
Papers You Should Know About
Get ahead of the curve with LLM Watch
Welcome, Watcher! This week in LLM Watch:
Scaling laws for reinforcement learning
Unified neural-symbolic languages
Multimodal retrieval frameworks
New training paradigms for agents
Efficient reasoning techniques
Below, we will distill the key ideas and findings of each paper, complete with references to the original sources.
Don’t forget to subscribe to never miss an update again.

Fastest way to become an AI Engineer? Building things yourself!
Get hands-on experience with Towards AI’s industry-focused course: From Beginner to Advanced LLM Developer (≈90 lessons). Built by frustrated ex-PhDs & builders for real-world impact.
Build production-ready apps: RAG, fine-tuning, agents
Guidance: Instructor support on Discord
Prereq: Basic Python
Outcome: Ship a certified product
Guaranteed value: 30-day money-back guarantee
Scaling RL Compute for LLMs Becomes Predictable (paper)
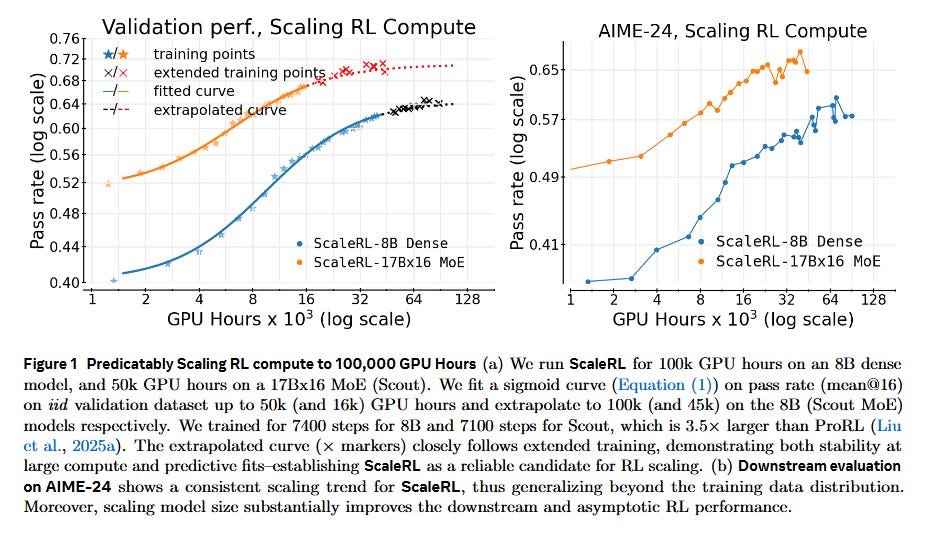
The Art of Scaling Reinforcement Learning Compute for LLMs (Khatri et al., 2025) - Meta AI and UT Austin researchers tackle the “mystery box” of RL fine-tuning for language models. They conduct a 400,000 GPU-hour study and find that RL performance scales in a sigmoid-shaped curve (an S-curve) rather than the open-ended power-law seen in pre-training. Early on, gains are slow, then a phase of rapid improvement, then saturation - meaning additional compute yields diminishing returns. Crucially, this predictable curve allows extrapolating a small-run’s results to a much larger run, bringing much-needed predictability to RL for LLMs. The authors identify that not all RL “recipes” reach the same performance ceiling: some fine-tuning strategies plateau higher than others. They also observe that many design details (loss functions, advantage normalization, data curriculum, off-policy vs on-policy updates) mainly affect compute efficiency (how fast reward improves) without changing the ultimate achievable reward. By combining the best choices from their ablations, they propose a “ScaleRL” recipe of best practices (e.g. using an asynchronous pipeline, a stable loss function called CISPO, FP32 precision at the output layer, adaptive prompt curricula). ScaleRL produced near-ideal sigmoid scaling behavior, allowing a single RL run up to 100k GPU-hours to hit predicted performance targets. Key takeaway: RL fine-tuning can be transformed from trial-and-error art into a more exact science - labs can now forecast how much reward improvement an extra 10× compute will bring, potentially saving time and compute.
