
NVIDIA's LLamaTron Moment
Learn about Llama-Nemotron, Absolute Zero and how to rethink memory in AI
Welcome, Watcher! This week, we're exploring three recent AI developments that are transforming how models reason, learn independently, and remember information.
First, Llama-Nemotron tackles the challenge of making high-quality reasoning accessible and efficient. By combining neural architecture search, knowledge distillation, and curriculum-driven reinforcement learning, this open-source family of models delivers state-of-the-art reasoning performance with dramatically improved inference speed. Their "detailed thinking on/off" toggle lets users dynamically allocate compute resources only when deep reasoning is needed, making advanced AI reasoning viable for real-world, cost-sensitive deployments.
Next, Absolute Zero redefines how AI learns to think by completely eliminating the need for human-curated datasets. Through a clever self-play approach, a single model invents its own coding puzzles across three complementary reasoning types, then learns to solve them through trial and error. This zero-data reinforcement learning paradigm matches or exceeds methods trained on thousands of expert-labeled problems, pointing toward a future where AI systems can autonomously improve their reasoning abilities without human supervision.
Finally, Rethinking Memory in AI provides a much-needed comprehensive map of how AI systems store, manage, and utilize information. By classifying memory into three types and six core operations, this work creates a unified framework for understanding everything from parametric memory in model weights to contextual structured and unstructured memory. This taxonomy illuminates emerging research areas like long-term personalized memory and safe forgetting techniques, establishing a clear playbook for building systems that can learn over time and adapt to users.
The connecting threads are clear: making advanced reasoning more accessible and efficient, enabling models to improve themselves without human guidance, and establishing frameworks for how AI systems remember and process information. Together, these advances are building toward more capable, efficient, and adaptable AI systems that can reason deeply while remaining practical for real-world applications.
Don't forget to subscribe to never miss an update again.
Courtesy of NotebookLM
1. Llama-Nemotron: Efficient Reasoning Models
Watching: Llama-Nemotron (paper/dataset/model)
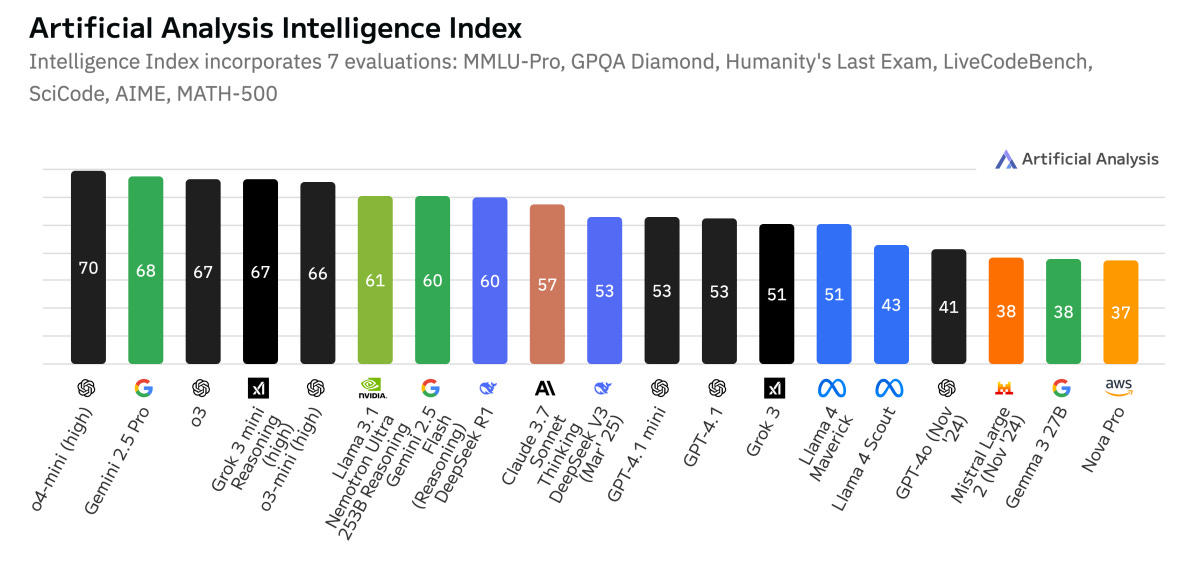
What problem does it solve? Large language models that “think” step by step (chain-of-thought reasoning) have set new benchmarks in math, coding, and scientific Q&A, but they’re massive, slow, and often closed-source. This makes it hard for companies and researchers to deploy them in cost‐sensitive or custom settings, and you can’t easily dial reasoning on or off to save compute on simpler queries. The paper aims to bridge the gap between top-tier reasoning performance and real-world inference efficiency in an open, enterprise-friendly package.
