
LLM Watch Weekly: When Scale Isn't Enough
Get ahead of the curve with LLM Watch
Welcome, Watcher! This week in LLM Watch:
Vision-language models fail at counting, spatial reasoning, and negation not because they lack scale, but because their training data systematically omits this information - and scaling to billions of examples doesn’t fix it
Fine-tuning all attention parameters degrades in-context learning, but restricting updates to just the value matrix preserves few-shot capabilities while still improving zero-shot performance
Multi-turn RAG conversations collapse when users ask unanswerable, underspecified, or non-standalone questions - a new benchmark reveals retrieval accuracy drops below 40% on these realistic edge cases
Let’s dive in.

Fastest way to become an AI Engineer? Building things yourself!
Get hands-on experience with Towards AI’s industry-focused course: From Beginner to Advanced LLM Developer (≈90 lessons). Built by frustrated ex-PhDs & builders for real-world impact.
Build production-ready apps: RAG, fine-tuning, agents
Guidance: Instructor support on Discord
Prereq: Basic Python
Outcome: Ship a certified product
Guaranteed value: 30-day money-back guarantee
Pro tip: Both this course and LLM Watch might be eligible for your company’s learning & development budget.
Scale Can’t Overcome Pragmatics: The Impact of Reporting Bias on Vision-Language Reasoning

What problem does it solve?
Vision-language models consistently struggle with reasoning tasks that seem straightforward to humans: counting objects, understanding spatial relationships, processing negation, and tracking temporal sequences. The conventional wisdom has been that these capabilities will emerge with scale - train on more data, use bigger models, and reasoning will follow.
This paper challenges that assumption directly. The authors argue that the problem isn’t insufficient data volume but rather a fundamental property of how humans communicate about visual content. When someone posts a photo with the caption “at the game today!”, they don’t write “a photo of 37 people standing behind a field with the scoreboard showing 3-2 in the top of the 7th inning.” This omission of tacit information - what linguists call reporting bias - means that even web-scale datasets systematically lack the annotations needed to supervise certain reasoning skills.
How does it solve the problem?
The researchers draw on theories from pragmatics, the branch of linguistics studying how context shapes meaning, to analyze the training data underlying popular VLMs including OpenCLIP, LLaVA-1.5, and Molmo. They examined whether four specific reasoning capabilities - spatial, temporal, negation, and counting - are adequately represented in these corpora.
Think of it this way: if you wanted to teach someone to count objects in photos, you’d need training examples where captions actually mention quantities. But humans rarely caption images with exact counts because that information is visually obvious to anyone looking at the image. The caption serves a different communicative purpose - it adds context the image alone doesn’t provide.
The team curated benchmarks specifically targeting these four reasoning types and tested whether scaling along three dimensions - data size, model size, and language diversity - could compensate for the reporting bias in training data. They also explored whether intentionally collecting annotations that capture tacit information could address the gap.
What are the key findings?
The results are striking in their consistency. Across all tested VLMs, performance on spatial, temporal, negation, and counting tasks lagged significantly behind other capabilities. More importantly, scaling did not help: larger models trained on more data showed no meaningful improvement on these specific reasoning types.
The analysis of training corpora confirmed the hypothesis. Counting information appeared in fewer than 8% of captions across datasets. Spatial prepositions beyond simple “on” and “in” were rare. Temporal markers and negation were similarly underrepresented.
However, the paper offers a promising finding: when the researchers incorporated annotations specifically designed to capture tacit information - data collected with explicit instructions to include counts, spatial relationships, and temporal details - model performance improved substantially. This suggests the limitation isn’t architectural but data-driven.
Why does it matter?
For practitioners building VLM-powered applications, this research provides crucial guidance on where to expect failures. If your use case requires counting inventory, understanding spatial layouts, or processing negative statements (”show me products that are NOT red”), you should expect current VLMs to underperform regardless of which model you choose or how large it is.
