
Nine Papers You Should Know About
Digestible insights on the latest AI research

Welcome, Watcher! This week in LLM Watch:
Prompt Engineering is dead, long live Prompt Engineering!
How LLMs can predict multiple tokens at once, accelerating inference 5x
The surprising limits of reinforcement learning for reasoning
Don't forget to subscribe to never miss an update again.
1. A Survey of Context Engineering for Large Language Models: From Prompts to Production Systems
Watching: Context Engineering (paper)

What problem does it solve? The term "prompt engineering" has become so diluted it now means little more than "typing things into a chatbot." As LLMs evolve into complex multi-agent systems integrated with tools, databases, and real-time data streams, we need a new framework to understand how to design, manage, and optimize the complete information payload that drives AI systems. Simple prompts are no longer sufficient when your AI needs to coordinate across multiple data sources, maintain conversation history, and adapt to dynamic contexts.
How does it solve the problem? The researchers adapt the term “Context Engineering” and define it as a formal discipline that encompasses the systematic optimization of all information provided to LLMs at inference time. They analyzed over 1,400 research papers to create a comprehensive taxonomy that decomposes Context Engineering into foundational components (retrieval, generation, processing, management) and sophisticated implementations (RAG systems, memory architectures, tool integration, multi-agent coordination). This framework moves beyond ad-hoc prompt design to establish engineering principles for building production-grade AI systems.
What are the key findings? The survey reveals that successful AI applications require sophisticated orchestration of multiple context streams - from real-time data feeds to persistent memory systems. The researchers identify critical patterns: context retrieval systems that dynamically fetch relevant information, context processing pipelines that filter and prioritize data, and context management frameworks that maintain coherence across extended interactions. Most importantly, they show that the evolution from prompts to context engineering mirrors the maturation of software engineering itself.
Why does it matter? This establishes Context Engineering as one of the core disciplines for enterprise AI deployment. As organizations move from AI demos to production systems, they need principled approaches to manage the complexity of multi-modal, multi-source contexts. The framework provides a roadmap for building AI systems that can handle real-world complexity - from financial analysis requiring multiple data streams to healthcare applications needing patient history and real-time monitoring. For practitioners, this means moving beyond prompt libraries to architecting comprehensive context management systems.
2. QuestA: Expanding Reasoning Capacity in LLMs via Question Augmentation
Watching: QuestA (paper)
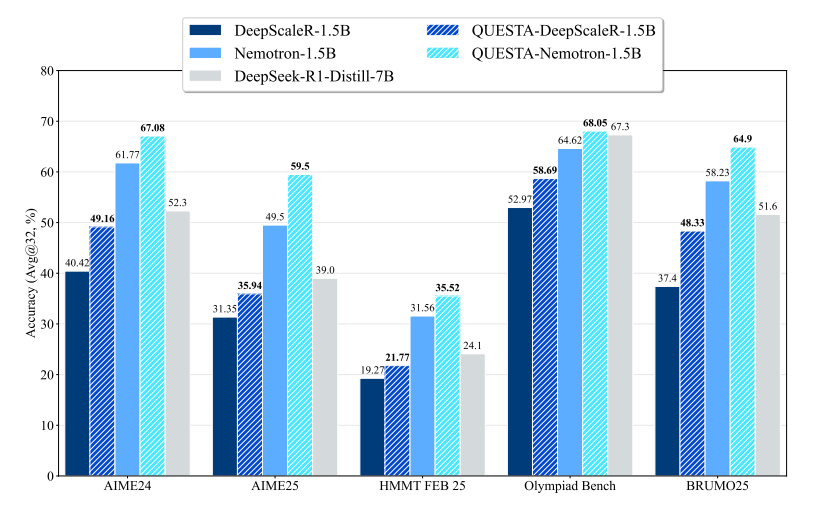
What problem does it solve? Reinforcement learning has become essential for training reasoning models, but it faces a fundamental limitation: on hard problems where models rarely generate correct solutions, standard RL provides weak learning signals. When a model consistently fails at complex mathematical problems, it receives mostly zero rewards, leading to poor gradient updates and minimal improvement. This creates a chicken-and-egg problem - models need to solve problems to learn, but they can't solve problems without learning.
