
🤯 The Best AI Agent Nobody Is Talking About
Learn about Alita, rStar-Coder, and QwenLong-L1
Welcome, Watcher! This week, we're exploring three research highlights that reimagine how AI systems evolve, learn, and scale - moving us away from rigid, pre-engineered solutions toward more adaptive, self-improving intelligence.
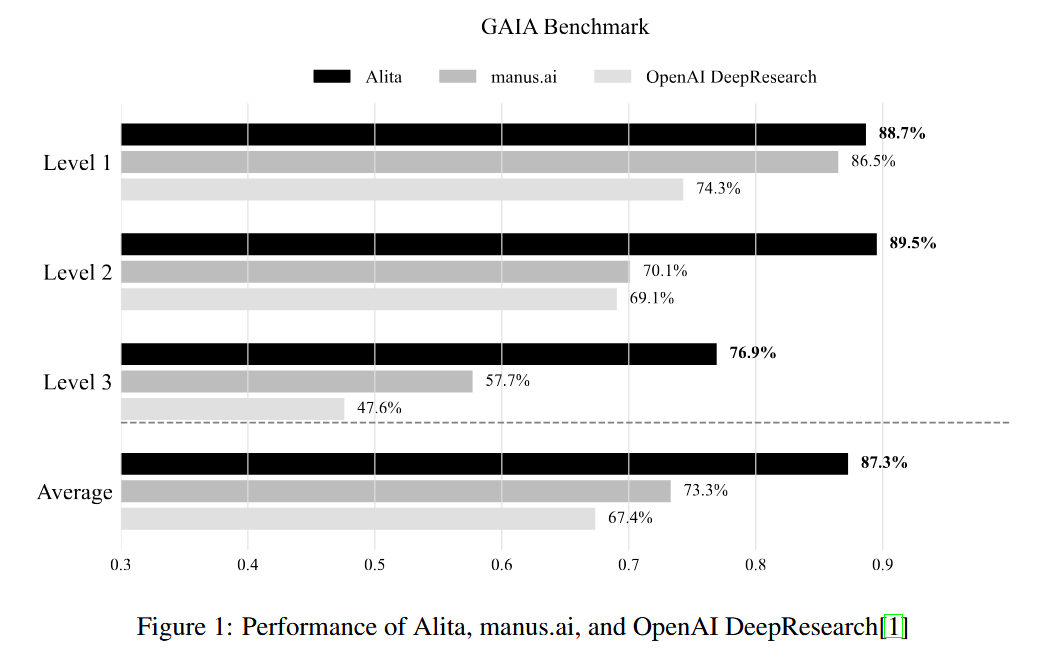
First up, Alita challenges the entire paradigm of AI agent design. Rather than pre-loading agents with countless specialized tools like a bloated Swiss Army knife, Alita starts with just a web agent and teaches itself to create new tools on demand. This minimalist approach not only achieved #1 ranking on the GAIA benchmark but also generated reusable tools that tripled the performance of smaller models - proving that simplicity paired with self-evolution beats complexity.
Next, rStar-Coder tackles the data scarcity problem in competitive programming head-on. Through a clever mutual verification mechanism where multiple solutions cross-check each other, they synthesized high-quality training data that enabled a 7B model to outperform its own 32B teacher. This shows that smart data generation can be more powerful than simply scaling model size, democratizing access to state-of-the-art code reasoning.
Finally, QwenLong-L1 extends the reasoning revolution to long contexts - up to 120K tokens. Using progressive context scaling and curriculum-guided reinforcement learning, they created models that can maintain deep reasoning capabilities while processing entire books or research papers, matching the performance of Claude-3.5-Sonnet-Thinking and opening doors to AI systems that can truly engage with information-intensive real-world tasks.
The underlying trend: We're witnessing a shift from manual engineering to self-organizing intelligence. Whether it's agents building their own tools, models generating their own training data, or systems learning to handle progressively complex contexts, the future belongs to AI that evolves and improves itself.
Don't forget to subscribe to never miss an update again!
1. Alita: Generalist Agent Enabling Scalable Agentic Reasoning with Minimal Predefinition and Maximal Self-Evolution
Watching: Alita (paper/code soon)
What problem does it solve? Most AI agents today are like Swiss Army knives - they come pre-loaded with dozens of specialized tools and carefully designed workflows for different tasks. While this sounds great in theory, it creates a fundamental bottleneck: developers can't possibly anticipate and pre-build every tool an agent might need in the real world. This manual engineering approach severely limits how well these agents can adapt to new situations, scale to different domains, or creatively solve problems they weren't explicitly programmed for. Think of it like trying to pack for every possible scenario on a world trip - you'd need an impossibly large suitcase.
