
o4-mini, Gemini 2.5 and R1 Just Teamed Up
Stay ahead of the curve with LLM Watch
Welcome, Watcher! This week I’ll try out a new format. As compensation you will get not three, not four, not five - but nine! - paper highlights. So let’s get started!
When models learn to think by playing games
(paper/code) The conventional wisdom in AI has been straightforward: train on more data, get better results. But researchers at various institutions are discovering that how models learn matters as much as what they learn. The SPIRAL framework demonstrates this beautifully by having language models play zero-sum games against themselves.
Rather than relying on expensive human-curated datasets, SPIRAL creates an infinite curriculum where models continuously face stronger opponents. The results are striking: a Qwen3-4B model trained through self-play shows 8.6% improvement on mathematical tasks and 8.4% on general reasoning, outperforming traditional supervised fine-tuning on 25,000 expert examples. The secret? Three cognitive patterns emerge naturally from competitive play: systematic decomposition, expected value calculation, and case-by-case analysis.
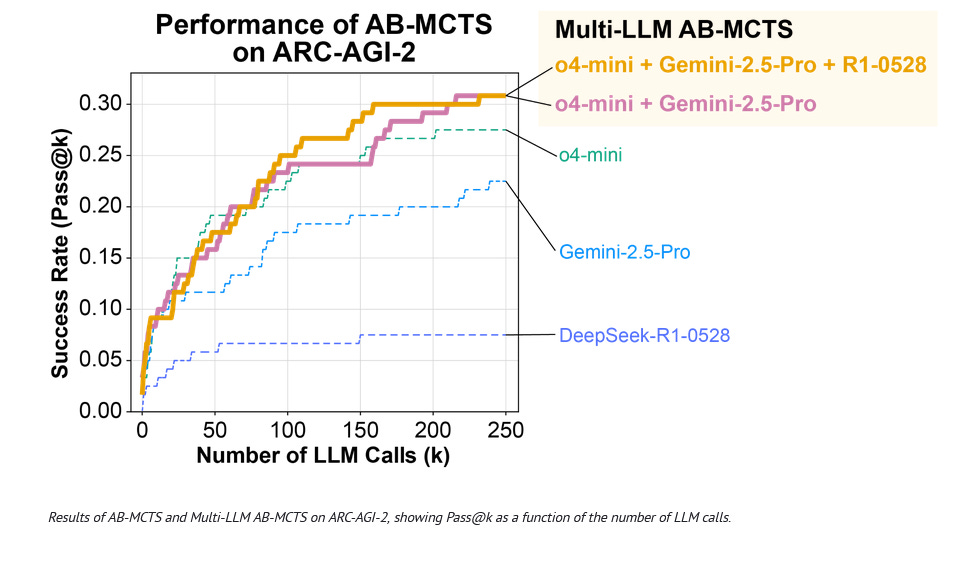
(paper/code) This finding connects directly to Sakana AI's AB-MCTS (Adaptive Branching Monte Carlo Tree Search), which takes a different but complementary approach. Instead of training through games, AB-MCTS enables multiple AI models to collaborate at inference time through intelligent trial-and-error. The system dynamically decides whether to explore new solution paths or refine existing ones, achieving 30% success rate on ARC-AGI-2 tasks - a significant improvement over any single model's 23% baseline.
What makes AB-MCTS particularly intriguing is its demonstration that different AI models can solve problems together that none could solve alone. When ChatGPT, Gemini, and DeepSeek work in concert through the AB-MCTS framework, incorrect solutions from one model become valuable hints for others. It's collective intelligence in action, released as open-source TreeQuest for the community to build upon.

Join me at the Imperial Palace this September!
If you don’t know what TEDAI is, it’s an exclusive invite-only TED conference dedicated to Artificial Intelligence – with Vienna being one of the few select locations, and the only one in Europe.
Last year’s TEDAI Vienna 2024 has been the first of its kind and can be considered a huge success. Some of the most important decision makers from all over the world came together with leading AI experts for 3 days, including dinners, talks, workshops, and much more.