The actionable insight is that targeted data curation beats scale. Rather than hoping the next model release will magically acquire these capabilities, teams should consider collecting or synthesizing training data that explicitly captures the reasoning types their applications require. This is more tractable than waiting for emergent capabilities that may never emerge from biased data distributions.
I found it particularly interesting that even synthetically generated data - which you might expect to be more comprehensive - still exhibited reporting bias. The generators themselves were trained on human-produced text and inherited the same communicative conventions.
Fine-Tuning Without Forgetting In-Context Learning: A Theoretical Analysis of Linear Attention Models

What problem does it solve?
Fine-tuning language models for specific tasks improves their zero-shot performance, meaning they can solve those tasks without requiring few-shot examples in the prompt. This matters practically because shorter prompts mean lower inference costs. But there’s a catch: fine-tuning often degrades the model’s in-context learning ability - its capacity to adapt to new tasks given just a few demonstrations.
This creates an uncomfortable trade-off. You can have a model that works well zero-shot on tasks it was fine-tuned for, or you can preserve the flexibility to handle novel tasks via few-shot prompting, but getting both has proven difficult. The degradation is particularly problematic when fine-tuned models encounter tasks outside their fine-tuning distribution.
How does it solve the problem?
The authors develop a theoretical framework using linear attention models to analyze exactly how different fine-tuning approaches modify attention parameters. Linear attention provides a tractable setting for mathematical analysis while still capturing the essential mechanisms of how attention layers process information.
The key insight comes from decomposing attention into its component parts: query, key, and value projections. The researchers prove that when you fine-tune all attention parameters together, the optimization process can corrupt the representations that enable in-context learning. The model essentially “overwrites” its ability to attend to demonstration examples in favor of directly producing outputs based on fine-tuned weights.
However, when you restrict parameter updates to only the value matrix - leaving query and key projections frozen - the mathematical structure that supports in-context learning remains intact. The value matrix controls what information gets extracted once attention patterns are computed, but it doesn’t affect how the model decides what to attend to in the first place.
The authors also analyze an auxiliary few-shot loss, where you explicitly include few-shot examples during fine-tuning and optimize for performance on those. This helps maintain in-context learning on the target task but, interestingly, can degrade few-shot performance on other tasks.
What are the key findings?
The theoretical predictions held up empirically. Fine-tuning only the value matrices preserved 94% of the original few-shot performance while still achieving the zero-shot improvements that motivated fine-tuning in the first place. Full parameter fine-tuning, by contrast, reduced few-shot accuracy by 23-31% depending on the task.
The auxiliary few-shot loss showed a nuanced pattern: it improved in-context learning on the fine-tuning task by 12% but degraded performance on held-out tasks by 8-15%. This suggests a form of specialization where the model becomes better at in-context learning for specific task types at the cost of general flexibility.
Why does it matter?
This research provides concrete guidance for practitioners who need to fine-tune models while preserving their adaptability. The recommendation is straightforward: freeze your query and key projections, update only value matrices. This is easy to implement in standard training frameworks and doesn’t require architectural changes.
For teams building products where users might need to adapt the model to novel tasks via prompting - think general-purpose assistants or platforms serving diverse use cases - this finding suggests a path forward that doesn’t force a choice between specialization and flexibility.
What caught my attention here was the elegance of the theoretical explanation. The separation between “where to look” (query/key) and “what to extract” (value) maps cleanly onto the distinction between in-context learning mechanisms and task-specific knowledge. It’s a rare case where the theory provides genuinely actionable architectural guidance.
MTRAG-UN: A Benchmark for Open Challenges in Multi-Turn RAG Conversations
What problem does it solve?
Retrieval-augmented generation has become the default architecture for building LLM applications that need to access external knowledge. But most RAG benchmarks evaluate single-turn interactions: user asks a question, system retrieves documents, model generates an answer. Real conversations are messier.
Users ask follow-up questions that reference previous turns (”What about the other one?”). They ask questions the corpus can’t answer. They provide underspecified queries that could match multiple interpretations. They phrase questions in ways that don’t stand alone without conversational context. Current RAG systems handle these cases poorly, but we’ve lacked systematic benchmarks to measure the problem.