How does it solve the problem? The researchers took a radically different approach with Alita, following Leonardo da Vinci's principle that "simplicity is the ultimate sophistication." Instead of pre-loading the agent with countless tools, they gave it just one core capability (a web agent) and taught it to build its own tools on the fly. Alita uses Model Context Protocols (MCPs) - think of these as standardized blueprints that help the agent create, package, and reuse new capabilities as needed. When faced with a task, Alita searches for relevant open-source code, generates appropriate tools, tests them in isolated environments, and saves successful ones for future use. It's like teaching someone to fish rather than giving them a freezer full of pre-caught fish.
What are the key findings? Despite having minimal built-in tools, Alita achieved remarkable performance across multiple benchmarks. On the challenging GAIA benchmark, it scored 75.15% on first attempt and 87.27% within three attempts, ranking #1 among all general-purpose agents tested. It also performed impressively on specialized tasks: 74% accuracy on MathVista (visual math problems) and 52% on PathVQA (medical visual questions). Perhaps most intriguingly, the tools Alita creates can be reused by other agents - when smaller, less capable models used Alita's generated tools, their performance improved dramatically, with Level 3 (hardest) problems showing a 3x improvement from 3.85% to 11.54% accuracy.
Why does it matter? Their results fundamentally challenge how we think about building AI agents. Rather than the current paradigm of ever-increasing complexity and manual engineering, Alita proves that giving agents the ability to evolve and create their own tools leads to better performance and adaptability. This has massive implications for the future of AI development - instead of armies of engineers hand-crafting tools for every possible scenario, we can build simpler systems that grow their own capabilities. It's also a form of knowledge distillation: powerful models can generate tools that help weaker models perform better, democratizing access to advanced AI capabilities without requiring everyone to run expensive, large models.
2. rStar-Coder: Scaling Competitive Code Reasoning with a Large-Scale Verified Dataset
Watching: rStar-Coder (paper/code)
What problem does it solve? Teaching AI to solve complex programming problems is like trying to train a pianist without access to challenging sheet music. While Large Language Models have shown promise in code generation, their ability to tackle competition-level programming problems - the kind that require deep algorithmic thinking and efficient implementations - is severely hampered by a critical bottleneck: the scarcity of high-quality training data. Unlike math problems where you can verify answers with simple rule-based matching, code solutions need to be executed against diverse test cases that catch logical errors, edge cases, and efficiency issues. Think of it like the difference between checking if 2+2=4 versus ensuring a sorting algorithm works correctly for arrays of different sizes, with duplicates, empty arrays, and millions of elements.
How does it solve the problem? rStar-Coder eses a clever three-pronged approach. First, the researchers collected 37.7K expert-written competitive programming problems as seeds and used them to synthesize new, solvable problems - but instead of just asking an LLM to create variations, they included the original solution to help the model understand the core algorithmic concepts being tested. Second, they tackled the test case generation challenge by breaking it into manageable pieces: they prompted GPT-4o to create utility functions that generate valid inputs of varying complexity (from 100 to 10^5 elements) and validate them against problem constraints. Third, they introduced a "mutual verification" mechanism - they generated multiple solutions using a strong reasoning model (QWQ-32B) and only accepted test cases where the majority of solutions agreed on the outputs. It's like having multiple experts solve a problem independently; if they all arrive at the same answer, you can be confident it's correct.