The math trap: When specialization backfires
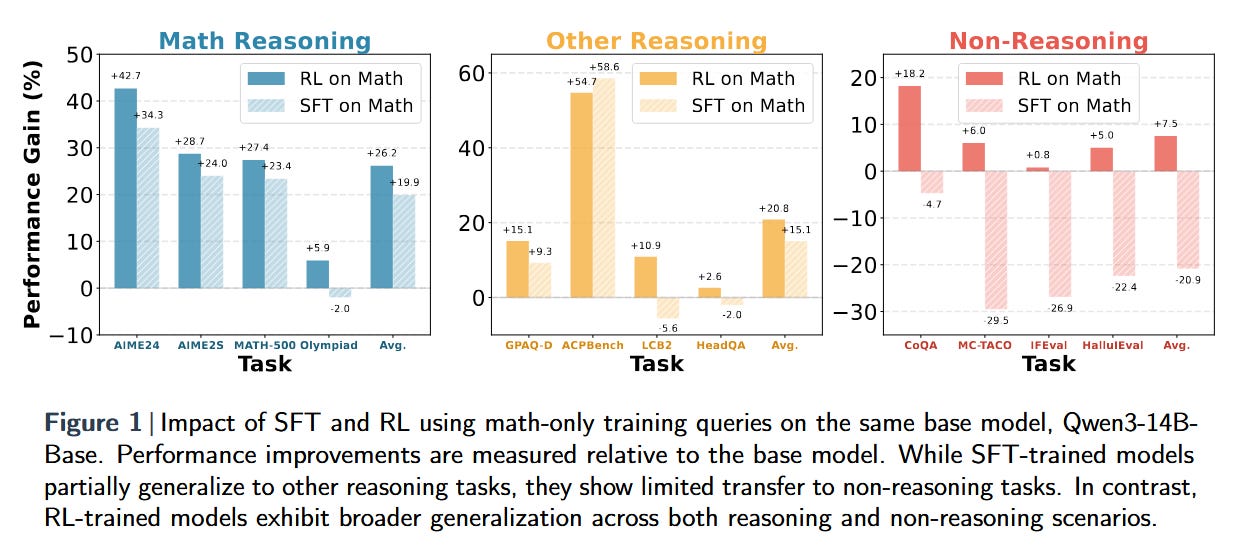
(paper/code) Perhaps the most surprising finding this week comes from Maggie Huan and colleagues, who ask a question the field has been avoiding: Does improving math reasoning actually make models smarter overall? Their comprehensive evaluation of over 20 reasoning-tuned models reveals an uncomfortable truth: most models that excel at mathematics fail to transfer these gains to other domains.
The culprit? Training methodology. Models fine-tuned with supervised learning often experience "catastrophic forgetting" of general capabilities, while those trained with reinforcement learning maintain broader competence. This discovery has immediate implications for how we develop AI systems - the current race to top math leaderboards might be leading us astray (paper/code).
(paper/code) This concern is elegantly addressed with OctoThinker, which investigates what makes a base model suitable for reinforcement learning. Their key innovation is a "stable-then-decay" training strategy: first training on 200 billion tokens with constant learning rate, then continuing on 20 billion tokens with decay. The result? 10-20% improvement across mathematical benchmarks while maintaining general capabilities.
The Meta research team's investigation into bridging offline and online reinforcement learning provides additional nuance. Their surprising finding: semi-online training nearly matches fully online performance while offering significant efficiency benefits. This suggests we might not need the most computationally expensive training approaches to achieve strong results.
Understanding the black box: Which thoughts matter?