How does it solve the problem? QuestA introduces partial solutions during training to reduce problem difficulty and provide more informative learning signals. Instead of expecting models to solve "prove that for all prime p > 3, p² ≡ 1 (mod 24)" from scratch, QuestA might provide the hint "first show p ≡ ±1 (mod 24)." This transforms an all-or-nothing reward landscape into a graduated learning environment where models can make incremental progress. The approach dynamically adjusts question difficulty based on model capability, creating a curriculum that maintains optimal challenge levels.
What are the key findings? QuestA achieves new state-of-the-art performance on mathematical benchmarks using only 1.5B parameter models: 67.1% on AIME24 (+5.3%), 59.5% on AIME25 (+10.0%), and 35.5% on HMMT25 (+4.0%). More importantly, QuestA improves both pass@1 (best single attempt) and pass@k (best of k attempts), particularly on problems where standard RL makes no progress. The method enables continual improvement over strong baselines like DeepSeek-R1 and OpenMath Nemotron by ensuring models always have learnable trajectories.
Why does it matter? QuestA demonstrates that the path to stronger reasoning models isn't just larger scale or more compute, but smarter training strategies. By solving the sparse reward problem that has plagued RL for reasoning, it opens the door to training models on progressively harder problems without hitting learning plateaus. For the broader AI community, this suggests that curriculum design and adaptive difficulty adjustment may be as important as architectural innovations for achieving human-level reasoning.
3. Your LLM Knows the Future: Uncovering Its Multi-Token Prediction Potential
Watching: Multi-Token Prediction (paper)
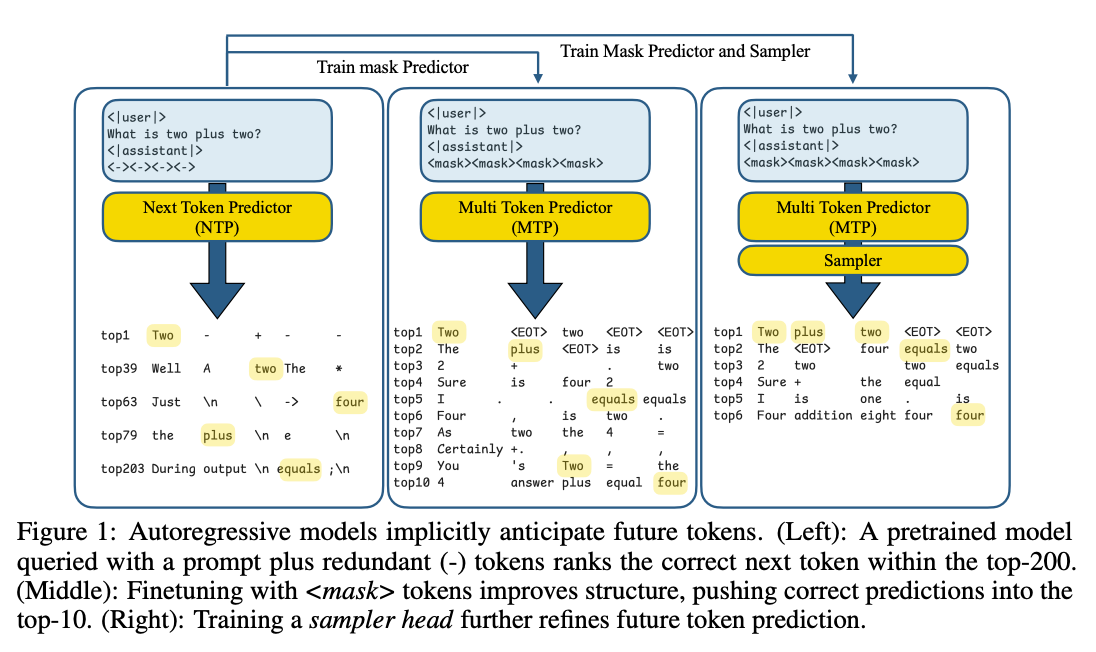
What problem does it solve? Autoregressive language models are fundamentally constrained by their token-by-token generation process. This sequential bottleneck limits inference speed and prevents parallelism, especially frustrating when the model has high confidence about upcoming tokens. Consider generating "The capital of France is Paris" - the model must laboriously produce each token despite knowing with near-certainty what comes next. This inefficiency becomes critical as models scale and deployment costs mount.
How does it solve the problem? The researchers discovered that standard autoregressive models already encode information about future tokens in their hidden states - they just can't express it. Their framework appends special mask tokens to prompts (like "what is two plus two? [MASK] [MASK] [MASK]") and trains the model to fill multiple positions simultaneously. They use gated LoRA adaptation to preserve the original model's capabilities while adding multi-token prediction, plus a learnable sampler module that ensures coherent sequences. The system includes consistency losses to align multi-token and single-token predictions.
