than those consistent with the model's pre-existing knowledge. However, as the model eventually learns the examples with new knowledge, it linearly increases the model's tendency to hallucinate incorrect facts.
What's next? The findings highlight the risk of introducing new factual knowledge through fine-tuning and suggest that LLMs primarily acquire factual knowledge during pre-training, while fine-tuning teaches them to use it more efficiently. This has important implications for the development of LLMs and their applications. Researchers and practitioners should be cautious when introducing new facts during fine-tuning and consider alternative approaches, such as using retrieval-based methods or explicitly separating the acquisition of new knowledge from the fine-tuning process. Future work could explore techniques to mitigate the risk of hallucination and improve the model's ability to incorporate new knowledge without compromising its pre-existing knowledge.
Papers of the Week:
Similarity is Not All You Need: Endowing Retrieval Augmented Generation with Multi Layered Thoughts
GNN-RAG: Graph Neural Retrieval for Large Language Model Reasoning
Why Larger Language Models Do In-context Learning Differently?
OptLLM: Optimal Assignment of Queries to Large Language Models
MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning
Foundation agents leverage LLM strengths for better decision-making, addressing efficiency and generalization. Future research will explore real-world applications to enhance these agents further.