How does it solve the problem? They designed the Llama-Nemotron family in three sizes (8B, 49B, and 253B parameters) using a multi-stage pipeline:
Neural architecture search (NAS) and FFN fusion to build inference-optimized transformer blocks.
Knowledge distillation and continued pretraining from Llama-3 teachers to recover accuracy.
Supervised fine-tuning on high-quality reasoning traces plus a large‐scale, curriculum-driven reinforcement learning stage (GRPO) to push beyond teacher performance.
They also introduced a “detailed thinking on/off” toggle at inference time and open-sourced the models, post-training dataset, and code (NeMo, NeMo-Aligner, Megatron-LM).
What are the key findings? Their flagship LN-Ultra (253B) matches or exceeds DeepSeek-R1 and other state-of-the-art reasoning models on benchmarks like GPQA-Diamond, AIME-24/25, LiveCodeBench, and MATH500, while running 1.7x faster and using less memory on a single 8xH100 node. The mid- and small-sized variants (49B “Super” and 8B “Nano”) also deliver strong multi-step reasoning and instruction-following accuracy at dramatically lower cost. Across all sizes, the dynamic reasoning toggle works reliably to switch between detailed chains of thought and concise chat mode.
Why does it matter? By open-sourcing high-throughput, reasoning-capable models under a permissive NVIDIA license, the work lowers the barrier for enterprises and academics to build and deploy custom intelligent agents. Efficient inference design means deep thinking no longer requires massive GPU farms, and the user-controlled reasoning switch lets you allocate compute only when needed. Finally, releasing the full training dataset and code fosters reproducibility and accelerates future advances in LLM research.
2. Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Watching: Absolute Zero (paper)

What problem does it solve? Modern methods for sharpening a language model’s “thinking” (reasoning) skills lean heavily on large, hand‐made sets of example questions, answers and reasoning steps. Curating tens of thousands of these by hand is slow, costly and won’t scale - especially if future AIs become smarter than us. Even “zero‐shot” reinforcement approaches still need human-written question–answer pairs. This paper asks: can we train a model to get better at reasoning without any external human data at all?
How does it solve the problem? They propose a new paradigm called Absolute Zero: a single model alternately invents its own coding puzzles and then solves them, all in a Python environment that can automatically verify answers. By framing three complementary puzzle types - deduction (predict the output), abduction (infer the input), and induction (synthesize a program from examples) - the model learns via reinforcement learning from simple, outcome‐based rewards. Their Absolute Zero Reasoner (AZR) is one unified LLM serving as both “teacher” (task proposer) and “student” (solver), updated end-to-end with a tailored RL algorithm.
What are the key findings? Remarkably, AZR - trained with zero human-curated examples - matches or beats state-of-the-art “zero” models that used tens of thousands of expert-labeled problems. On coding benchmarks like HumanEval+ and MBPP+ and on math tests (AIME, AMC, OlympiadBench), AZR sets new records. It generalizes better across domains (code→math), scales its gains from 3B to 14B parameters, and even shows emergent behaviors like interleaved planning (“comments as scratch-pads”).
Why does it matter? By eliminating the need for any external dataset, this work removes a major bottleneck in reasoning‐focused fine-tuning. It points to a future where AI agents can autonomously invent challenges, learn from them, and continually improve - potentially attaining superhuman reasoning - without costly human supervision. This self-play-driven approach could redefine how we build scalable, adaptive, and ever-smarter AI, though it also highlights the need for careful safety oversight as models learn on their own.
3. Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directions
Watching: AI Memory (paper/code)
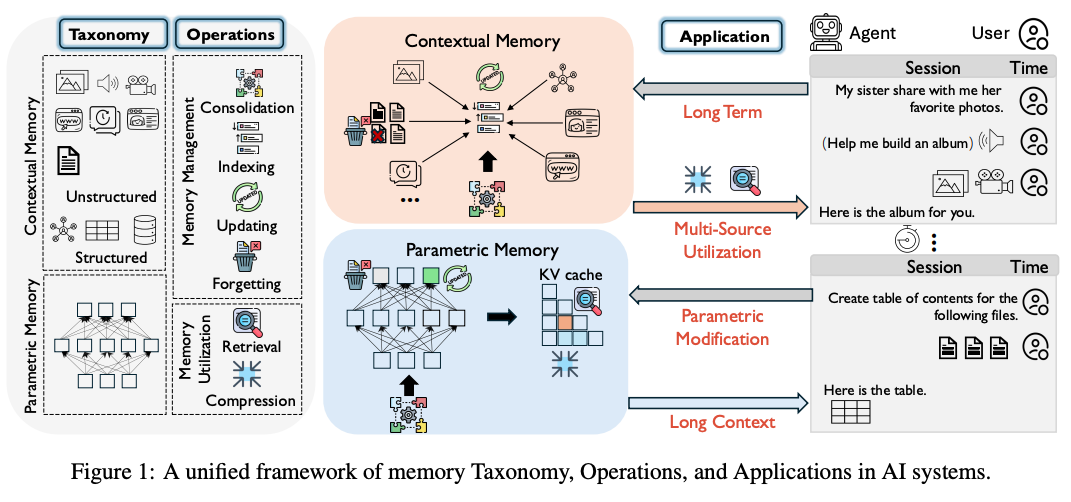
What problem does it solve? AI systems - especially those built on big language models - rely on different kinds of “memory” (like facts baked into their weights or chunks of past text), but researchers lack a clear, unified map of how that memory is stored, managed, and used. Existing surveys often look at only one piece (say, long-context prompts or personalization) and miss the basic “atomic” operations - writing new facts, indexing them, updating or erasing old ones, pulling them back out, or squashing information to fit a limited space.
