
👁️🗨️ LLMs Opening Their Inner Eyes
And drastic cost reductions for pre-training LLaMA-2 level models

In this issue:
LLaMA-2 performance at 0.001x the price
Trying to unify LLM evaluation
How the “Mind’s Eye” might help LLMs to “think” better

1. JetMoE: Reaching LLaMA2 Performance with 0.1M Dollars
Watching: JetMoE (report/code)
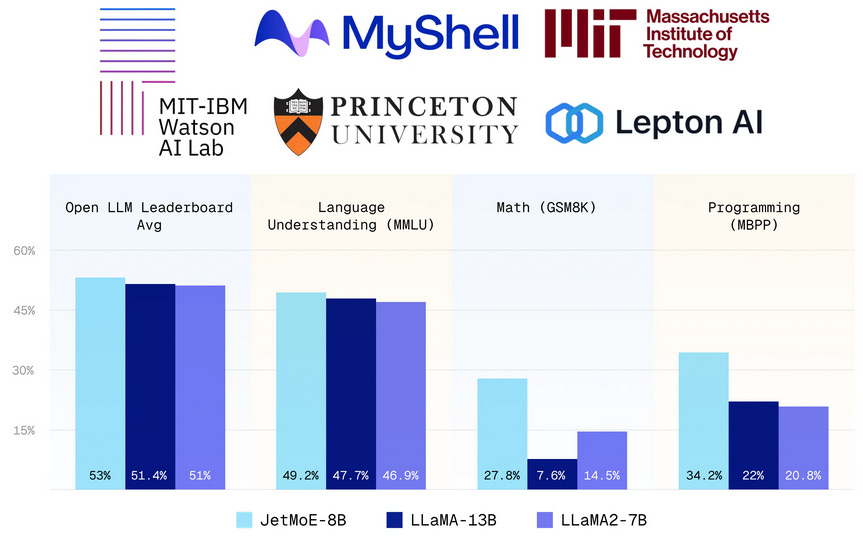
What problem does it solve? Training Large Language Models (LLMs) has been notoriously expensive, with some models like GPT-3 costing over $10 million to train. This has led to a concentration of LLM development in a few well-resourced labs, limiting the democratization and diversity of these powerful AI tools. JetMoE-8B demonstrates that high-performing LLMs can be trained at a fraction of the cost, potentially opening up LLM research and application to a much wider range of institutions and developers.
How does it solve the problem? JetMoE-8B leverages a sparsely activated architecture inspired by ModuleFormer. While the model has 8 billion parameters in total, only 2.2 billion parameters are active during inference. This is achieved through the use of Mixture of Experts (MoE) layers, specifically Mixture of Attention heads (MoA) and Mixture of MLP Experts. Each MoA and MoE layer has 8 experts, but only 2 experts are activated for each input token. This sparse activation drastically reduces computational cost during inference while still allowing the model to learn from a large parameter space during training.
What's next? The development of JetMoE-8B could mark a significant shift in the accessibility of LLM technology. By demonstrating that high-performing models can be trained at a relatively low cost using only publicly available resources, this work may inspire more labs to research model pre-training.
2. Evalverse: Unified and Accessible Library for Large Language Model Evaluation
Watching: Evalverse (paper/code)
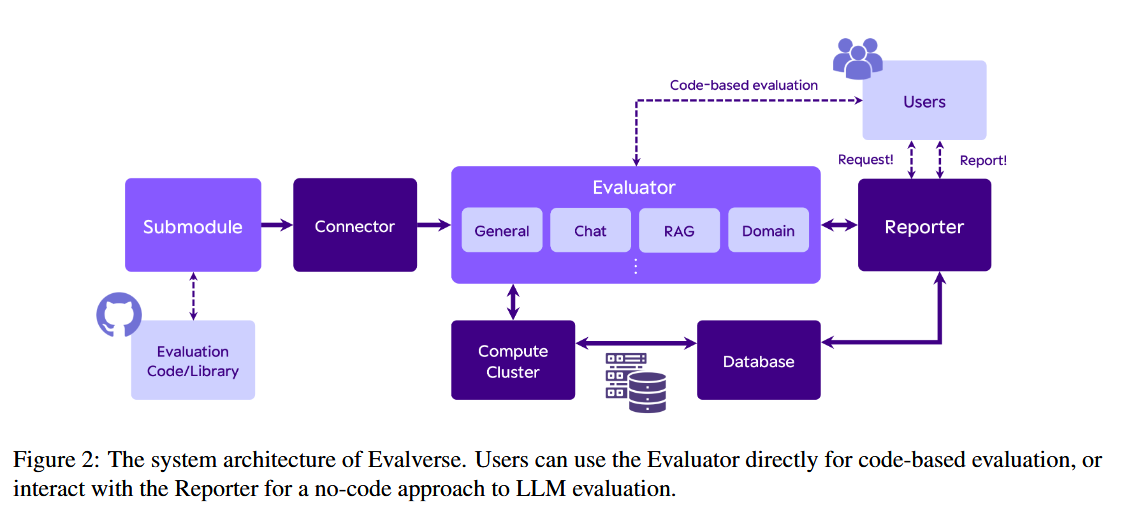
What problem does it solve? Evaluating Large Language Models (LLMs) can be a challenging task, especially for individuals without extensive AI expertise. The process often involves using multiple disparate tools, which can be time-consuming and complex. This fragmented approach to LLM evaluation makes it difficult for researchers and practitioners to comprehensively assess the performance of these models, hindering progress in the field.
