
📉 May the Best Cheater Win
Learn about Qwen3, ThinkPRM, and the Leaderboard Illusion
Welcome, Watcher! This week, we're exploring three developments that reshape how AI models think, verify, and compete in the rapidly evolving landscape.
First, Qwen3 tackles the tension between "thinking deep" and "acting fast" with its innovative hybrid thinking design. From tiny 0.6B models to the massive 235B flagship, this family offers both careful reasoning and rapid response modes across 119 languages, democratizing access to powerful AI while letting users dial between computation budget and performance needs.
Next, ThinkPRM introduces a generative approach to verifying AI reasoning that outperforms traditional methods with just 1% of the training data. By teaching verifiers to "think" through their own chain-of-thought, this breakthrough makes reliable reasoning verification more accessible, interpretable, and scalable for real-world applications.
Finally, "The Leaderboard Illusion" pulls back the curtain on how major AI providers game the Chatbot Arena. Their rigorous audit reveals how asymmetric data access, private model variants, and silent model retirements distort what should be an objective measure of progress - an important reminder that benchmarks themselves need careful design to remain meaningful.
The underlying trends? Democratizing access to powerful AI capabilities, finding more efficient paths to reliable reasoning, and ensuring transparency in how we measure progress. Whether balancing depth and speed, reimagining verification, or maintaining benchmark integrity, these developments all point toward making powerful AI both more accessible and more trustworthy.
Don't forget to subscribe to never miss an update again.
1. Qwen3: Think Deeper, Act Faster
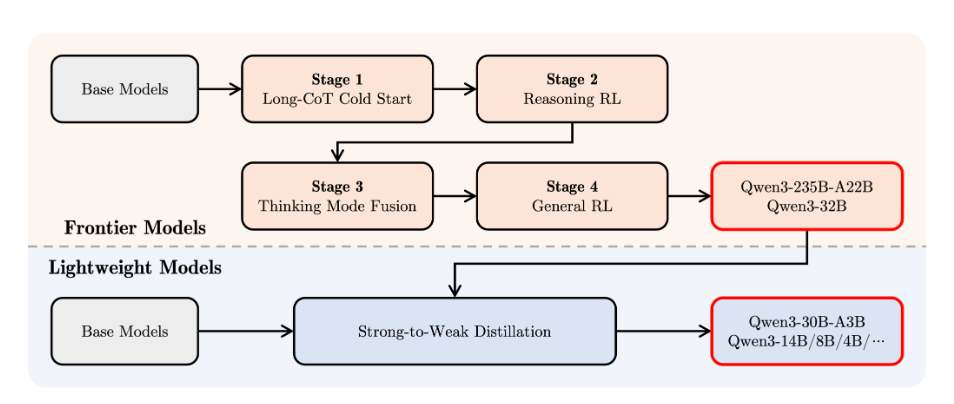
What problem does it solve? Large language models today often force users to choose between “thinking deep” (high-quality reasoning but slow and costly) and “acting fast” (quick replies but shallow understanding). Bigger models give better answers but eat up compute, while smaller ones are cheap but struggle on tough tasks. Practitioners need flexible, efficient models that scale smoothly from tiny devices to massive servers, support long contexts and many languages, and balance speed, cost, and reasoning depth.
How does it solve the problem? The Qwen3 family - a spectrum of dense and Mixture-of-Experts (MoE) models from 0.6B to a 235B-parameter flagship - comes with a novel “hybrid thinking” design. Each model supports two modes: a careful, step-by-step reasoning mode and a rapid “instant answer” mode. They pre-trained on 36 trillion tokens across 119 languages, then post-trained in four stages (chain-of-thought cold start, reinforcement learning for reasoning, fusion of thinking/non-thinking skills, and broad RL for general tasks). This pipeline, plus sparse activation in MoE variants and context windows up to 128K tokens, ensures both efficiency and high capability.
What are the key findings? Qwen3-235B-A22B matches or outperforms leading models like Gemini-2.5-Pro on coding, math, and general benchmarks. The smaller MoE model, Qwen3-30B-A3B, beats a 32B dense counterpart while only activating 3B parameters. Even Qwen3-4B rivals a 72B model from Qwen2.5. Dense Qwen3-base models achieve the same or better performance as much larger Qwen2.5 bases, especially in STEM and reasoning. Overall, users can seamlessly dial between reasoning budget and latency, and enjoy support for 119 languages and ultra-long contexts.
Why does it matter? By offering high accuracy with dramatically reduced active compute, Qwen3 democratizes state-of-the-art LLMs - making them accessible on more hardware and budgets. The hybrid thinking modes let developers tailor cost versus quality on a per-task basis. Broad multilingual coverage and long-context handling unlock new global and document-heavy applications. Altogether, Qwen3 moves us closer to adaptable, efficient AI agents that can both think deeply when needed and respond instantly when speed matters.
2. Process Reward Models That Think
Watching: ThinkPRM (paper/code)

