
♻️ LLMs Are Improving Themselves
And why you don't need a giant model for RAG

In this issue:
Self-correcting LLMs
The 4 levels of RAG and beyond
9B model beating GPT-4o in RAG

MLOps/GenAI World is all about solving real-world problems and sharing genuine experiences with production-grade AI systems.
Want to learn from some of the best practitioners in the world?
Join leaders and engineers from Microsoft, Huggingface, BlackRock and many more with your personal 15% discount.
1. Training Language Models to Self-Correct via Reinforcement Learning
Watching: Self-Correcting LLMs (paper/code)
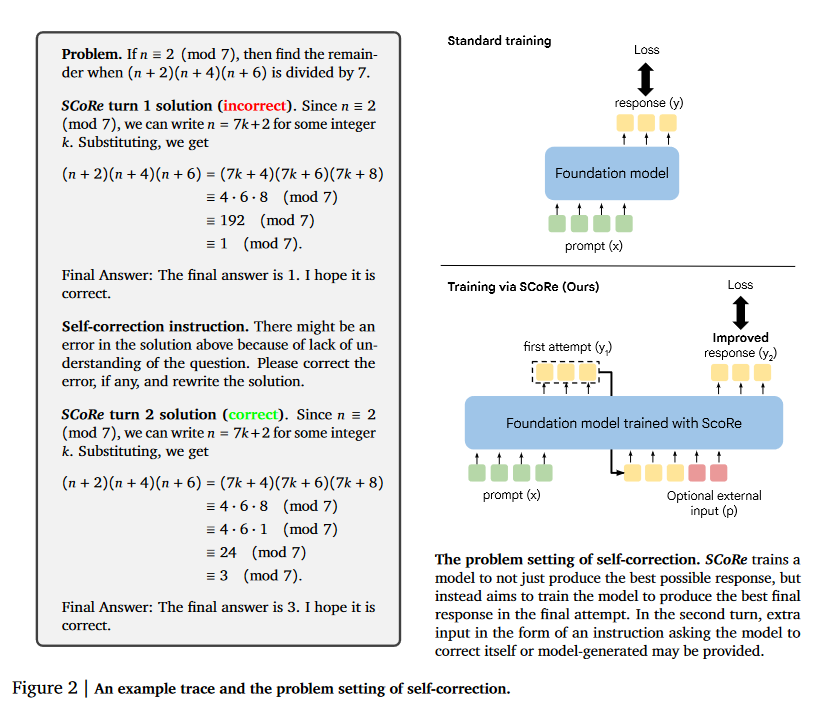
What problem does it solve? Self-correction is a highly desirable capability for Large Language Models (LLMs), as it allows them to identify and rectify their own mistakes without relying on external feedback or supervision. However, despite the rapid advancements in LLM technology, self-correction has consistently been found to be largely ineffective in modern LLMs. Existing approaches for training self-correction either require multiple models or rely on a more capable model or other forms of supervision, which can be resource-intensive and impractical in many real-world scenarios.
How does it solve the problem? SCoRe (Self-Correction via Reinforcement) is a multi-turn online reinforcement learning approach that significantly improves an LLM's self-correction ability using entirely self-generated data. The key innovations of SCoRe are twofold: (1) It trains the model under its own distribution of self-generated correction traces, addressing the distribution mismatch issue faced by supervised fine-tuning (SFT) approaches. (2) It employs appropriate regularization techniques to steer the learning process towards learning an effective self-correction strategy, rather than simply fitting high-reward responses for a given prompt. This regularization involves running a first phase of RL on a base model to generate a policy initialization that is less susceptible to collapse, followed by using a reward bonus to amplify self-correction during training.
What's next? Further refinements to the SCoRe approach, such as exploring alternative regularization techniques or incorporating domain-specific knowledge, could potentially lead to even greater improvements in self-correction performance. Additionally, investigating the scalability and generalizability of SCoRe to other LLM architectures and domains could help establish it as a standard technique for enhancing the self-correction capabilities of LLMs.
2. Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely
Watching: RAG and beyond (paper)