Tensor Logic - Unifying Neural and Symbolic AI (paper)

Tensor Logic: The Language of AI (Domingos, 2025) - A bold proposal for a new programming paradigm that bridges deep learning and logic. This paper introduces tensor logic, a minimal yet expressive language designed to serve as a common foundation for neural networks, symbolic reasoning, and probabilistic models. The sole programming construct is the “tensor equation”, based on the insight that logical inference rules can be viewed as tensor operations (Einstein summation) on Boolean tensors. In practice, tensor logic treats relations (as in logic programs) as sparse tensors, and logical rules (like in Datalog) correspond to performing joins and summations on those tensors followed by non-linearities. This means that a transformer attention head, a Prolog rule, a kernel machine, or a factor graph can all be written in the same tensor equation language. By leveraging modern autodiff and GPU compute (similar to PyTorch/TensorFlow), tensor logic promises to support learning and reasoning in one framework. For example, it could enable “sound reasoning in embedding space,” combining neural nets’ pattern recognition with the rigor of logical rules. The author demonstrates how various AI models (MLPs, CNNs, RNNs, transformers, symbolic logic programs, graphical models) can be concisely expressed in tensor logic. If widely adopted, this unified language could eliminate the divide between differentiable AI and symbolic AI, offering both the scalability of tensors and the transparency of logic in a single system.
RAG-Anything: Unified Multimodal Retrieval-Augmented Generation (paper/code)
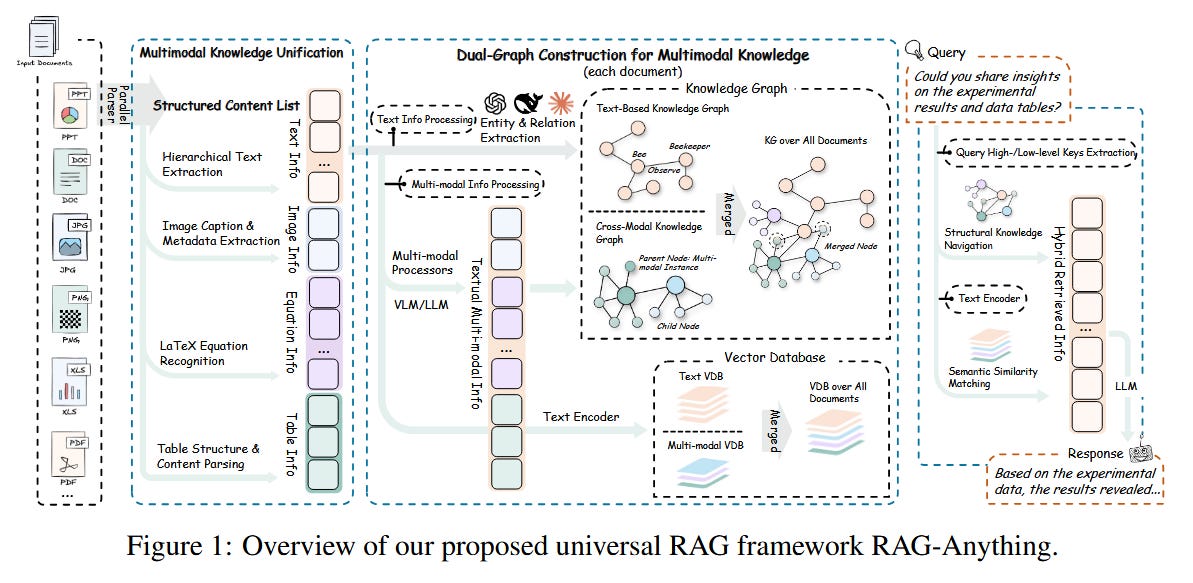
RAG-Anything: All-in-One RAG Framework (Guo et al., 2025) - Extending retrieval-augmented LLMs beyond text. Retrieval-Augmented Generation (RAG) typically allows an LLM to fetch textual documents to overcome knowledge cutoff. However, knowledge in the real world is multimodal - images, tables, charts, math equations - and current RAG systems handle primarily text, missing a lot. This work presents RAG-Anything, a framework enabling LLMs to retrieve and reason over any modality. The key idea is to represent multimodal content (text, visuals, audio, etc.) as interconnected knowledge graphs rather than separate data silos. RAG-Anything builds a dual-graph representation of a knowledge base: one graph captures cross-modal relationships (e.g. an image and its caption or a table and its description), while another captures textual semantic similarity. It then performs a cross-modal hybrid retrieval that combines structural navigation (following links/relationships in the graph) with semantic matching (embedding-based search). This allows the system to fetch evidence that spans multiple modalities in a coherent way. The authors report that RAG-Anything significantly outperforms text-only retrieval on challenging multimodal QA benchmarks. Gains are especially large for long documents that include mixtures of text and figures, where traditional RAG fails to gather the relevant pieces. By eliminating the modality-specific fragmentation in knowledge access, this unified approach lets LLMs use images, diagrams, tables, etc. as seamlessly as text. (The code is open-sourced, signaling a push toward truly multimodal chat assistants.)