What problem does it solve? Large language models often “think” through problems by exploring many possible solution paths, but deciding which path is actually correct requires a verifier - or process reward model (PRM) - that judges each reasoning step. Traditional PRMs are “discriminative” classifiers trained on massive step-by-step annotations, making them expensive and slow to scale at test time. Meanwhile, using an off-the-shelf LLM “as a judge” is data-efficient but unreliable: it can hallucinate, overthink, or loop infinitely when checking complex reasoning.
How does it solve the problem? ThinkPRM is a generative verifier that itself “thinks” through a detailed chain-of-thought (CoT) to check each step of a solution. Starting from open-weight reasoning models, they generate a small synthetic dataset of high-quality verification CoTs - only 1 000 examples matched to gold step labels - and fine-tune via low-rank adapters (LoRA). At test time, ThinkPRM can be sampled multiple times (best-of-N) or prompted to “verify again” to dynamically scale its checking compute without retraining.
What are the key findings? ThinkPRM, trained on just 1 % of the data used by discriminative PRMs, outperforms both LLM-as-a-judge and discriminative baselines by up to 8 F1 points on in-domain benchmarks (ProcessBench, MATH-500, AIME ’24). It also generalizes better out-of-domain (science QA and code generation), boosting accuracy by 4–8 points despite using far fewer labels. Moreover, ThinkPRM’s generative design lets it leverage extra inference compute - sampling more CoTs or self-correcting - to yield further gains.
Why does it matter? By showing that a generative, chain-of-thought verifier can match or beat heavyweight discriminative models with minimal supervision, this work paves the way for more interpretable, data-efficient, and compute-scalable checking of LLM reasoning. In practice, THINK PRM makes it far cheaper to deploy reliable step-by-step verifiers, unlocking robust real-world applications of LLMs in education, math, science, and beyond.
3. The Leaderboard Illusion
Watching: Leaderboard Illusion (paper)

What problem does it solve? Chatbot Arena is a live, human‐voted leaderboard for comparing AI chatbots, but it’s been distorted by a handful of big providers. These companies quietly run dozens of private model variants, choose only their highest scores to publish, sample their models far more often, and silently retire weaker ones. As a result, the leaderboard no longer reflects true model quality - winning the Arena has become more about gaming the system than about genuine progress.
How does it solve the problem? The researchers performed a comprehensive audit of over 2 million battles from January 2024 to April 2025, combining public and privately shared datasets. By scraping random battles and probing models to reveal hidden names, they mapped out private testing practices and measured each provider’s sampling rate. They ran statistical simulations of best‐of‐N selection bias, conducted real‐world experiments with identical checkpoints, and examined how unannounced deprecations violate the Bradley–Terry ranking assumptions under a shifting prompt distribution.
What are the key findings? They found extreme data‐access asymmetries: Meta ran 27 private variants, Google and OpenAI each captured over 19 % of all vote data, while 83 open-source models shared just 29.7 %. Even limited additional Arena data boosted a small model’s win-rate by up to 112 % on in-distribution tests. Moreover, 205 of 243 public models were silently deprecated - four times the number officially listed -creating fragmented match graphs and unreliable rankings.
Why does it matter? These dynamics exemplify Goodhart’s Law: once benchmark scores become a target, they lose their value as measures of real progress. Left unchecked, the Arena rewards tactical overfitting and concentrates benefits in a few hands, eroding trust and misguiding research. By outlawing score retraction, capping private variants, enforcing clear retirement rules, and adopting fair sampling, Chatbot Arena can restore its role as a transparent, scientifically sound measure of AI capability.

Papers of the Week:
Limited training data restricts LLMs' math ability; synthetic data and Think, Prune, Train, which uses self-generated reasoning and pruning, address this. Gemma2-2B achieves 57.6% Pass@1 on GSM8K. Gemma2-9B reaches 82%, matching LLaMA-3.1-70B, while LLaMA-3.1-70B attains 91%, surpassing GPT-4o.
This article presents a framework overcoming LLM limitations in automated clinical interviews and alignment with diagnostic protocols, using multi-agent collaboration and Psychometric Chain-of-Thought for better mental healthcare. It transforms the MINI into workflows, using an interview tree guided navigation agent, adaptive question agent, and judgment agent. Testing involved 1,002 participants, covering depression, anxiety and suicide.
This survey examines advancements in LLM inference serving for Generative AI, addressing high memory overhead and computational demands that hinder low latency and high throughput. It covers instance-level approaches like model placement, decoding length prediction, and the disaggregation paradigm, plus cluster-level strategies such as multi-instance load balancing.
AutoJudge accelerates LLM inference via lossy speculative decoding, using semi-greedy search and a lightweight classifier to accept mismatches. On GSM8K (Llama 3.2 1B/8B), it achieves 1.5x speedup with minimal answer accuracy degradation. Applied to LiveCodeBench, AutoJudge identifies programming-specific important tokens, generalizing across tasks while maintaining speedups.
To address LLMs' inconsistent multi-session dialogues arising from fixed context windows, Mem0, a memory-centric architecture leveraging graph-based memory, dynamically extracts information. Evaluated on the LOCOMO benchmark, Mem0 surpasses retrieval-augmented generation and OpenAI, yielding 26% improvement in the LLM-as-a-Judge metric, 91% lower p95 latency, and reduced token cost.