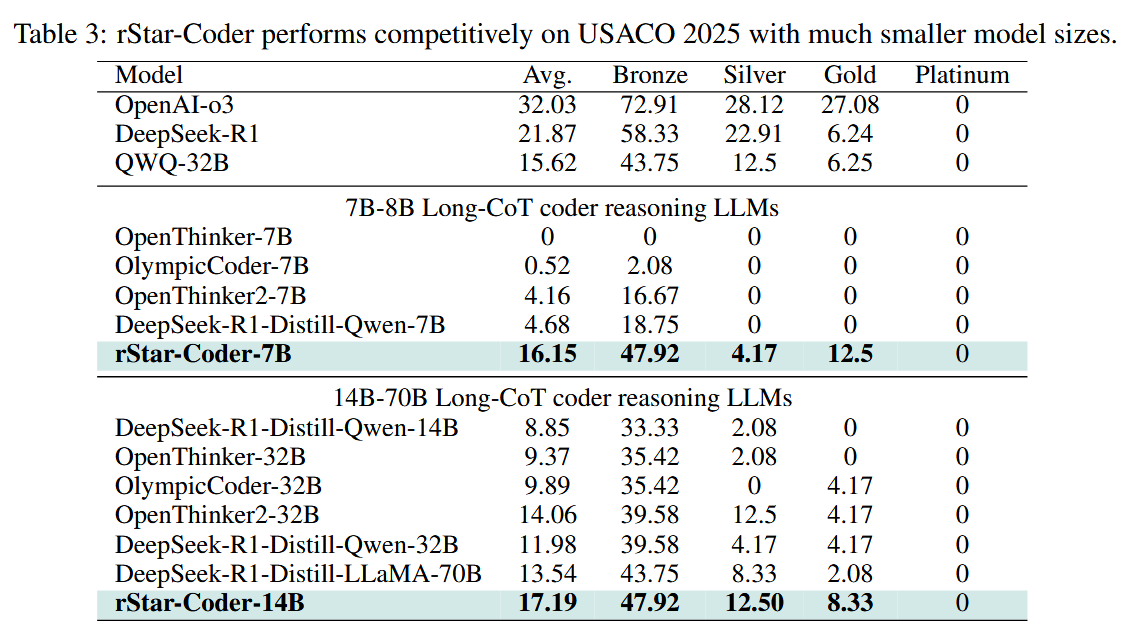
What are the key findings? rStar-Coder dramatically improved code reasoning capabilities, with the Qwen2.5-7B model jumping from 17.4% to 57.3% on LiveCodeBench, and the 14B version reaching 62.5%, actually beating OpenAI's o3-mini by 3.1%. On the notoriously difficult USA Computing Olympiad benchmark, their 7B model achieved 16.15% accuracy, outperforming the much larger QWQ-32B model - particularly impressive since QWQ-32B was the very model used to generate their training solutions. The approach also proved that quality trumps quantity: despite using fewer examples (580K) than competitors like OCR (736K) and OpenThinker2 (1M), rStar-Coder consistently outperformed them. Even more surprisingly, models trained on this competition-focused dataset generalized remarkably well to standard code generation tasks, with the 7B model matching Claude 3.5 Sonnet's performance on benchmarks like HumanEval.
Why does it matter? These results have the potential to shift the paradigm for training code reasoning models. Rather than the endless arms race of creating ever-larger models or manually crafting millions of examples, rStar-Coder proves that a well-designed data generation pipeline can enable smaller models to punch far above their weight class. The mutual verification mechanism is particularly clever - it essentially bootstraps reliability from uncertainty, creating a virtuous cycle where models can verify their own synthetic data. This has massive practical implications: organizations without access to frontier-scale compute can now train highly capable code reasoning models, democratizing access to advanced AI capabilities. Perhaps most intriguingly, the fact that a 7B model can outperform the 32B teacher model that helped create its training data suggests we're only scratching the surface of what's possible with intelligent data synthesis and verification.
3. QwenLong-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning
Watching: QwenLong-L1 (paper/code)
What problem does it solve? While recent large reasoning models (LRMs) like OpenAI's o1 have shown impressive reasoning capabilities through reinforcement learning, these improvements have been limited to short-context tasks (around 4K tokens). The challenge is that extending these models to handle long-context inputs (120K+ tokens) while maintaining robust reasoning capabilities remains unsolved. This is particularly problematic for real-world applications that require processing extensive documents, conducting deep research, or working with information-intensive environments where models need to both retrieve relevant information from long contexts and perform multi-step reasoning.