What are the key findings? When prompted with "what is two plus two?" followed by placeholder tokens, the correct sequence "equals four" appears in the top 200 logits of a standard pretrained model - revealing latent knowledge of future tokens. After training, the system achieves 1.5-5.2x speedup across different domains, with coding and math showing the highest acceleration due to their predictable structure. The method generates up to 9 tokens per inference step while maintaining quality. Remarkably, this is achieved through lightweight fine-tuning that adds minimal parameters to existing models.
Why does it matter? This reveals that the inefficiency of autoregressive generation isn't fundamental but rather a limitation of how we've trained models to express their knowledge. For deployment at scale, multi-token prediction could dramatically reduce serving costs and latency. The discovery that models already "know" future tokens also has theoretical implications - it suggests that autoregressive pretraining creates richer internal representations than previously understood. As inference costs increasingly dominate AI deployment, such efficiency improvements become economically crucial.

4. MindJourney: Test-Time Scaling with World Models for Spatial Reasoning
Watching: MindJourney (paper)
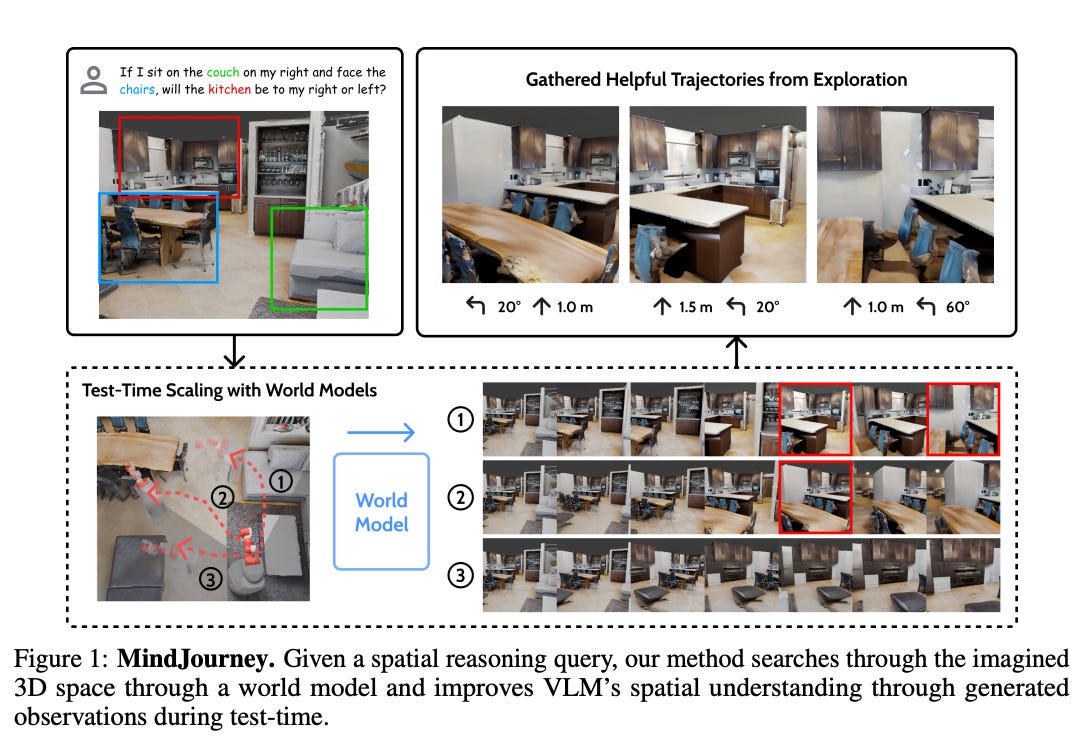
What problem does it solve? Vision-language models excel at describing what they see but fail catastrophically at spatial reasoning. Ask a VLM to predict how a scene will look after moving forward or turning left, and it struggles - these models perceive 2D images but lack an internal model of 3D dynamics. This limitation is critical for embodied AI applications like robotics and navigation, where understanding spatial relationships and predicting visual changes from movement is essential. Current VLMs are like having perfect vision but no spatial memory or imagination.