How does it solve the problem? Evalverse addresses this issue by providing a unified, user-friendly framework that integrates various evaluation tools into a single library. By centralizing the evaluation process, Evalverse simplifies the task of assessing LLMs, making it accessible to a wider audience. The library's integration with communication platforms like Slack further enhances its usability, allowing users to request evaluations and receive detailed reports with ease.
What's next? The introduction of Evalverse opens up new possibilities for the widespread adoption of LLM evaluation. As more researchers and practitioners begin to utilize this centralized framework, we can expect to see a proliferation of insights into the performance and capabilities of LLMs. This, in turn, may drive further advancements in the field, as the increased accessibility of evaluation tools enables a broader range of individuals to contribute to the development and refinement of these powerful models.
3. Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models
Watching: VoT (paper)
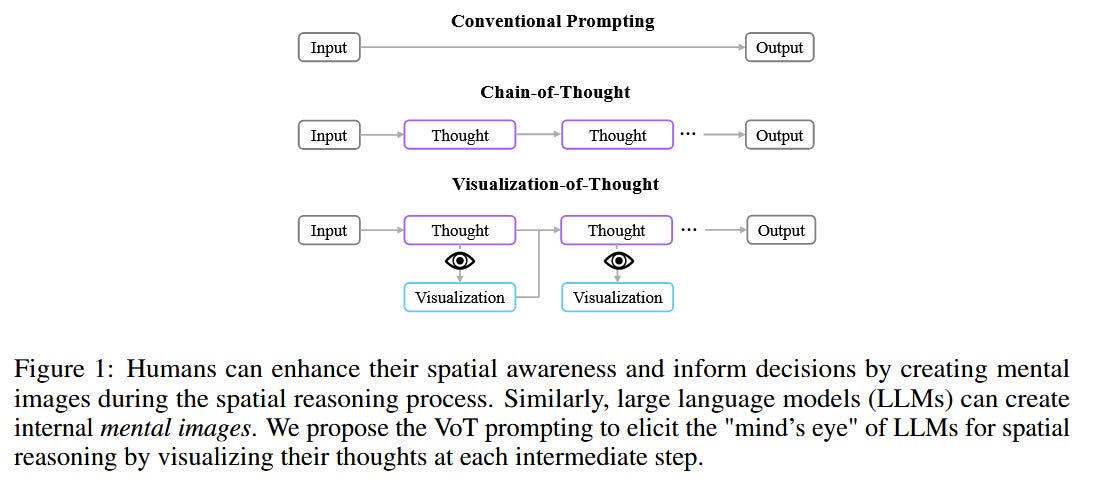
What problem does it solve? Spatial reasoning, the ability to understand and manipulate spatial relationships between objects, is a fundamental aspect of human cognition. While Large Language Models (LLMs) have shown remarkable performance in various language comprehension and reasoning tasks, their capabilities in spatial reasoning have not been extensively explored. The Mind's Eye, a cognitive process that allows humans to create mental images of unseen objects and actions, is a key component of spatial reasoning. Developing methods to enhance spatial reasoning abilities in LLMs could lead to more human-like reasoning and problem-solving capabilities.
How does it solve the problem? Visualization-of-Thought (VoT) prompting is a novel approach that aims to improve the spatial reasoning abilities of LLMs by visualizing their reasoning traces and using these visualizations to guide subsequent reasoning steps. VoT prompting draws inspiration from the Mind's Eye process, enabling LLMs to generate mental images that facilitate spatial reasoning. The researchers applied VoT prompting to multi-hop spatial reasoning tasks, such as natural language navigation, visual navigation, and visual tiling in 2D grid worlds. By visualizing the reasoning traces of LLMs, VoT prompting provides a means to elicit and enhance spatial reasoning capabilities.
What's next? The experimental results demonstrate that VoT prompting significantly improves the spatial reasoning abilities of LLMs, even outperforming existing multimodal large language models (MLLMs) in the studied tasks. The success of VoT prompting in LLMs suggests its potential viability in MLLMs as well. Future research could focus on extending VoT prompting to more complex spatial reasoning tasks, exploring its applicability to other domains, and investigating the integration of VoT prompting with MLLMs to potentially get the best of both worlds.
Papers of the Week:
Unleashing the Potential of Large Language Models for Predictive Tabular Tasks in Data Science
Transformer-Lite: High-efficiency Deployment of Large Language Models on Mobile Phone GPUs
Dataverse: Open-Source ETL (Extract, Transform, Load) Pipeline for Large Language Models