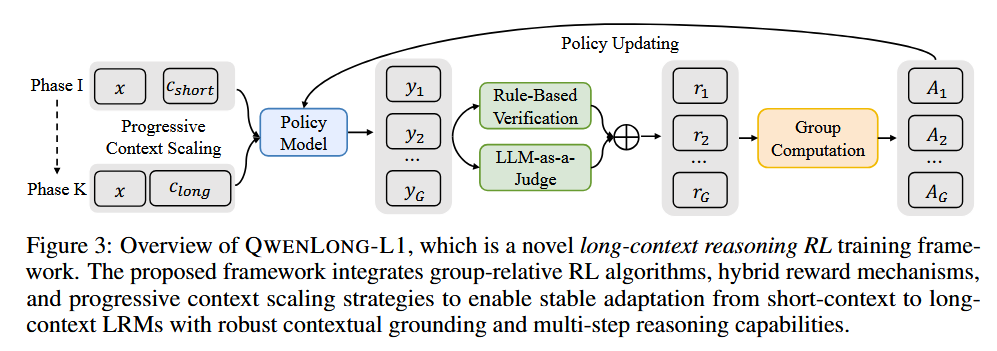
How does it solve the problem? QwenLong-L1 is a progressive context scaling framework that systematically adapts short-context reasoning models to long-context scenarios. Their approach includes three key components: first, a warm-up supervised fine-tuning (SFT) stage to establish a robust initial policy; second, a curriculum-guided phased RL technique that gradually increases context length across training phases to stabilize optimization; and third, a difficulty-aware retrospective sampling strategy that prioritizes challenging examples to encourage policy exploration. They also implemented hybrid reward mechanisms combining rule-based verification with LLM-as-a-judge evaluation to balance precision and recall.
What are the key findings? QwenLong-L1 achieved leading performance across seven long-context document question-answering benchmarks, with the 32B model outperforming flagship models like OpenAI-o3-mini and Qwen3-235B-A22B, even matching Claude-3.7-Sonnet-Thinking's performance. The research revealed that progressive context scaling enables higher entropy and stabilizes KL divergence during training, while RL naturally fosters specialized long-context reasoning behaviors like grounding, subgoal setting, backtracking, and verification that boost final performance.
Why does it matter? This is making LRMs practically useful for real-world applications requiring extensive context processing. The work provides the first systematic framework for long-context reasoning RL, addressing critical challenges in training efficiency and optimization stability. This advancement opens doors for AI systems capable of conducting automated scientific research, analyzing long videos, and handling complex information-intensive tasks that require both contextual grounding and sophisticated reasoning across vast amounts of information.

Papers of the Week:
REARANK, a listwise reasoning LLM agent, enhances interpretability and reranking in information retrieval with reinforcement learning and data augmentation from only 179 annotated samples. REARANK-7B (Qwen2.5-7B) rivals GPT-4 on in-domain/out-of-domain benchmarks, exceeding it on BRIGHT. The research highlights reinforcement learning's ability to improve LLM reasoning.
LLMs automate reasoning via formal specifications, but probabilistic outputs clash with formal verification. Analyzing failure modes and UQ, the paper shows SMT's domain-specific impact; token probability entropy fails as a UQ method. A probabilistic context-free grammar (PCFG) framework reveals task-dependent uncertainty. Fusing signals enables selective verification, reducing errors with minimal abstention, creating reliable LLM formalization.
The multi-agent THiNK framework, grounded in Bloom's Taxonomy, evaluates LLM higher-order thinking via iterative problem generation and reflection. LLMs perform well in lower-order categories but struggle applying knowledge in realistic contexts and exhibit abstraction limitations. Feedback enhances reasoning, aligning outputs with domain logic and problem structure. THiNK offers a scalable evaluation method for probing and enhancing LLM reasoning, grounded in learning science. Code is on GitHub.
Enhancing LLMs for reasoning-intensive tasks requires costly reinforcement learning (RL) with verifiable signals or supervised fine-tuning (SFT) using chain-of-thought (CoT). This paper explores incentivizing LLM reasoning through weaker supervision. Weak reasoners improve performance, achieving 94% of RL gains across diverse benchmarks and model architectures. The weak-to-strong paradigm offers a cost-effective alternative for incentivizing strong reasoning.
LLMs need temporal reasoning and planning. The Temporal Constraint-based Planning (TCP) benchmark jointly assesses these skills using dialogues about a collaborative project, requiring an optimal schedule under temporal constraints. TCP uses problem prototypes paired with realistic scenarios; a human quality check is performed. Analysis of failure cases reveals limitations in LLMs' planning abilities.
When Large Language Models backtrack and correct themselves mid-reasoning, conventional wisdom suggests they're being inefficient. Bayes-Adaptive RL (BARL) reframes the problem using Bayes-Adaptive RL, which treats each reasoning path as a hypothesis about the correct approach. The model maintains uncertainty over which strategy will work and uses feedback to eliminate incorrect hypotheses.
An online self-training reinforcement learning algorithm scales LLMs without human supervision (bypassing automated verification) using self-consistency for correctness signals. Applied to mathematical reasoning, the algorithm rivals reinforcement learning with gold-standard answers. However, reward hacking—favoring confidently incorrect outputs via the proxy reward—remains a key challenge.