How does it solve the problem? MindJourney couples VLMs with controllable world models based on video diffusion to grant them 3D reasoning capabilities. The framework works through iterative exploration: the VLM sketches a camera trajectory (e.g., "move forward 2 meters, turn left 30 degrees"), the world model synthesizes the corresponding views, and the VLM reasons over this multi-view evidence. This creates a feedback loop where the VLM can test spatial hypotheses by "imagining" different viewpoints, similar to how humans mentally rotate objects or navigate spaces.
What are the key findings? Without any fine-tuning, MindJourney achieves over 8% performance boost on the spatial reasoning benchmark SAT, with peak improvements reaching 15% on complex multi-step reasoning tasks. The approach works across different VLM architectures and even enhances models already trained with reinforcement learning. Analysis reveals that the world model doesn't just provide additional views - it helps VLMs build coherent 3D representations by enforcing physical consistency across generated perspectives. The iterative exploration process converges to better solutions than single-shot reasoning.
Why does it matter? This demonstrates that complex capabilities like spatial reasoning don't require retraining foundation models - they can emerge from clever orchestration of specialized components. For robotics and embodied AI, MindJourney offers a practical path to spatial intelligence without the massive data requirements of end-to-end training. More broadly, it exemplifies test-time scaling: improving model performance not through larger training runs but through increased computation during inference, guided by world models that encode physical priors.
5. Scaling Up RL: Unlocking Diverse Reasoning in LLMs via Prolonged Training
Watching: Prolonged Training (paper)
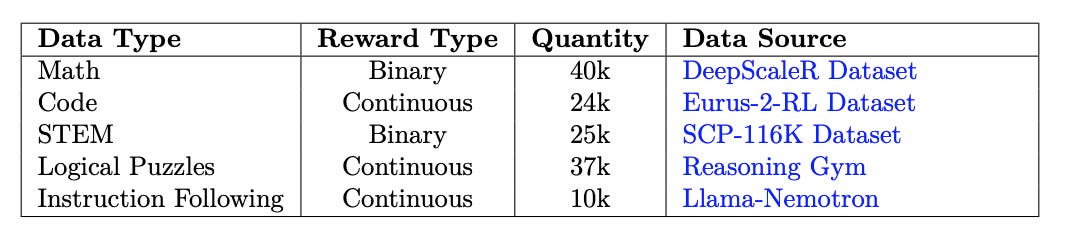
What problem does it solve? Recent reasoning models like OpenAI's o1 and DeepSeek-R1 have shown impressive gains through reinforcement learning, but a critical question remains: Does RL truly expand reasoning capabilities, or does it merely amplify patterns already present in base models? Most RL training runs are relatively short, potentially leaving significant untapped potential. If RL only redistributes probability mass rather than discovering new reasoning strategies, then we're fundamentally limited by pretraining data rather than training methodology.
How does it solve the problem? The researchers conducted extensive experiments with prolonged RL training - running for significantly more steps than typical approaches. They introduced ProRL (Prolonged Reinforcement Learning), which includes KL divergence control to prevent mode collapse, reference policy resetting to maintain exploration, and training across diverse task suites to encourage generalization. By training small models (1-3B parameters) for extended periods with careful hyperparameter tuning, they could isolate the effects of RL duration from model scale.
What are the key findings? The results fundamentally challenge the "RL as redistribution" hypothesis. With prolonged training, RL models discover reasoning strategies completely absent from base models, even under extensive sampling (k=1000+). Performance improvements strongly correlate with both task competence and training duration, suggesting RL genuinely explores new solution spaces over time. On problems where base models achieve 0% success regardless of sampling budget, ProRL models reach 40-60% accuracy. The diversity of reasoning approaches actually increases with longer training, contradicting the narrow exploitation hypothesis.
Why does it matter? This suggests we've been dramatically underestimating RL's potential for improving reasoning. While the race for larger models continues, these findings indicate that patient, prolonged training might unlock capabilities we assumed required scale. For practitioners, it means that investing in longer RL runs could yield better returns than simply scaling model size. The discovery that RL can find genuinely novel reasoning strategies also has implications for AI safety - these models might develop unexpected problem-solving approaches not present in their training data.
