
Papers You Should Know About
Get ahead of the curve with LLM Watch
This week in AI, researchers are simplifying complex training pipelines, introducing novel model architectures beyond Transformer attention, and empowering AI agents to learn and reason on their own. We also see a push for real-world deployment: from open-sourced efficient LLMs to agents that self-improve in code and recommendation systems.
Below is a roundup of noteworthy papers, each with a brief summary of its contributions and results.

Fastest way to become an AI Engineer? Building things yourself!
Get hands-on experience with Towards AI’s industry-focused course: From Beginner to Advanced LLM Developer (≈90 lessons). Built by frustrated ex-PhDs & builders for real-world impact.
Build production-ready apps: RAG, fine-tuning, agents
Guidance: Instructor support on Discord
Prereq: Basic Python
Outcome: Ship a certified product
Guaranteed value: 30-day money-back guarantee
Pro tip: Both this course and LLM Watch might be eligible for your company’s learning & development budget.
Step-DeepResearch Technical Report (paper)
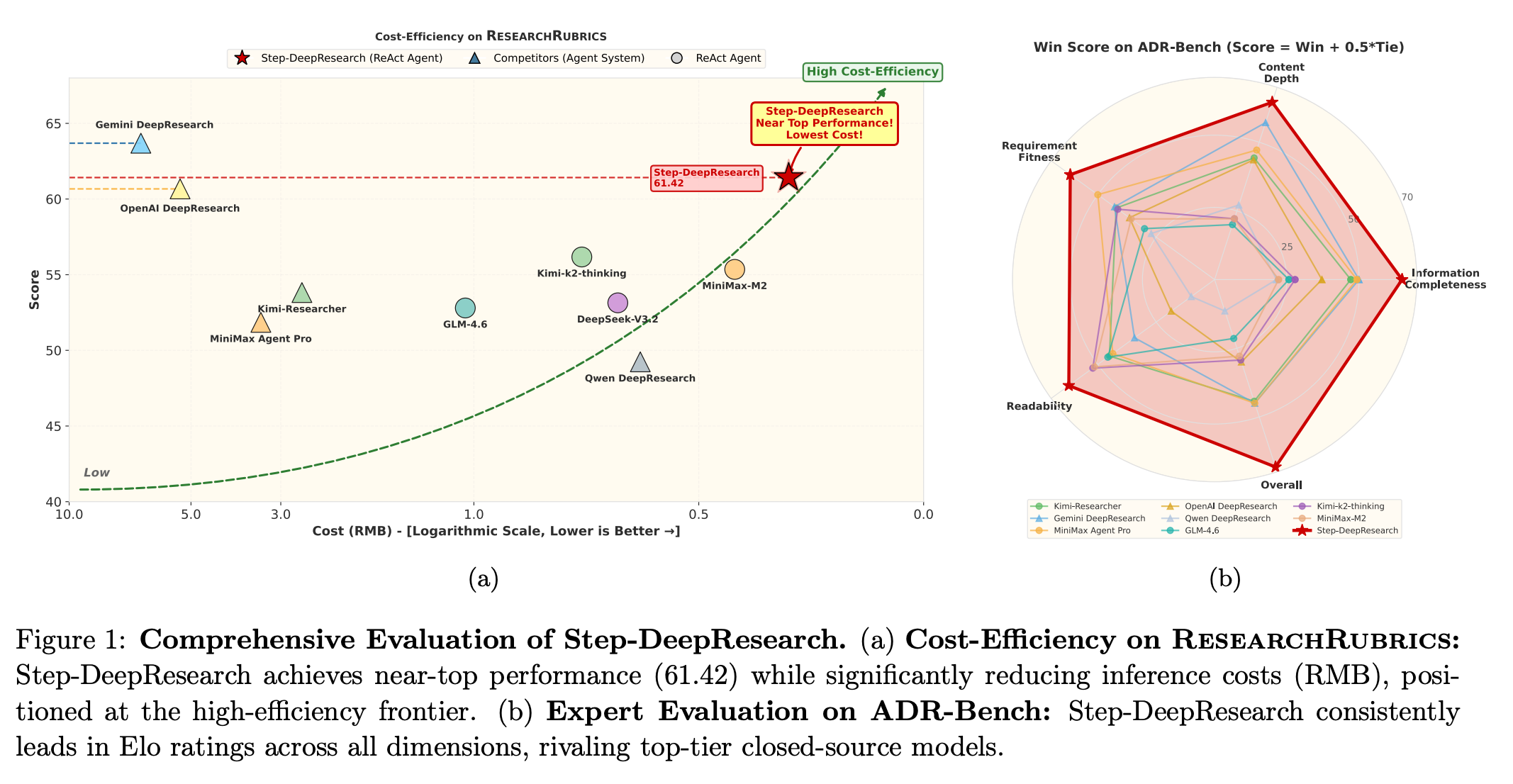
A team at StepFun presents Step-DeepResearch, an autonomous “Deep Research” agent designed to perform open-ended research tasks like a human expert. Built on a 32-billion-parameter LLM, it internalizes various research skills (planning, information seeking, cross-checking, report writing) instead of relying on external tools. Impressively, it scored 61.42 on the ResearchRubrics benchmark - second overall, edging out OpenAI’s DeepResearch system - while running at one-tenth the cost of other top models. The system also introduces a new ADR-Bench to evaluate complex real-world queries (including Chinese language tasks) for more comprehensive benchmarking.