What problem does it solve? Large Language Models (LLMs) have shown impressive capabilities in various tasks, but their performance can be further enhanced by integrating external data. However, effectively deploying data-augmented LLMs across different specialized domains presents significant challenges. These challenges include retrieving relevant data, accurately interpreting user intent, and fully leveraging the reasoning capabilities of LLMs for complex tasks. A one-size-fits-all solution is not feasible, and underperformance often stems from failing to identify the core focus of a task or not disentangling the multiple capabilities required for better resolution.
How does it solve the problem? The survey proposes a Retrieval-Augmented Generation (RAG) task categorization method that classifies user queries into four levels based on the type of external data needed and the primary focus of the task: explicit fact queries, implicit fact queries, interpretable rationale queries, and hidden rationale queries. By defining these query levels, providing relevant datasets, and summarizing the key challenges and most effective techniques for each level, the survey helps readers understand and decompose the data requirements and key bottlenecks in building LLM applications. Additionally, the survey discusses three main forms of integrating external data into LLMs: context, small model, and fine-tuning, highlighting their strengths, limitations, and the types of problems they are best suited to solve.
What's next? As LLMs continue to evolve and become more powerful, the integration of external data will play an increasingly crucial role in enhancing their performance and enabling them to tackle complex real-world tasks. Future research should focus on developing more sophisticated techniques for retrieving and integrating relevant external data, as well as improving the interpretability and reasoning capabilities of LLMs. Additionally, there is a need for more diverse and comprehensive datasets that cover a wide range of specialized domains to support the development and evaluation of data-augmented LLM applications. By addressing these challenges and leveraging the insights provided in this survey, researchers and practitioners can systematically develop more effective and efficient LLM applications across various fields.
3. SFR-RAG: Towards Contextually Faithful LLMs
Watching: SFR-RAG (paper)
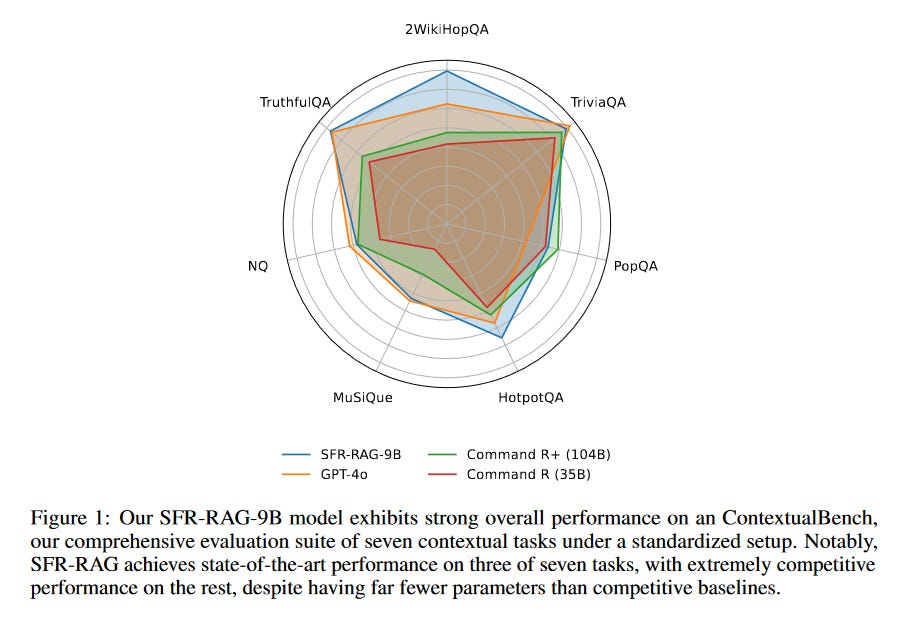
What problem does it solve? Retrieval Augmented Generation (RAG) aims to enhance the factual accuracy and relevance of Large Language Models (LLMs) by integrating external contextual information. However, existing RAG models often struggle with faithfully comprehending the provided context, avoiding hallucination, handling low-quality or irrelevant contexts, performing complex multi-hop reasoning, and producing reliable citations. These challenges hinder the effectiveness and reliability of RAG applications.
How does it solve the problem? SFR-RAG addresses the limitations of existing RAG models by introducing a small LLM that is specifically instruction-tuned for context-grounded generation and hallucination minimization. The model is trained to faithfully understand the provided context, avoid generating false information, handle challenging scenarios such as unanswerable or counterfactual questions, and perform multi-hop reasoning. Additionally, SFR-RAG is designed to produce reliable citations, enhancing the trustworthiness of its generated responses. The authors also introduce ContextualBench, a standardized evaluation framework that compiles diverse RAG benchmarks with consistent settings, enabling reproducible and consistent model assessments.
What's next? The impressive performance of SFR-RAG, despite its significantly smaller size compared to leading baselines, highlights the potential for developing efficient and effective RAG models. Future research could explore further optimizations to the instruction-tuning process, as well as investigating the scalability of SFR-RAG to larger model sizes. Additionally, the introduction of ContextualBench opens up opportunities for standardized evaluation and comparison of RAG models, fostering progress in this important area of generative AI.
👍 If you enjoyed this article, give it a like and share it with your peers.
Papers of the Week:
Programming Every Example: Lifting Pre-training Data Quality like Experts at Scale
A Preliminary Study of o1 in Medicine: Are We Closer to an AI Doctor?
HelloBench: Evaluating Long Text Generation Capabilities of Large Language Models