6. MCPEval: Automatic MCP-based Deep Evaluation for AI Agent Models
Watching: MCPEval (paper)
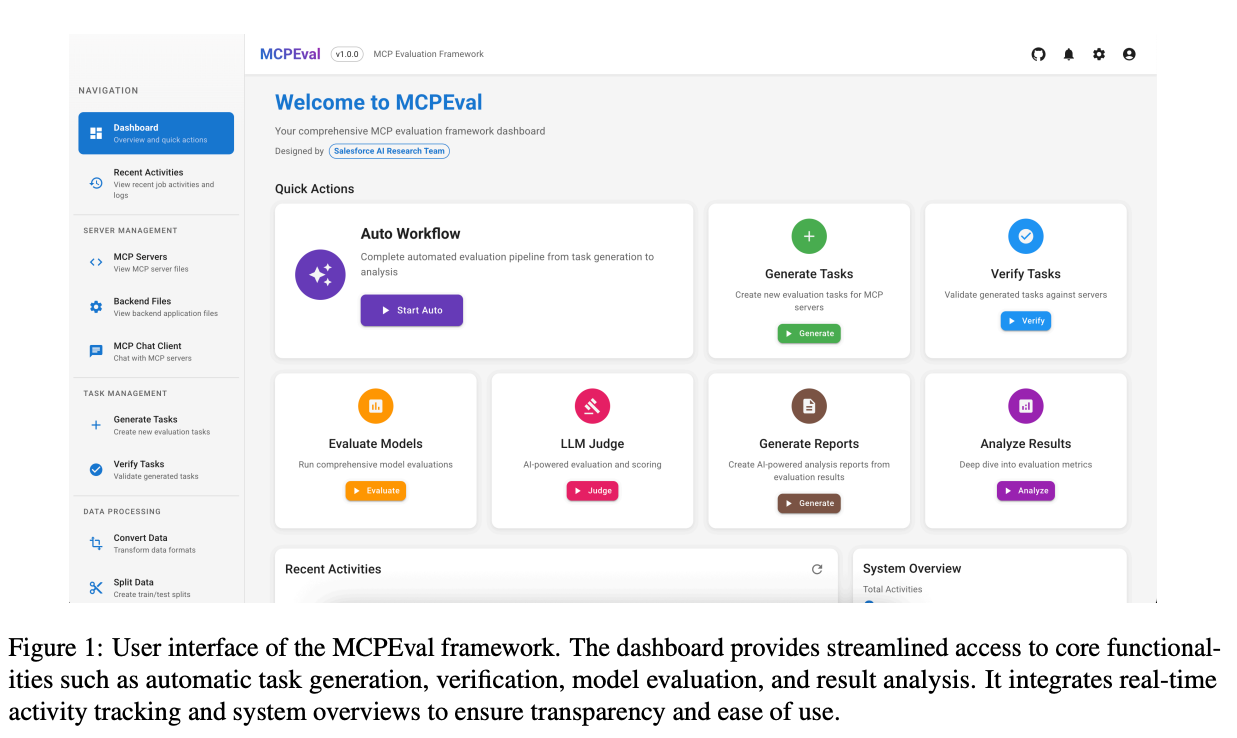
What problem does it solve? Evaluating AI agents is fundamentally broken. Current methods rely on static benchmarks that don't reflect real-world tool use, or labor-intensive manual evaluation that doesn't scale. As agents increasingly interact with external tools and APIs through protocols like Model Context Protocol (MCP), we need evaluation frameworks that can automatically assess end-to-end performance in realistic environments. How do you measure if an agent can successfully book a flight, analyze a spreadsheet, or coordinate across multiple tools?
How does it solve the problem? MCPEval leverages the MCP standard itself as an evaluation framework. It automatically generates task scenarios by introspecting available tools in MCP servers, creates ground-truth tool call sequences, and evaluates agents on both execution accuracy and trajectory quality. The framework operates in three stages: task generation (creating realistic scenarios based on available tools), verification (validating tasks are solvable), and evaluation (testing models on tool selection, parameter accuracy, and task completion). Because it's built on MCP, it seamlessly integrates with any MCP-compatible tools without manual configuration.
What are the key findings? Across five real-world domains (Finance, Airbnb, Healthcare, Sports, National Parks), MCPEval reveals striking performance variations between models. GPT-4 achieves 73% strict tool-matching accuracy, while other models range from 45-68%. More importantly, the framework uncovers nuanced failure modes: models often select correct tools but fail on parameter formatting, or generate plausible but incorrect tool sequences. The trajectory evaluation shows that even when final outputs are correct, intermediate steps often contain errors that could compound in longer interactions.
Why does it matter? MCPEval transforms agent evaluation from a manual, ad-hoc process to an automated, standardized protocol. For organizations deploying agents, it provides continuous integration-style testing for AI systems - automatically detecting regressions as tools or models change. The framework's ability to generate synthetic evaluation data also addresses the scarcity of real-world agent trajectories for training. As MCP adoption grows, MCPEval could become the standard for certifying agent capabilities, similar to how security frameworks certify system compliance.