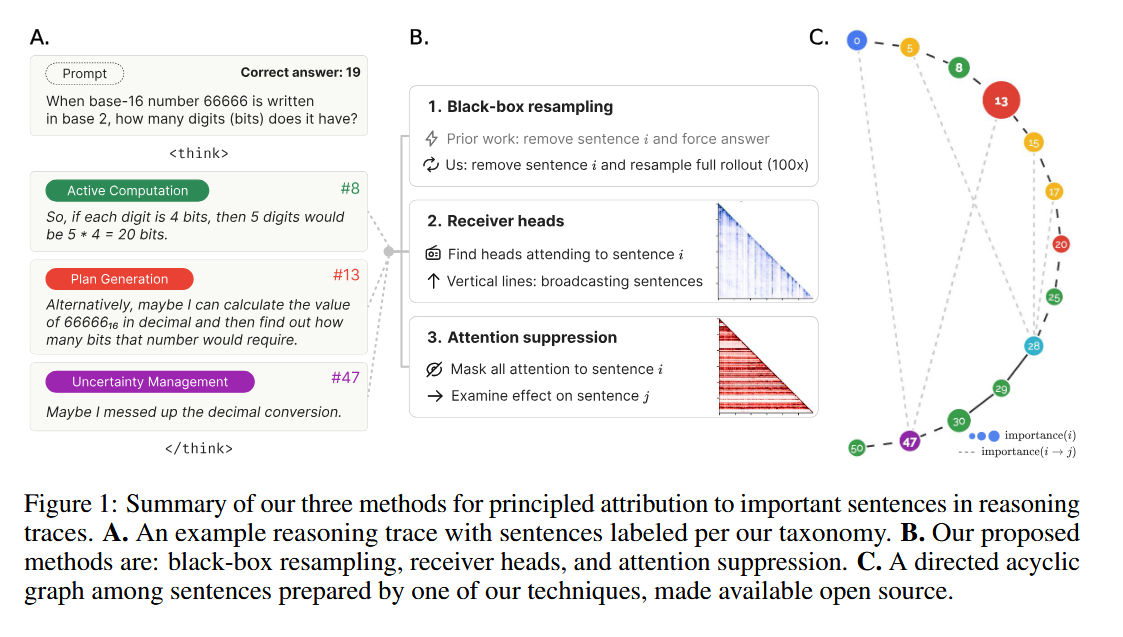
(paper/code) As models become more capable, understanding their reasoning becomes critical. "Thought Anchors” tackle this by identifying which reasoning steps have outsized importance in chain-of-thought reasoning.
Their analysis of DeepSeek and Llama models reveals that planning and uncertainty management sentences consistently emerge as critical decision points. Using innovative attribution methods - counterfactual resampling, attention pattern analysis, and causal attribution - they've created an interactive visualization tool that displays reasoning chains as directed graphs, with thought anchors as prominent nodes.
(paper) This interpretability work complements a theoretical breakthrough from Nanjing University's LAMDA Group. Their research on "Generalist Reward Models" proves that any LLM trained via standard next-token prediction already contains a latent, powerful reward model. This "endogenous reward" is mathematically equivalent to rewards learned through offline inverse reinforcement learning - a discovery that could eliminate the need for expensive human preference data in model alignment.
The unified intelligence frontier
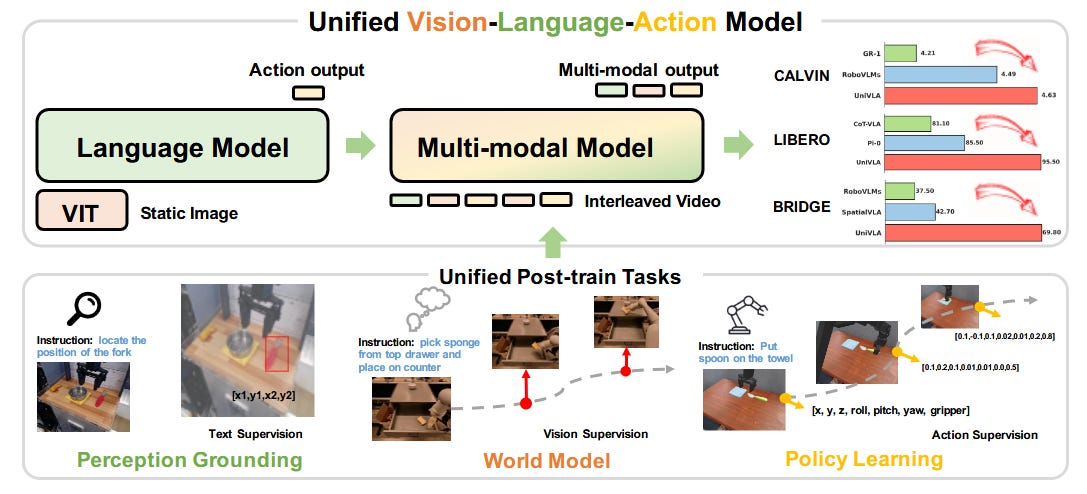
(paper/code) While reasoning improvements capture headlines, equally important advances are happening in multimodal AI. Alibaba's WorldVLA and UniVLA from multiple institutions represent complementary approaches to unified vision-language-action models.