Early Experience: Letting Agents Learn by Doing (Without Rewards) (paper)
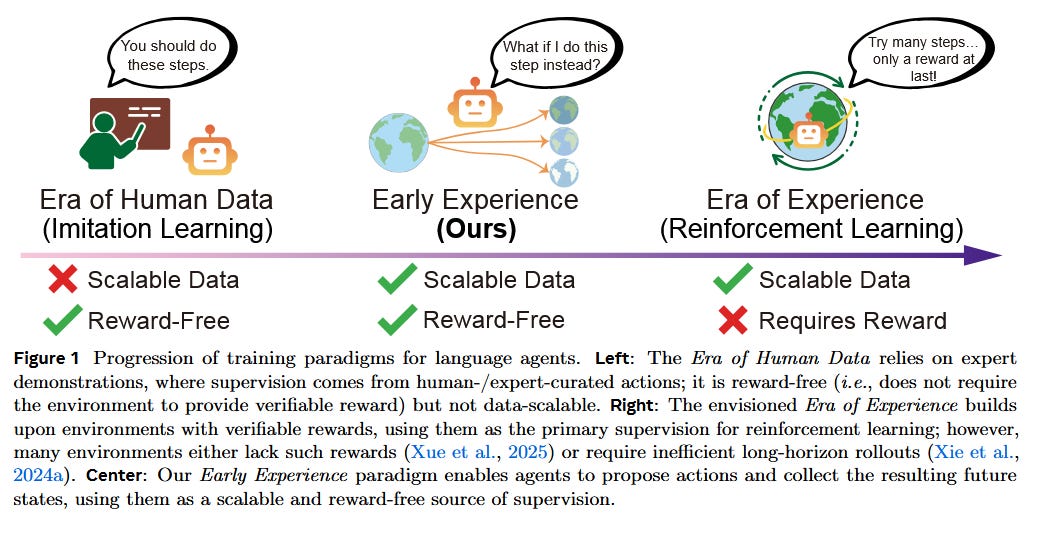
Agent Learning via Early Experience (Zhang et al., 2025) - A new training paradigm from Meta’s AI lab for language agents to bootstrap themselves. Modern LLM-based agents often rely on imitation learning from human demonstrations because true reinforcement learning is hard without well-defined rewards or requires huge trial-and-error rollouts. This paper proposes “early experience” as a middle ground: let the agent loose to interact with the environment without external rewards, and use the resulting states as self-supervision signals. In essence, the agent generates its own trajectories (even if suboptimal) and learns from them in two ways: (1) Implicit world modeling - predicting the future state transitions it will see, to internalize the environment’s dynamics. And (2) self-reflection - analyzing its own actions by generating natural language explanations of what went wrong or could be improved, thereby refining its decision policy. Crucially, all this learning happens without any reward function, purely from the agent’s “experience” of cause and effect. Across eight diverse tasks (web browsing, tool use, navigation, etc.), agents bootstrapped with early experience data outperform those trained only on expert demos, showing better generalization to new situations. For instance, an agent that had a chance to practice in an environment, even without rewards, later performs more robustly than one that only imitated fixed expert trajectories. Moreover, when actual rewards are available, starting from early experience gives a head-start - these agents offer a strong foundation for subsequent RL fine-tuning. This paradigm thus bridges the gap between purely imitation-based agents and fully autonomous RL agents, suggesting that even “reward-free” interaction can substantially improve an AI’s competence and adaptability.