7. Apple Intelligence Foundation Language Models: Tech Report 2025
Watching: Apple Intelligence (paper)
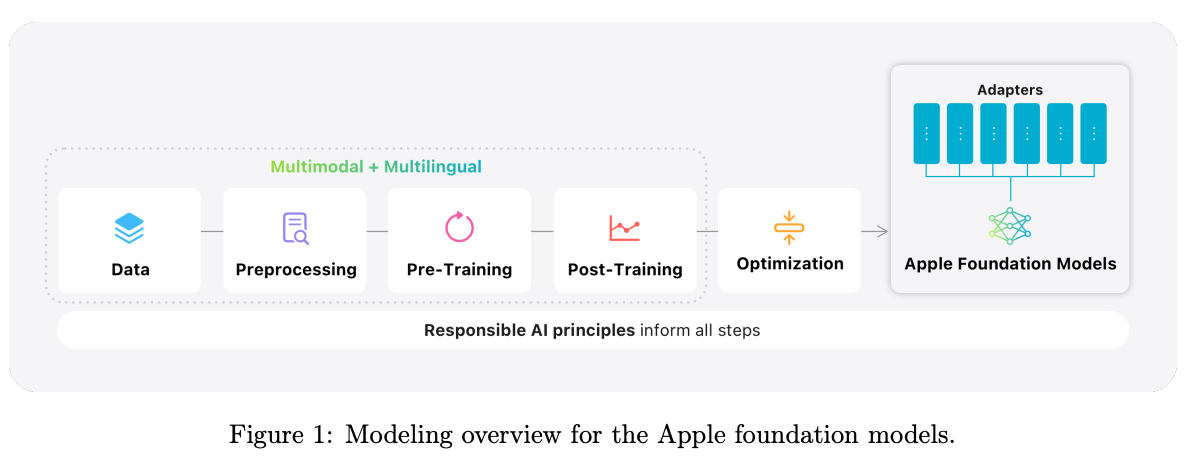
What problem does it solve? Building AI that runs efficiently on consumer devices while maintaining quality comparable to cloud models presents enormous technical challenges. Privacy concerns and latency requirements make cloud-only solutions insufficient for personal AI assistants. Yet cramming billion-parameter models onto phones and laptops requires extreme optimization without sacrificing capabilities. Apple needed models that could run on-device for privacy-critical tasks while seamlessly coordinating with server models for complex reasoning.
How does it solve the problem? Apple developed two complementary models: a ~3B parameter on-device model optimized through architectural innovations like KV-cache sharing and 2-bit quantization-aware training, and a server model using novel Parallel-Track Mixture-of-Experts (PT-MoE) that combines track parallelism with sparse computation. The on-device model underwent aggressive compression with minimal quality loss (4.6% regression on MGSM). Both models were trained on multilingual datasets with 30% non-English content, using synthetic data for math, code, and instruction following, while implementing careful filtering to exclude personal information.
What are the key findings? The technical innovations enable remarkable efficiency: 2-bit quantization reduces the on-device model size by 75% while maintaining performance, KV-cache sharing cuts memory requirements during inference, and the PT-MoE architecture achieves server-model quality at fraction of typical computational cost. Benchmark results show the 3B on-device model matching or exceeding larger models on many tasks. The expanded 150K token vocabulary (50% increase) dramatically improves multilingual performance. Notably, Apple's training explicitly excluded user data, relying instead on web crawling with opt-out mechanisms and synthetic data generation.
Why does it matter? It demonstrates that privacy-preserving, efficient AI is achievable without compromising quality. The architectural innovations - particularly 2-bit quantization with maintained accuracy - could enable a new generation of on-device AI applications. For developers, the Foundation Models framework provides direct access to these capabilities with just a few lines of code. As privacy regulations tighten globally, Apple's approach of strong on-device models coordinated with private cloud compute could become the standard architecture for consumer AI.
8. CUDA-L1: Improving CUDA Optimization via Contrastive Reinforcement Learning
Watching: CUDA-L1 (paper)
What problem does it solve? The explosive demand for GPU compute, driven by LLMs, makes CUDA optimization more critical than ever. Yet even expert engineers struggle with manual optimization, relying on trial-and-error to find optimal configurations. Current automated approaches, including advanced models like o1 and DeepSeek-R1, achieve less than 10% improvement on CUDA code. With GPU resources increasingly scarce and expensive, suboptimal CUDA kernels waste millions in compute costs. We need automated systems that can match or exceed human experts at GPU optimization.