NVIDIA Nemotron 3: Efficient and Open Intelligence (paper)
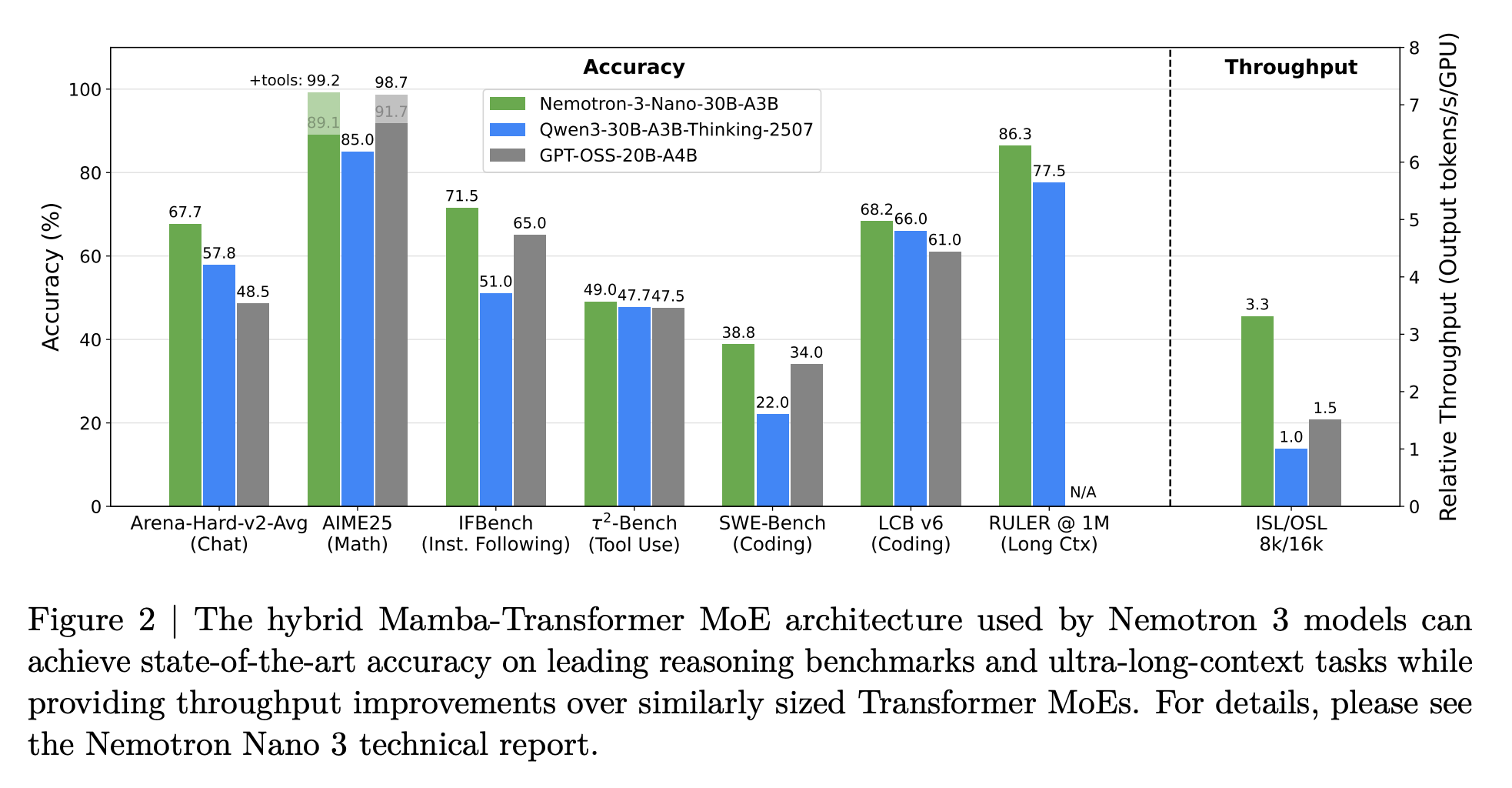
NVIDIA’s latest release, Nemotron 3, is a family of large language models built with a hybrid Mixture-of-Experts (MoE) Transformer architecture (“Mamba-Transformer”). These models deliver up to 3.3x higher inference throughput than typical Transformers and support an unprecedented 1 million tokens of context window. Despite the efficiency boosts, Nemotron 3 matches state-of-the-art accuracy on complex, agent-driven tasks. In the spirit of open science, NVIDIA has open-sourced the model weights, training code, recipes, and over 10 trillion tokens of training data, making this a significant push toward more accessible high-performance LLMs.
MemEvolve: Meta-Evolution of Agent Memory Systems (paper)
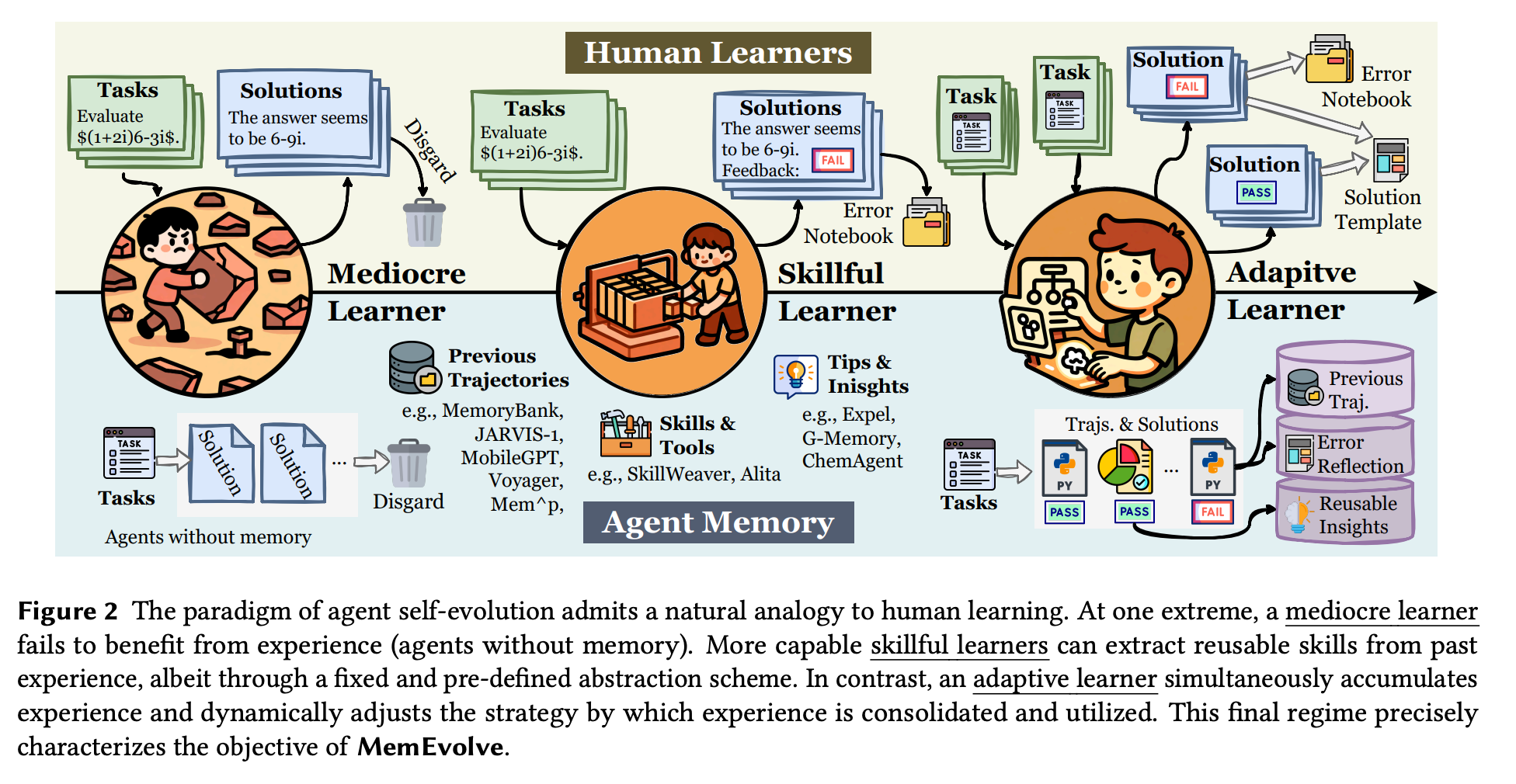
Researchers from OPPO and NUS introduce MemEvolve, a framework that lets AI agents learn to improve their own memory modules over time. The idea is a meta-evolutionary loop: the agent’s memory architecture (how it stores and recalls information) is itself continuously optimized as the agent solves tasks. In experiments, LLM-based agents using MemEvolve achieved up to +17% better task performance after refining their memory system. Even more, this improvement generalized across different tasks, base models, and agent frameworks. In short, giving agents the ability to evolve their memory makes them more adaptable and effective learners.
From Word to World: Can Large Language Models be Implicit Text-based World Models? (paper)

This study (University of Edinburgh & Microsoft Research) asks if an LLM can serve as a world model - in other words, can it internally simulate how a textual environment changes in response to actions? The authors show that with supervised fine-tuning, LLMs can indeed make accurate next-state predictions and maintain long-horizon consistency in text-based simulations. These implicit world-model LLMs significantly improved the learning of AI agents: they can generate synthetic experiences for an agent to learn from, act as safe “what-if” simulators to test strategies, and help bootstrap reinforcement learning policies. This suggests a new role for LLMs as environment simulators that furnish agents with common sense and foresight without needing explicit physics or game engines.
PHOTON: Hierarchical Autoregressive Modeling for Lightspeed and Memory-Efficient Language Generation (paper)
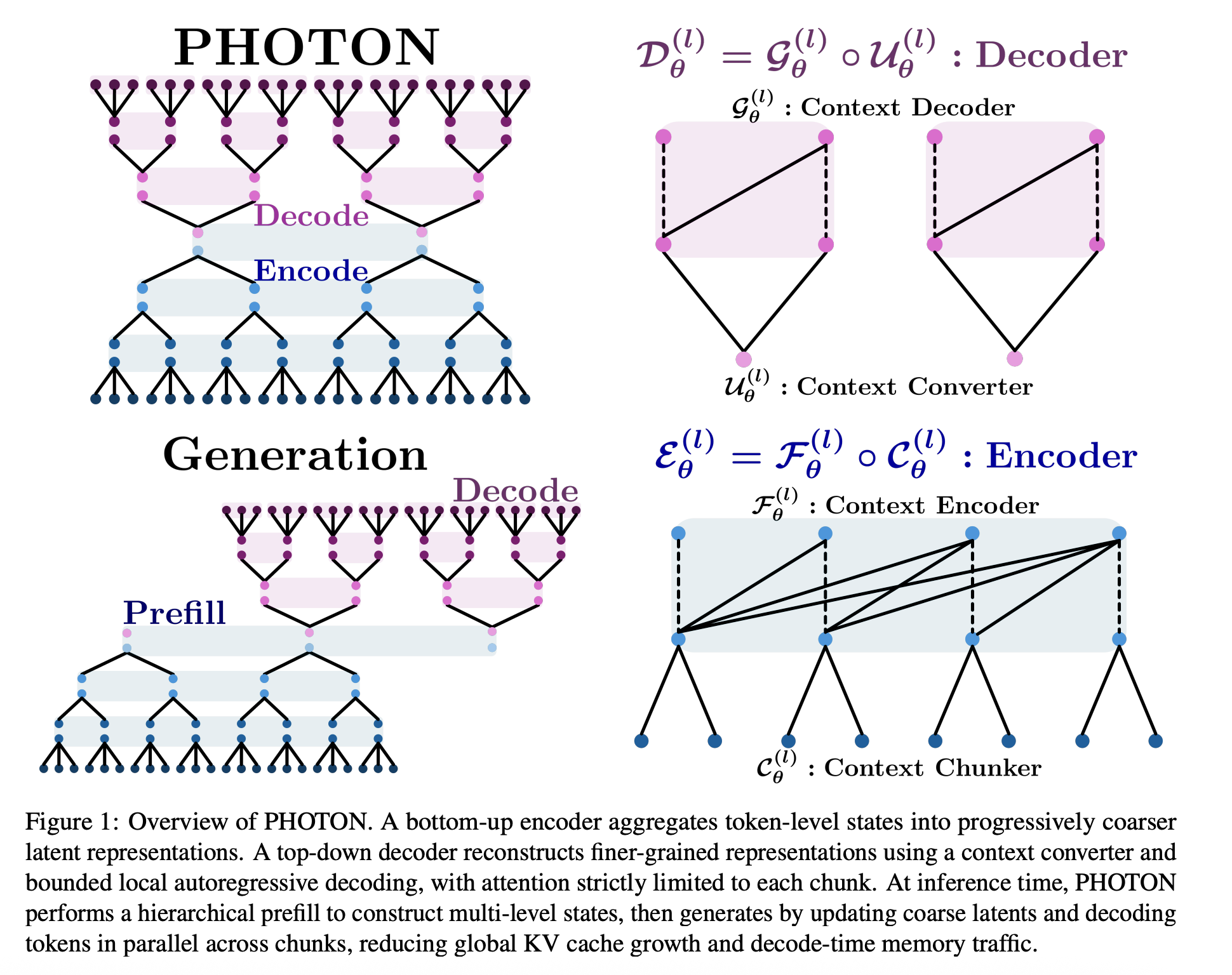
Fujitsu and collaborators unveil PHOTON, a hierarchical language generation approach that tackles the inefficiencies of standard Transformers. Instead of processing every token at full detail, PHOTON uses a multi-scale encoder: it compresses tokens into coarser groups as context grows, so the model “reads” long texts by remembering summaries of earlier content. This design slashes the memory and time needed for generation - a 600M-parameter PHOTON model achieved an astounding 416× higher throughput-per-memory than a vanilla Transformer. Despite the speedup, it maintained comparable language modeling quality. By reducing heavy KV-cache usage (the stored key/value vectors from past tokens), PHOTON enables ultra-fast inference for long sequences without the usual memory bottleneck.
Toward Training Superintelligent Software Agents through Self-Play SWE-RL (paper)
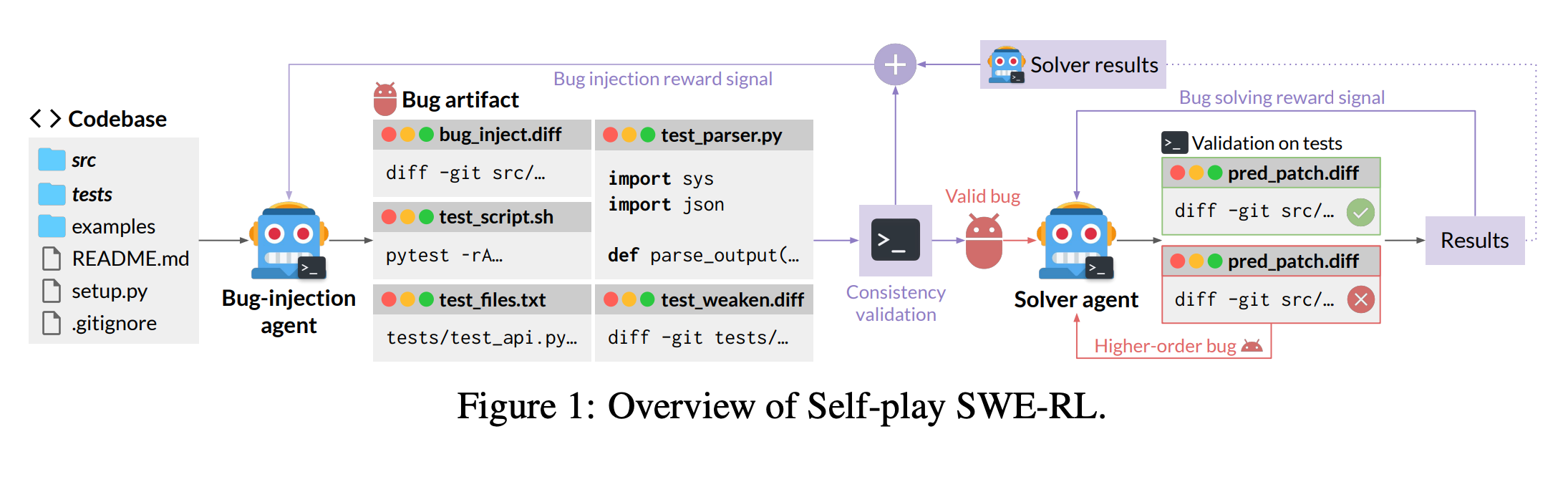
How can we train AI agents to write and debug code beyond human-provided examples? This paper proposes Self-play SWE-RL (SSR), a method where a single coding agent plays both the attacker and solver. In a sandboxed repo, the