
🗣️ Microsoft's Best Small Language Model
And research-backed prompt engineering

In this issue:
Microsoft’s best small language model
Graph Networks learning without a lot of labels
A new go-to resource for prompt engineering

1. Phi-4 Technical Report
Watching: Phi-4 (paper)

What problem does it solve? Phi-4 tackles the challenge of improving language model performance through a focus on data quality rather than simply increasing model size or compute. While most language models rely heavily on organic data sources like web content or code for pre-training, Phi-4 strategically incorporates synthetic data throughout the training process. This approach aims to address the limitations of traditional unsupervised datasets and enhance the model's reasoning and problem-solving abilities.
How does it solve the problem? Phi-4's training recipe revolves around three core pillars: 1) Synthetic data for pretraining and midtraining, carefully designed to prioritize reasoning and problem-solving; 2) Curation and filtering of high-quality organic data to extract seeds for the synthetic data pipeline and complement the synthetic datasets; 3) Advanced post-training techniques, including refined versions of SFT datasets and a new method for creating DPO pairs based on pivotal token search. These innovations enable Phi-4 to surpass its teacher model, GPT-4, on STEM-focused QA capabilities and achieve strong performance on reasoning-focused benchmarks despite its relatively small size.
What's next? The success of Phi-4 highlights the potential for further data quality improvements, in addition to gains traditionally achieved by scaling compute with model and dataset size. We can expect to see more emphasis on innovative data generation methods, optimized training curricula, and advanced post-training techniques. The Phi family of models has already demonstrated the effectiveness of this approach, and future iterations may further push the boundaries of what can be achieved with smaller, more efficient language models.
2. Can Graph Neural Networks Learn Language with Extremely Weak Text Supervision?
Watching: GNNs (paper)
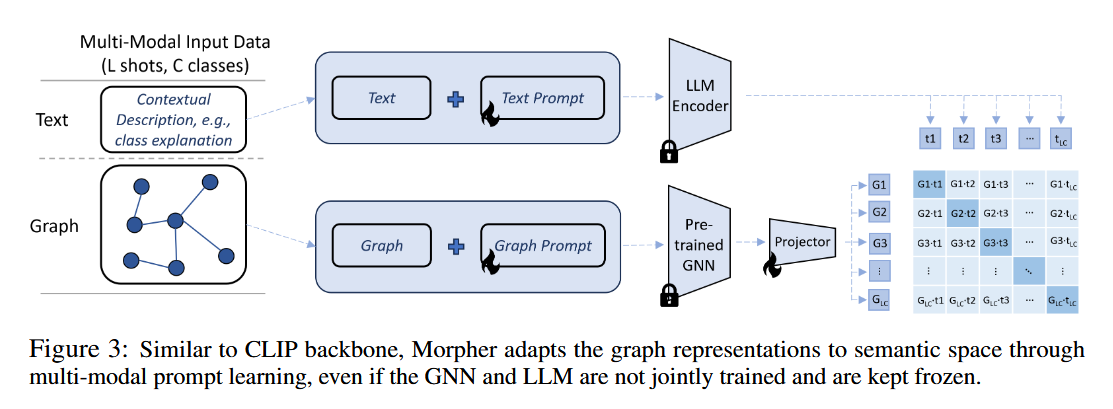
What problem does it solve? Graph Neural Networks (GNNs) have shown great potential in various domains, but their performance heavily relies on the availability of labeled data. Unlike in the vision domain, where CLIP (Contrastive Language-Image Pre-training) has enabled the creation of transferable models using Internet-scale image-text pairs, building transferable GNNs faces several challenges. These include the scarcity of labeled data and text supervision, different levels of downstream tasks, and conceptual gaps between domains.
How does it solve the problem? To address these challenges, the researchers propose a novel approach that leverages multi-modal prompt learning to adapt pre-trained GNNs to downstream tasks and data, even with limited labeled samples and weak text supervision. The key idea is to embed the graphs directly in the same space as Large Language Models (LLMs) by simultaneously learning graph prompts and text prompts. This is achieved by improving state-of-the-art graph prompt methods and introducing the first graph-language multi-modal prompt learning approach. Notably, the pre-trained GNN and LLM are kept frozen during this process, reducing the number of learnable parameters compared to fine-tuning.
What's next? The proposed paradigm demonstrates superior performance in few-shot, multi-task-level, and cross-domain settings, as shown through extensive experiments on real-world datasets. Moreover, the researchers have built the first CLIP-style zero-shot classification prototype that enables GNNs to generalize to unseen classes with extremely weak text supervision. This opens up new possibilities for applying GNNs in various domains where labeled data is scarce, and it paves the way for further research on multi-modal prompt learning and zero-shot learning in the graph domain.
3. The Prompt Canvas: A Literature-Based Practitioner Guide for Creating Effective Prompts in Large Language Models
Watching: Prompt Canvas (paper)

What problem does it solve? Prompt engineering has become a crucial skill for working with Large Language Models (LLMs). However, the knowledge and techniques in this field are scattered across various sources, making it challenging for practitioners to grasp and apply them effectively. The lack of a unified framework hinders the progress of both research and practical applications of prompt engineering.
How does it solve the problem? The authors propose the Prompt Canvas, a structured framework that synthesizes existing prompt engineering methodologies into a cohesive overview. The Prompt Canvas is the result of an extensive literature review and captures the current knowledge and expertise in the field. By combining conceptual foundations and practical strategies, it provides a practical approach for leveraging the potential of LLMs. The framework is designed as a learning resource, offering a structured introduction to prompt engineering for pupils, students, and employees.
What's next? The Prompt Canvas aims to contribute to the growing discourse on prompt engineering by establishing a unified methodology for researchers and providing guidance for practitioners. As prompt engineering continues to evolve, the framework can be further refined and expanded to incorporate new techniques and insights. The adoption of the Prompt Canvas by the research community and its application in real-world scenarios will be crucial in assessing its effectiveness and identifying areas for improvement.
Papers of the Week:
REGENT: A Retrieval-Augmented Generalist Agent That Can Act In-Context in New Environments
From Medprompt to o1: Exploration of Run-Time Strategies for Medical Challenge Problems and Beyond
ProcessBench: Identifying Process Errors in Mathematical Reasoning
The Pitfalls of Memorization: When Memorization Hurts Generalization
OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations
Is phi-4 the SLM? It seemed like a different subject from the one listed in your TOC.