How does it solve the problem? CUDA-L1 introduces contrastive reinforcement learning for CUDA optimization. Unlike traditional RL that evaluates code in isolation, contrastive RL learns by comparing pairs of implementations, effectively learning "this version is faster than that one." The system progresses through three stages: understanding CUDA patterns, self-supervised learning on correctness, and contrastive RL for speed optimization. The key innovation is using execution time differentials as rewards, enabling the model to learn optimization principles rather than memorizing specific patterns.
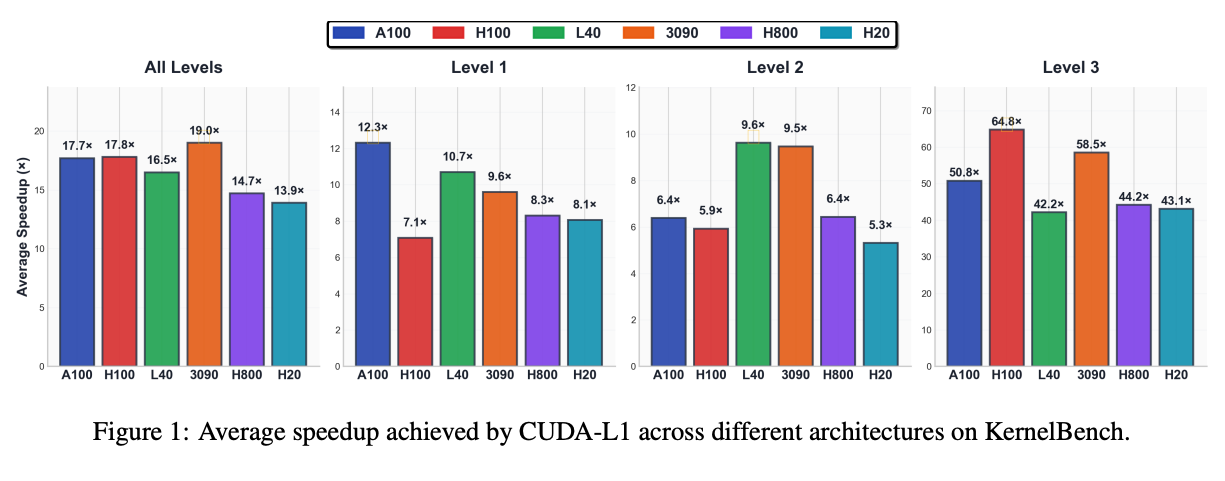
What are the key findings? CUDA-L1 achieves average speedups of 17.7x on KernelBench, with peak improvements reaching 449x. The model shows remarkable portability - trained on A100, it achieves 17.8x on H100, 19.0x on RTX 3090, without architecture-specific training. Analysis reveals CUDA-L1 discovers sophisticated optimization techniques: combining shared memory with vectorized loads, identifying non-obvious bottlenecks like CPU-GPU synchronization, and rejecting seemingly beneficial optimizations that actually harm performance. The model learns to balance multiple optimization strategies rather than applying them blindly.
Why does it matter? CUDA-L1 demonstrates that RL can transform domain-specific optimization from an expert skill to an automated process. For the AI industry facing GPU scarcity, automated CUDA optimization could effectively increase available compute by making existing resources drastically more efficient. The contrastive learning approach also has broader implications - it could be applied to database query optimization, compiler design, or any domain where performance comparison is easier than absolute measurement. As one implementation detail: training required only 50K iterations, suggesting this approach is practically deployable today.
9. Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty
Watching: (Non-)Binary Rewards (paper)
What problem does it solve? Current RL training for reasoning uses binary rewards - answers are either right (reward=1) or wrong (reward=0). This creates two problems: models become overconfident even when guessing, and they lose calibration on other tasks because the training signal encourages maximum certainty. In the real world, we need AI systems that can express uncertainty, say "I don't know," and provide confidence estimates. Binary rewards actively train models to hide their uncertainty, creating systems that confidently hallucinate rather than admitting limitations.