Demystifying RL in Agentic Reasoning: Data, Algorithms, and Strategy (paper/code)
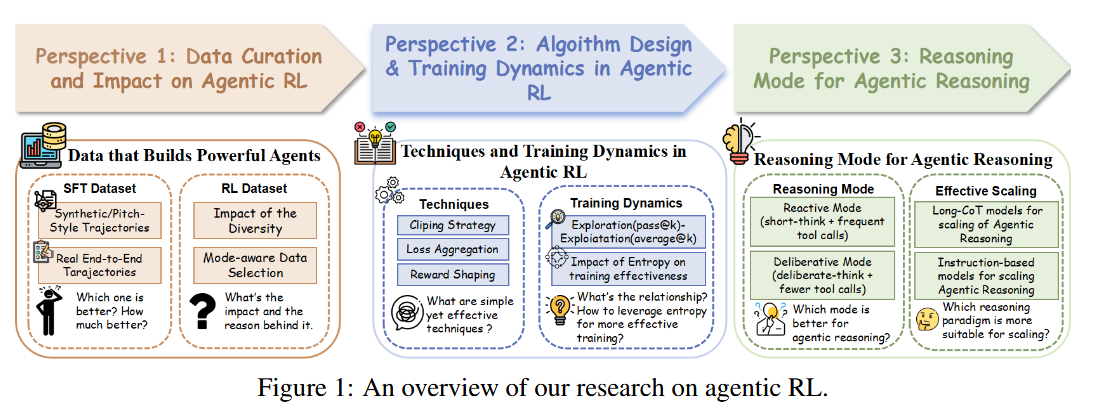
Demystifying Reinforcement Learning in Agentic Reasoning (Yu et al., 2025) - A comprehensive study dissects how to best fine-tune LLMs with RL for complex reasoning tasks. The authors investigate RL-enhanced “agentic” LLMs (models that use tools and multi-step reasoning) along three axes: the training data, the RL algorithm/hyperparameters, and the agent’s reasoning mode. Through extensive experiments, they identify several key practices for success: (i) Use high-quality, real interaction trajectories instead of stitched or simulated ones. Replacing synthetically stitched tool-use sequences with real end-to-end examples led to a much stronger starting model via supervised fine-tuning, and maintaining a diverse, model-aware dataset throughout RL greatly boosted performance. (ii) Apply exploration-friendly RL techniques. The study found that allowing the policy more freedom - e.g. using a higher clipping threshold on advantages, adding gentle reward shaping for long trajectories, and keeping some entropy (randomness) in the policy - is crucial for efficient training. These help the model explore solution paths rather than getting stuck. (iii) Optimize the agent’s reasoning style: A surprising insight is that less can be more - an agent that plans with fewer, more targeted tool calls and avoids overly verbose chain-of-thought actually achieves higher accuracy and tool efficiency. In other words, deliberative reasoning beats constant tool use or endless self-talk in these benchmarks. Implementing these practices, the authors show that even a 4B-parameter model can outperform a 32B model on complex agent benchmarks when using their improved RL recipe. They also release a high-quality dataset (with real tool-usage traces and an RL fine-tuning set) to serve as a strong baseline for future research. All together, this work provides a much-needed empirical guidebook for RLHF-style training of reasoning agents, pinpointing what actually moves the needle in making LLMs more effective decision-makers.