agent first introduces a bug into the code, then tries to fix it - iteratively generating harder challenges for itself. This self-play training required no human-written issues or tests. On two software engineering benchmarks (SWE-Bench), the SSR-trained agent showed substantial self-improvement, gaining +10.4 and +7.8 points and outperforming a baseline that used human data throughout trainingemergentmind.com. These early results hint at a path to autonomously improving software agents: an AI that gets better by continuously practicing on problems it creates for itself.
MemR3: Memory Retrieval via Reflective Reasoning for LLM Agents (paper)

LLM-based agents augmented with a long-term memory often just retrieve some notes and answer, but this work makes memory use more deliberative. MemR³ (pronounced “MemR-cubed”) adds a decision-making controller that can choose to retrieve, reflect, or answer at each step, and an evidence-gap tracker that monitors what information is still missing. This closed-loop approach means the agent can iteratively pull in facts and verify them before finalizing an answer, instead of one-shot retrieval. In evaluations (LoCoMo benchmark), MemR³ outperformed standard retrieval-augmented baselines, boosting overall QA accuracy. For example, with a GPT-4.1-mini backend it improved a retrieval-augmented generation setup’s score by 7.3% (absolute). MemR³ acts like a “memory coach” for LLM agents, yielding better answers and offering a plug-and-play improvement to existing memory systems.
ReaSeq: Unleashing World Knowledge via Reasoning for Sequential Modeling (paper)
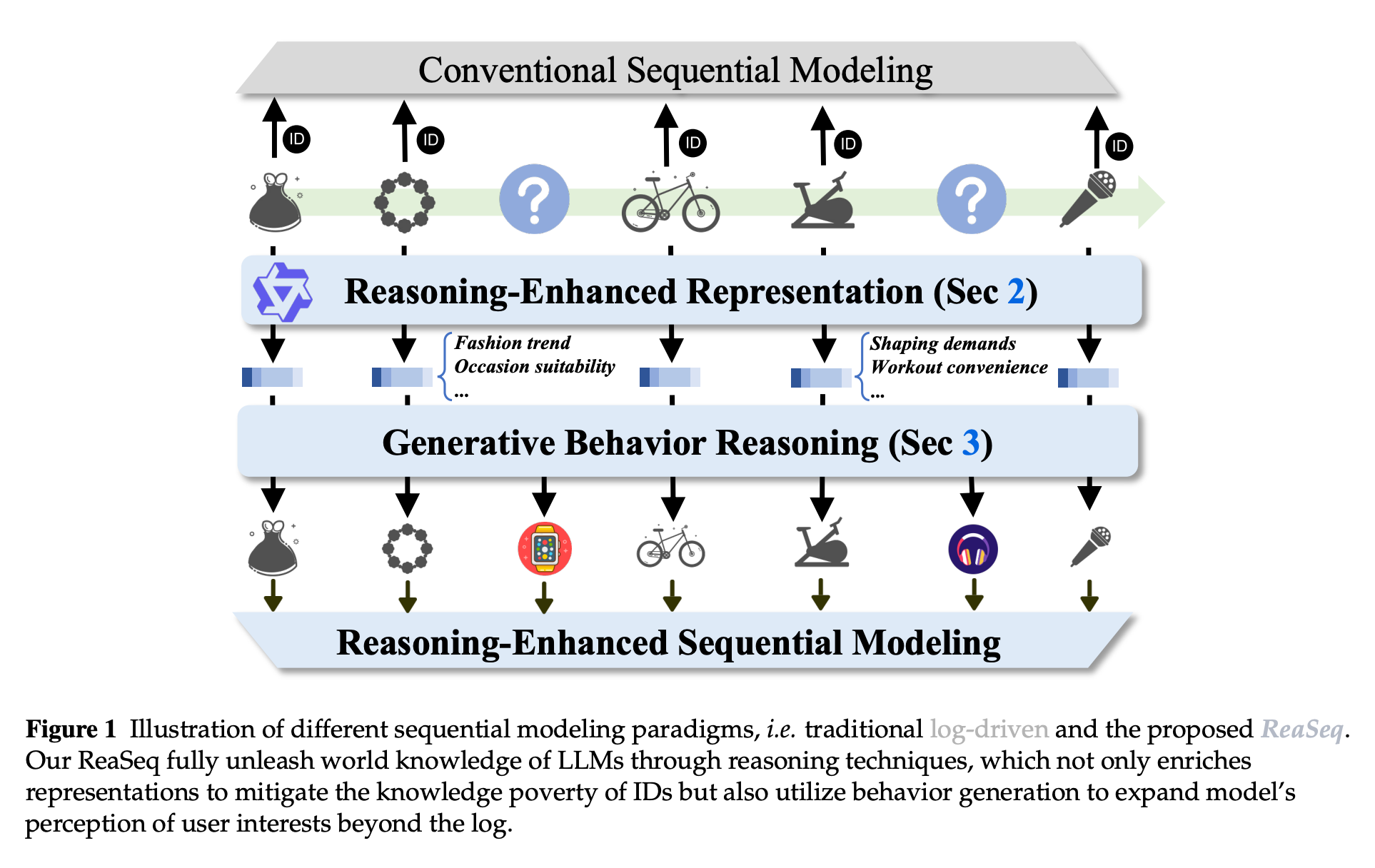
E-commerce recommendation systems usually rely on user interaction history, but they can be “blind” to unobserved interests and lack background knowledge about items. ReaSeq, developed by Alibaba’s TaoRank team, injects LLM-based reasoning into sequential recommender models to address these issues. The system uses an LLM to enrich item representations with world knowledge and to infer potential user interests that haven’t been directly seen. Deployed on Taobao (a major online shopping platform), ReaSeq delivered notable gains: over +6% improvement in click-through rate and page views, and more than +2.5% increase in gross merchandise volume (sales) during live A/B tests. These are significant business metrics, highlighting that incorporating reasoning and external knowledge can tangibly improve recommender performance at scale.