UniVLA's breakthrough is its autoregressive tokenization of vision, language, and action as discrete sequences, achieving 95.5% success rate on LIBERO robotic manipulation tasks - significantly outperforming previous approaches while using less than 1/20 of the pre-training compute. The key insight: incorporating world modeling during post-training to capture causal dynamics from videos.
(paper/code) WorldVLA takes this further by proposing that action models and world models shouldn't operate in isolation. Their unified framework shows 4% improvement in grasping success and 10% reduction in video prediction error. The mutual enhancement principle - where action understanding aids visual generation and vice versa - points toward more integrated AI systems.
Evaluating the evaluators
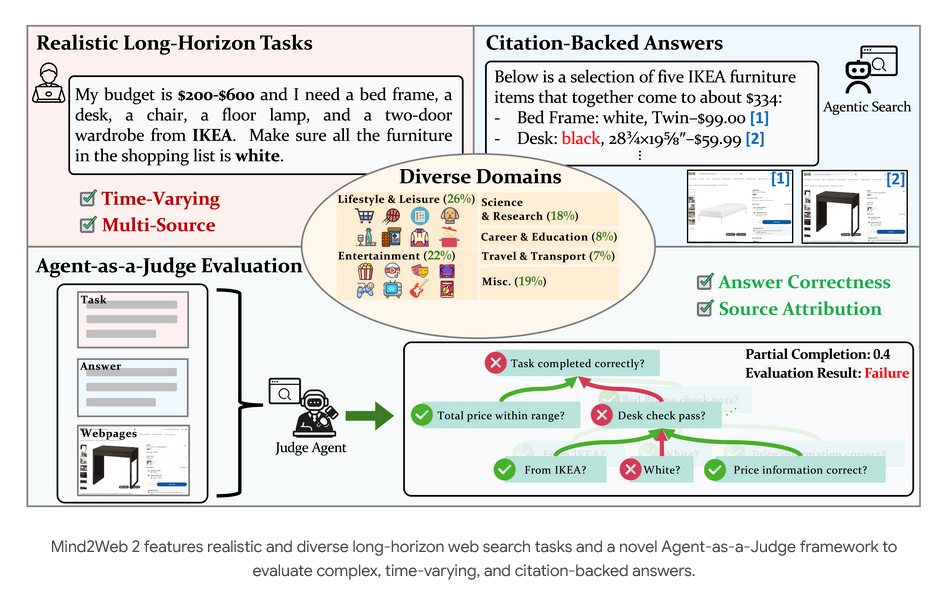
(paper/code) As AI agents become more autonomous, evaluating them becomes increasingly complex. Ohio State's Mind2Web 2 benchmark addresses this with 130 realistic, long-horizon tasks requiring real-time web browsing and information synthesis. Their new "Agent-as-a-Judge" framework uses task-specific judge agents with tree-structured rubrics, showing that OpenAI's Deep Research reaches 50-70% of human performance while working twice as fast.
What this means for AI's future
The era of simply scaling up models and training data is giving way to more sophisticated approaches that emphasize:
Smarter training strategies that preserve general capabilities while improving specific skills. The success of reinforcement learning over supervised fine-tuning, the promise of self-play, and the efficiency of semi-online training all point toward more nuanced training methodologies.
Inference-time intelligence through techniques like AB-MCTS that enable models to “think” harder about difficult problems and collaborate effectively. The ability to achieve better results without additional training opens new possibilities for deploying AI systems.
Unified architectures that break down barriers between modalities and capabilities. The convergence of vision, language, and action in single models, along with the theoretical understanding that different neural network paradigms are fundamentally related, suggests we're moving toward more general AI systems.
Better evaluation and interpretability that goes beyond simple benchmarks to understand how models reason and which reasoning steps matter most. This deeper understanding is crucial for building AI systems we can trust in high-stakes applications.
The message is clear: the next breakthrough in AI might not come from building bigger models, but from teaching our current models to reason better, work together more effectively, and maintain their general capabilities while developing specialized skills.
Hello and welcome to my talk where we talk about artificial systems intelligence with MOE and rag memory with a twist on vector database. Closer and closer to your goal are you not?