Why RL Fine-Tuning Helps - A Theoretical Perspective (paper)
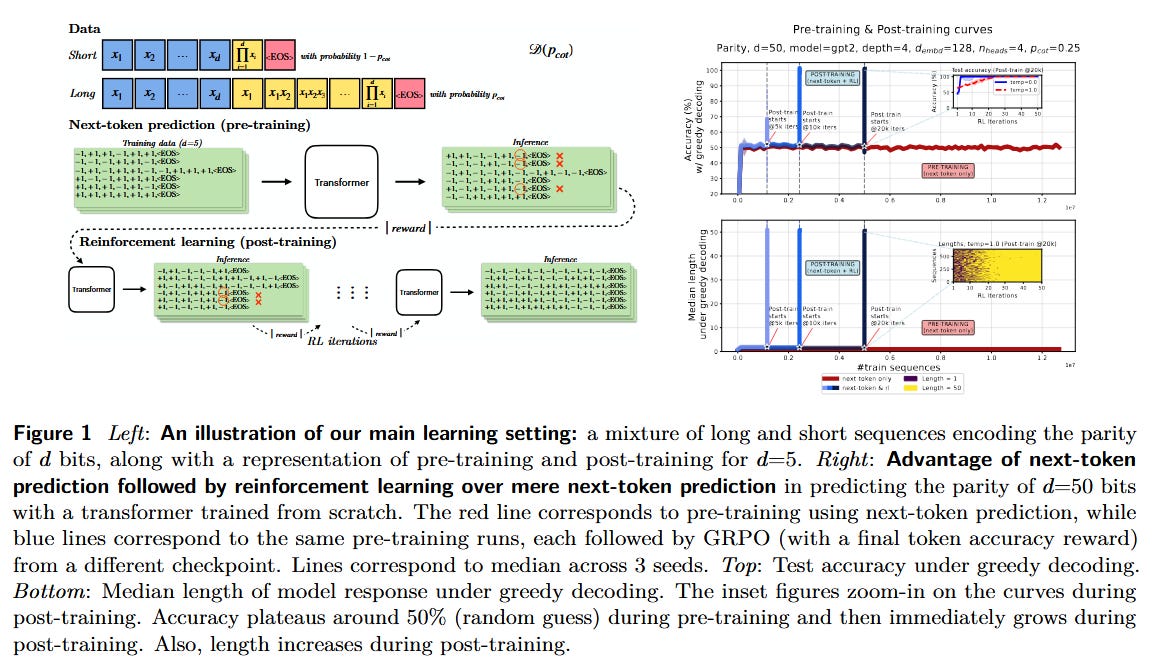
How Reinforcement Learning After Next-Token Prediction Facilitates Learning (Tsilivis et al., 2025) - A deep dive into the mechanics of fine-tuning LLMs with RL on reasoning tasks. Recent breakthroughs in mathematical and logical reasoning by LLMs have relied on a recipe: first pre-train on next-token prediction, then fine-tune with RL (e.g. optimizing a reward for correct answers). This paper asks why the RL stage is so effective. The authors develop a theoretical framework using a toy parity bit task and prove that RL fine-tuning enables generalization that next-token training alone cannot achieve without exponentially more data or compute. The intuition is that an RL objective can leverage longer chain-of-thoughts at test time - effectively letting the model use additional computation (by generating longer explanations/steps) to solve a task. In their setup, the training data is a mixture of short and long reasoning sequences (e.g. mostly short explanations with a few long detailed ones). They show mathematically that an autoregressive model trained only by imitation (next-token) struggles to learn the rare long dependencies. But if you then apply RL that rewards correct final answers, the model learns to use the occasional long chain-of-thought to get those answers right, even when such long examples were sparse in the data. Essentially, RL fine-tuning teaches the model when to deploy a long reasoning chain. The authors prove, in a simplified linear model, that as long as a non-negligible fraction of long trajectories exist, this two-stage training efficiently learns the underlying task, whereas next-token learning would need an impractical amount of long examples. They confirm these phenomena on real LLMs (LLaMA models) on math reasoning benchmarks: models with an RL second stage solve problems with far greater depth than those without. This work provides a theoretical backbone for why techniques like Reinforcement Learning from Human Feedback (RLHF) dramatically improve reasoning: the RL step is not just fine-tuning - it’s fundamentally expanding the model’s ability to utilize longer, more strategic reasoning that was latent after pre-training.