JustRL: Scaling a 1.5B LLM with a Simple RL Recipe (paper)
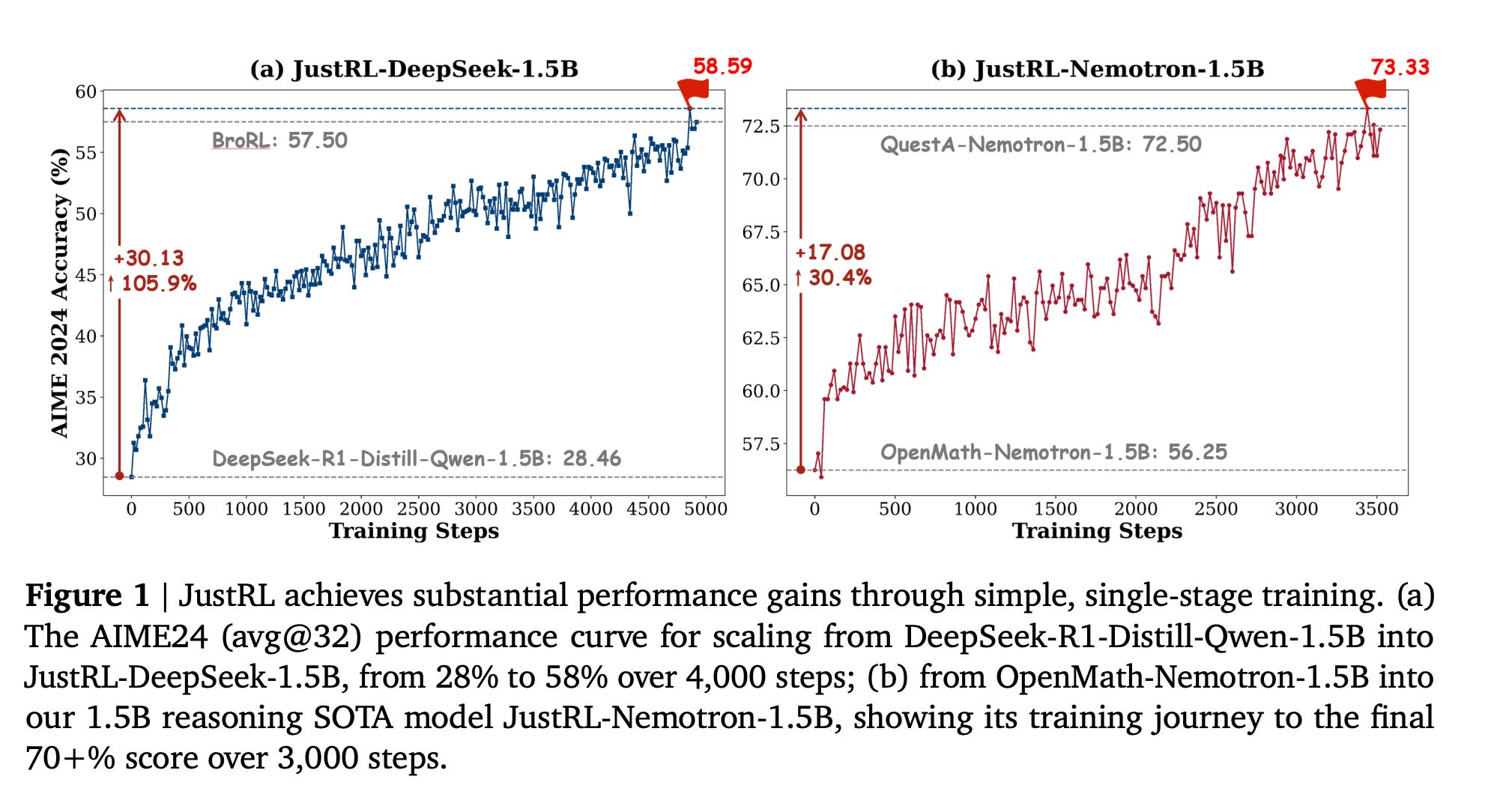
Recent trends in fine-tuning LLMs with reinforcement learning (think RLHF) involve elaborate tricks - multi-stage training, fancy curricula, adjustable reward weights, etc. JustRL is an investigation into how far a minimalist RL approach can go. The authors took a 1.5-billion parameter model and applied a single-stage RL fine-tuning with fixed hyperparameters (no fancy scheduling). The result: state-of-the-art accuracies on math reasoning benchmarks (about 54.9% and 64.3% average accuracy on two models across 9 math tasks) using 2× less compute than more complex pipelines. Training was remarkably stable (smooth improvement over 4,000+ steps with no collapses), and intriguingly, adding commonly used tricks like length penalties or external “verifier” models actually hurt performance by reducing exploration. This suggests that sometimes simplicity is key - a strong baseline with sufficient scale can outperform overly complicated strategies, offering a new baseline for RL-tuned small LMs.

tl;dr
In summary, this week’s papers highlight a dual trend: driving towards efficiency at scale, and pushing toward greater autonomy in AI systems. On one hand, we see efforts to make LLMs faster, lighter, and more broadly accessible - from NVIDIA’s open high-speed model and novel architectures that rethink fundamentals like attention, to simplifications of training that lower the barrier to strong performance. On the other hand, there’s a clear emphasis on LLM-based agents that can do more on their own: they can remember and evolve their own memory systems, simulate environments to learn safer and faster, and even self-train by creating challenges for themselves. All of this points to a future where AI systems are not just more powerful, but also more adaptable and interpretable. As we head into 2026, the community is laying the groundwork for AI that can both think bigger and think smarter - handling longer inputs, operating more efficiently, and taking initiative in its learning process. The convergence of these advances means we can expect AI to become both more scalable and more agentive, expanding the frontier of what autonomous intelligent systems can achieve in the real world.
Was this the last of the "Papers You Should Know About" weekly distribution?