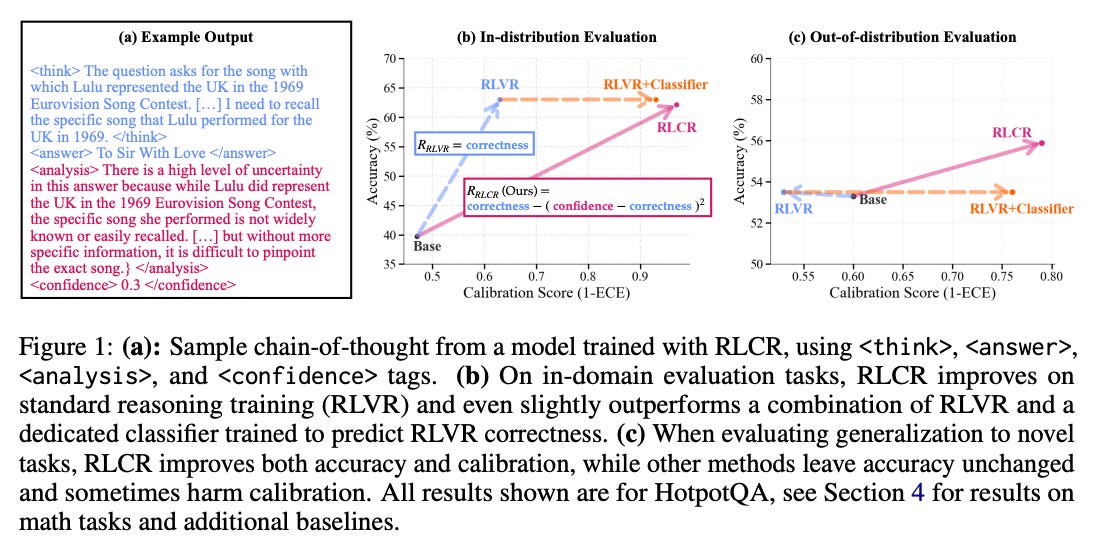
How does it solve the problem? RLCR (Reinforcement Learning with Calibration Rewards) replaces binary evaluation with multi-level feedback that encourages models to reason about uncertainty. During training, models can express confidence levels or explicitly state uncertainty. The reward function considers both correctness and calibration - a confident correct answer receives full reward, an uncertain correct answer receives partial reward, and appropriate expressions of uncertainty on impossible problems receive positive reward. The framework includes mechanisms for models to explain their reasoning process, identify missing information, and declare when problems are underspecified.
What are the key findings? RLCR dramatically improves both accuracy and calibration without sacrificing performance. On question-answering benchmarks, RLCR models achieve comparable accuracy to binary-reward training while improving calibration by 15-20%. More impressively, this calibration transfers to other domains - models trained with RLCR show better uncertainty estimates on completely different tasks. The models learn nuanced uncertainty expression: distinguishing between computational uncertainty ("this calculation is complex") versus epistemological uncertainty ("this requires information I don't have"). False positive rates on trick questions drop by 40%.
Why does it matter? As AI systems are deployed in high-stakes domains, their ability to express uncertainty becomes crucial. A medical AI that confidently gives wrong diagnoses is far more dangerous than one that appropriately expresses uncertainty. RLCR shows that we can train models to be both capable and calibrated without choosing between them. For developers, this means building AI systems that users can trust - not because they're always right, but because they accurately communicate their confidence levels.
Putting It All Together: The Maturation of AI Engineering
More and more AI systems are maturing from impressive demos to engineered products. We see multiple convergent themes:
From prompts to context orchestration - Context Engineering supersedes prompt engineering as systems grow more complex, requiring systematic management of multi-modal, multi-source information streams.
Test-time intelligence emergence - Rather than solving everything through larger pretraining, we see intelligence emerging from clever inference-time computation (MindJourney), multi-token prediction, and test-time scaling.
RL's untapped potential - Prolonged training reveals RL can discover genuinely novel strategies, while innovations like contrastive learning (CUDA-L1) and calibration rewards (RLCR) show domain-specific applications.
Engineering over scale - From Apple's efficient on-device models to QuestA's curriculum learning, the focus shifts from raw parameter count to architectural efficiency and training innovation.
The future of AI might not lie in monolithic models but in orchestrated systems that combine specialized components, adapt computation to task demands, and honestly communicate their uncertainties. As industry demand and adoption are growing rapidly, these systems need to mature from a research curiosity to an engineering discipline with principles, patterns, and practices that will define the next generation of intelligent systems.
What patterns do you see across these papers? Which developments will most impact your work with AI systems? Reply and share your thoughts.
Until next week, Pascal