StreamingVLM: Real-Time Vision-Language Understanding for Endless Videos (paper/code)

StreamingVLM: Real-Time Understanding for Infinite Video Streams (Xu et al., 2025) - An architecture to turn video+language models into live video interpreters. As AI moves into assisting with eg. wearable cameras or robot perception, a challenge emerges: processing an unending video stream without infinite memory or latency. Traditional vision-language models struggle with long videos because either you use full attention (quadratic cost - impossible beyond a few minutes), or a sliding window (which can break temporal coherence or incur redundant computations). StreamingVLM introduces a unified framework that aligns how the model is trained with how it will inference on streaming data. The model is trained via supervised fine-tuning on short overlapping video chunks, but with a twist: at inference it maintains a compact memory of past context by reusing certain states rather than naively recomputing or forgetting. Specifically, it keeps a fixed-size key-value cache composed of three parts: (a) “attention sinks” - a set of latent states that aggregate long-term info, (b) a short window of recent visual frames (so it always looks at the latest few moments in full detail), and (c) a longer window of recent text (so it remembers the dialogue or instructions). By resetting context smartly and carrying over only distilled state, the model’s computation stays bounded even as the video stream goes on indefinitely. The authors create a new benchmark with 2-hour continuous videos requiring second-by-second captioning/alignment. StreamingVLM achieves real-time performance (8 frames/sec on one GPU) while maintaining coherent understanding across the entire 2+ hour video. It beats a strong baseline (GPT-4O mini) in head-to-head comparisons 66% of the time. Impressively, the streaming training strategy also made the model better at general video QA - it boosted performance on standard long-video QA benchmarks by 4-6 points without any direct fine-tune on those tasks. This work paves the way for LLM-powered assistants that can watch and narrate live video nonstop, by combining sliding windows with learned memory in a principled, efficient manner.
Better Together: Unpaired Multimodal Data Boosts Unimodal Models (paper/code)
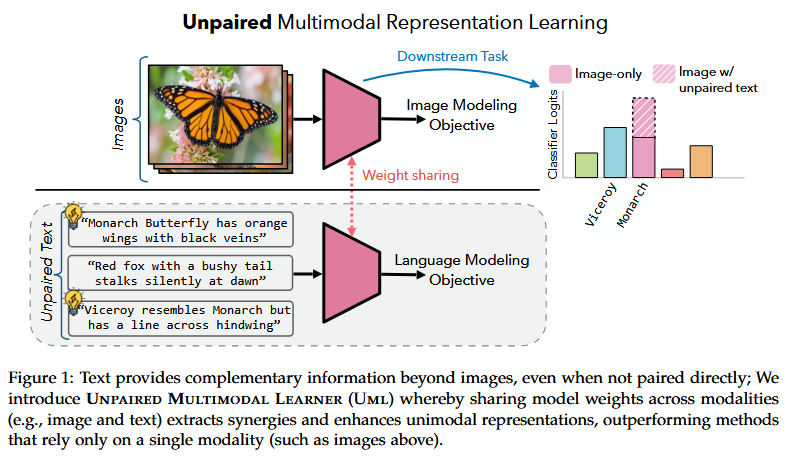
Better Together: Leveraging Unpaired Multimodal Data for Stronger Unimodal Models (Gupta et al., 2025) - Can a vision model get better by training alongside text, even if no image is directly paired with any text? This paper answers yes, introducing UML (Unpaired Multimodal Learner), a training paradigm where a single model processes different modalities in turn without one-to-one alignment. The premise is that different data modalities (images, text, audio) are all projections of the same underlying reality - so even if you don’t have matched pairs, a model sharing parameters across modalities can learn general features that help each other. In UML, an iteration might feed an image through the network, then on the next batch feed text through the same network (with modality-specific input encoders), and so on, updating shared weights throughout. The authors prove under a linear Gaussian model that using an auxiliary modality will strictly increase the Fisher information about the target task, effectively reducing variance of the learned representation. In intuitive terms, even unpaired data from a second modality provides “another view” of the world that can sharpen the model’s understanding of the primary modality. One striking theoretical result: in some cases a single sample from an auxiliary modality can contribute as much as an entire additional sample of the primary modality in terms of information gain. Empirically, UML is validated on a wide range of benchmarks. For example, training an image classifier jointly with unpaired text data yields higher accuracy than training on images alone - especially on fine-grained or few-shot tests. Models trained with UML also prove more robust to distribution shifts (e.g. an ImageNet model is sturdier against ImageNet-Sketch or -A variants if it was also trained with text). The benefits extend to three modalities: adding both text and audio to an image model yielded monotonic improvements. Notably, the researchers quantified a “exchange rate” between modalities: with certain pretrained encoders, they found 1 image ≈ 228 words in terms of contribution to accuracy, highlighting how aligned representations make modalities highly complementary. Overall, UML demonstrates a simple but powerful idea: you don’t need perfectly synced multimodal pairs to get multimodal benefits - just throw all the data into one model with a shared representation, and each modality will make the others stronger.