How does it solve the problem? They drew up a simple but comprehensive blueprint: split AI memory into three types - parametric (inside the model’s weights), contextual structured (things like tables and graphs), and contextual unstructured (raw text or embeddings) - and define six core operations (consolidation, indexing, updating, forgetting, retrieval, compression). Then they scanned over 30,000 top-conference papers, used a time-adjusted citation score to pick the most influential work, and systematically mapped methods, datasets, and tools onto this taxonomy.
What are the key findings? Four major research themes emerge: (1) long-term memory for bots that can remember you across many chats, (2) long-context memory to handle really big chunks of text without dropping bits in the middle, (3) parametric memory editing and unlearning to tweak or erase facts inside a model’s “brain,” and (4) multi-source memory that merges text, tables, images, and more. The survey also inventories popular benchmarks (e.g., LongBench, LoCoMo), frameworks (LangChain, LlamaIndex), and memory-as-a-service tools (Mem0, Zep), while highlighting gaps like time-aware (“spatio-temporal”) memory and safe forgetting.
Why does it matter? Their work provides a clear, operation-by-operation playbook for anyone building or studying AI memory systems - helping developers pick the right tools, guiding researchers to open challenges, and ultimately enabling service-bots and agents that learn over time, adapt to you, and remove outdated or harmful information safely.

Papers of the Week:
DeepSeek-Prover-V2-671B, a Lean 4 LLM for formal theorem proving, integrates formal/informal reasoning using DeepSeek-V3 and reinforcement learning. It achieves 88.9% on MiniF2F-test, solves 49 PutnamBench problems, and is evaluated on ProverBench, including AIME competitions. The gap between formal and informal mathematical reasoning is narrowing.
Qwen2.5-72B-Instruct powers a two-stage framework enhancing LLM critics for math using seed data of step-wise critiques. Reinforcement learning, with PRM800K or Monte Carlo sampling, boosts critique ability. The resulting model outperforms existing LLM critics, including DeepSeek-R1-distill, on error identification benchmarks.
RAG-MCP enhances LLM tool selection accuracy, overcoming prompt bloat and selection complexity when using external Model Context Protocol (MCP) tools. It improves scalable tool integration via Retrieval-Augmented Generation by offloading tool discovery using semantic retrieval from an external index. Experiments, including an MCP stress test, show >50% token reduction.
Large language models (LLMs) struggle with complex planning. HyperTree Planning (HTP) uses hypertree-structured planning outlines for hierarchical divide-and-conquer, managing constraints/sub-tasks via iterative refinement in an autonomous framework. Gemini-1.5-Pro achieves state-of-the-art accuracy on the TravelPlanner benchmark, with a 3.6 times performance improvement using HTP.
Holmes, using LLM summarization for evidence retrieval, assists Large Language Models in multimodal disinformation detection. Achieving 88.3% accuracy on open-source datasets and 90.2% in real-time verification, Holmes boosts fact-checking accuracy and generates justifications, improving societal trust.
LS-Mixture SFT, using long/short Chain-of-Thought (CoT) data (via structure-preserved rewriting) distilled from DeepSeek R1, enables efficient reasoning in non-reasoning models by mitigating 'overthinking' from Supervised Fine-Tuning (SFT). It achieves a 2.3% accuracy improvement and 47.61% response reduction versus standard SFT.
DYSTIL, a novel framework using a strategy-generating LLM, overcomes generalization and sample efficiency issues in reinforcement learning, outperforming behavioral cloning. By dynamically inducing textual strategies from expert demonstrations and advantage estimations, DYSTIL internalizes these strategies via policy optimization, boosting policy generalization. Tested on Minigrid and BabyAI, DYSTIL achieves a 17.75% average success rate improvement, revealing underlying strategies.