Base vs. Thinking LLMs: Unlocking Latent Reasoning (paper)
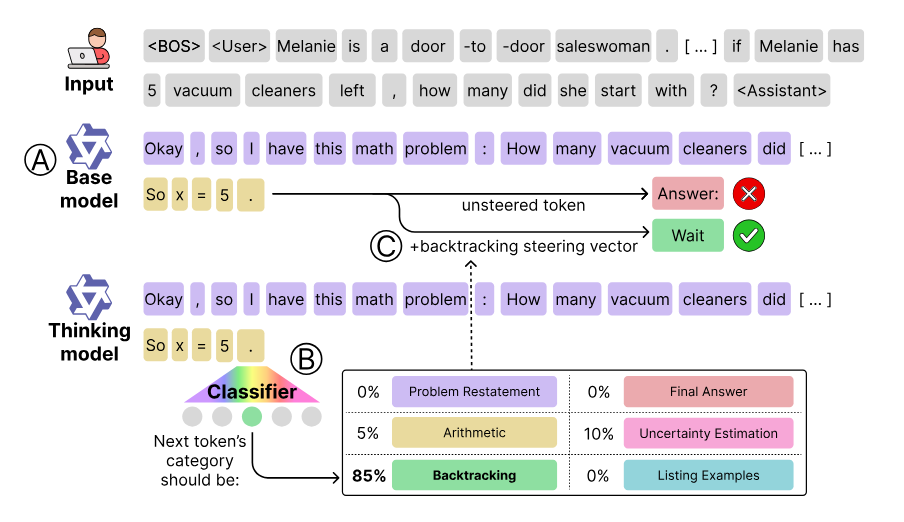
Base Models Know How to Reason, Thinking Models Learn When (Venhoff et al., 2025) - Do larger “thinking” models actually acquire new reasoning skills, or just learn to use skills their base model already had? This provocative work finds evidence for the latter. So-called “thinking models” (like those fine-tuned with chain-of-thought or other reasoning prompts) consistently outperform their base LLMs on tasks like math word problems. But the authors show you can close **≈91% of that gap ** by non-training means: they create a hybrid setup that takes a base model and “steers” its hidden activations on-the-fly using cues from a thinking model. Specifically, they identified certain internal neurons or directions associated with reasoning steps (via an unsupervised method to find interpretable reasoning behaviors). At inference time, nudging the base model along those directions for only ~12% of the tokens is enough to make it solve problems almost as well as the fully fine-tuned model - all without updating any weights. This strongly suggests the base pre-trained model already contained the requisite reasoning capability; what the thinking-model fine-tuning did was mainly teach the model when to deploy those capabilities. In other words, during pre-training the model learned “how to reason” in principle, and during specialized fine-tuning it learned “when to switch into reasoning mode”. This reframes our understanding of chain-of-thought finetuning: it may not be adding new reasoning circuits so much as scheduling the existing ones. The paper’s results also introduce a practical method: by activating latent reasoning at the right times, a base GPT-style model can get close to advanced performance with far less cost. It’s an exciting validation that even very large LLMs still have untapped reasoning potential that can be elicited by careful prodding, rather than always needing scale or heavy training.
The Markovian Thinker: Efficient Long Chains of Thought via RL (paper/code)
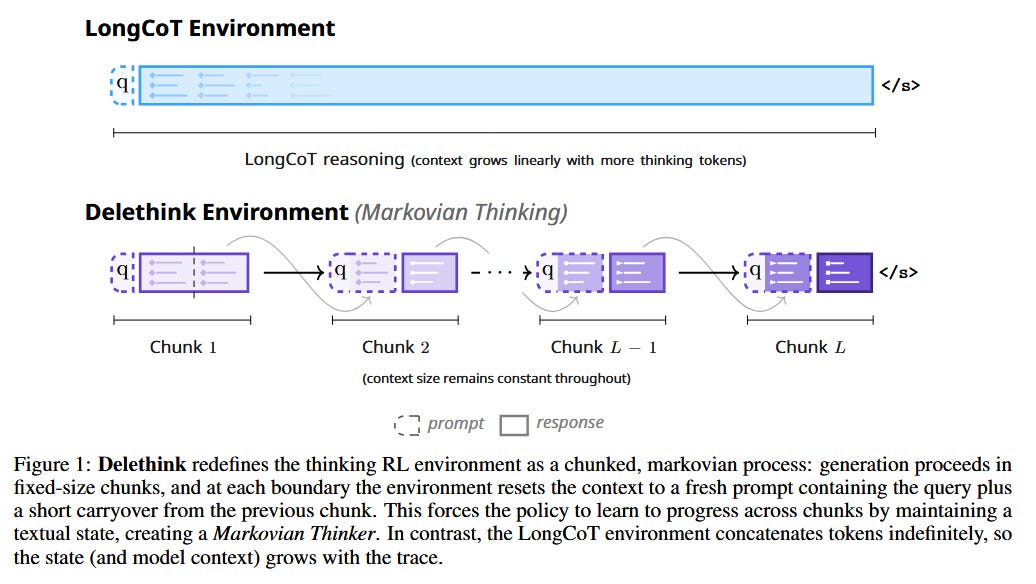
The Markovian Thinker (Aghajohari et al., 2025) - A new paradigm to train LLMs for really long reasoning without blowing up compute. When we use reinforcement learning to teach an LLM to do multi-step reasoning (e.g. solve a lengthy math proof with a series of steps), the naive approach treats the entire prompt plus all generated tokens as the state for the next token decision. This “LongCoT” setup means the state length keeps growing, leading to quadratic time/cost as the chain-of-thought grows. This paper proposes Markovian Thinking, which redefines the environment so that the model only ever conditions on a fixed-length context, regardless of how long the overall solution is. The trick is to chunk the reasoning process into segments. After a segment (say 256 tokens) is generated, the environment “resets” - it provides the model a brief summary of what’s been done (a short carryover state) and then the model continues the reasoning in a fresh context window. Essentially, the model learns to write a concise state representation at the end of each chunk that will allow it to seamlessly pick up after the reset. They implement this in an RL environment called Delethink (think “delete the context, keep the essential”) with 8K-token chunks. A 1.5B model trained in this setup was able to generate coherent reasoning traces up to 24K tokens long in 8K contexts, matching or slightly surpassing the performance of a baseline that was trained with the full 24K context window. Because of the fixed state, the compute cost grows linearly with the reasoning length instead of quadratically. The authors extrapolate that extending reasoning to 96K tokens would take ~4× less GPU time with Markovian (7 H100-months) compared to standard LongCoT RL (27 H100-months). They also found that many existing LLMs (from 1.5B to 120B) already sometimes output “Markovian” chain-of-thoughts (i.e., they naturally segment their reasoning) without any fine-tuning. This means the model can be seeded with zero-shot examples of the desired behavior, making RL training stable. Bottom line: by changing the rules of the game (the MDP for reasoning), we can train LLMs to solve very long-horizon tasks with constant memory and manageable computation - a promising step toward scalable “System 2” reasoning in AI.

Couldn't agree more. That RL scaling insight is massive. Knowing about the S-curve makes capacity planning so much less of a headach, big thanks for distilling this, Watcher.