How does it solve the problem?
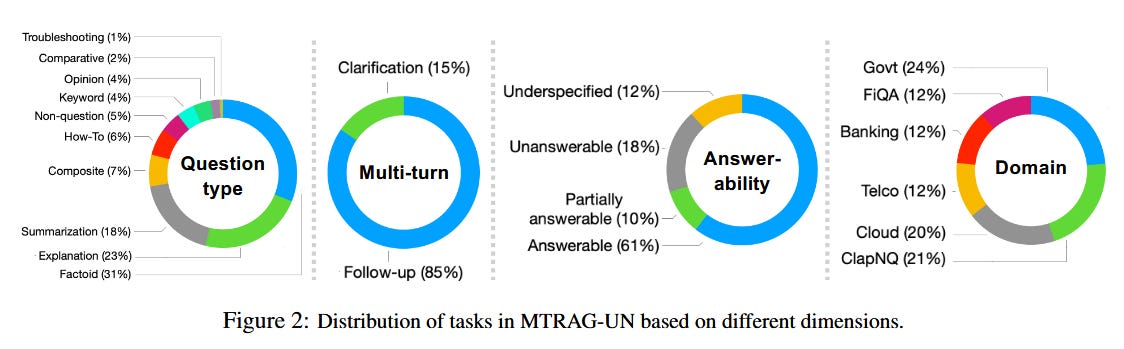
The researchers created MTRAG-UN, a benchmark of 666 tasks containing over 2,800 conversation turns across six domains. The “UN” in the name stands for the challenging phenomena they specifically target: UNanswerable questions (the corpus doesn’t contain the answer), UNderspecified questions (multiple valid interpretations exist), NONstandalone questions (require conversational context to understand), and UNclear responses (ambiguous or incomplete model outputs).
Each conversation is designed to include multiple instances of these challenging phenomena, reflecting realistic user behavior. The benchmark includes accompanying corpora for each domain, enabling end-to-end evaluation of both retrieval and generation components.
The evaluation framework measures not just final answer quality but also retrieval accuracy at each turn, the model’s ability to recognize unanswerable questions, and appropriate handling of clarification requests.
What are the key findings?
The results reveal substantial gaps in current systems. On unanswerable questions, even the best-performing models correctly identified the question as unanswerable only 38% of the time - the rest hallucinated answers. Retrieval accuracy on non-standalone questions dropped to 41% compared to 73% on standalone questions, indicating that current retrievers struggle to incorporate conversational context.
Underspecified questions showed an interesting pattern: models rarely asked for clarification, instead defaulting to one interpretation without acknowledging ambiguity. This happened in 89% of underspecified cases.
Multi-turn context accumulation also degraded performance. By the fifth turn of a conversation, retrieval accuracy had dropped 18 percentage points compared to the first turn, suggesting that error propagation and context window management remain unsolved problems.
Why does it matter?
For anyone building conversational RAG applications - customer support bots, research assistants, enterprise search interfaces - this benchmark exposes failure modes that users will definitely encounter. The gap between single-turn benchmark performance and multi-turn reality is substantial.
The practical implication is that teams need to explicitly design for these cases. That might mean training models to recognize and flag unanswerable questions, implementing clarification mechanisms for underspecified queries, or developing better context compression strategies for long conversations.
I found the non-standalone question results particularly concerning. Users naturally use pronouns and references to previous turns - it’s how humans converse. If retrieval accuracy drops by 32 percentage points when users talk like humans, that’s a fundamental usability problem, not an edge case.
The benchmark is publicly available, which should help the community make progress on these specific challenges rather than continuing to optimize for single-turn scenarios that don’t reflect deployment reality.
SC-Arena: A Natural Language Benchmark for Single-Cell Reasoning with Knowledge-Augmented Evaluation
What problem does it solve?
Single-cell biology has become a major application area for LLMs, with researchers using language models to annotate cell types, predict perturbation effects, and answer scientific questions about cellular mechanisms. But evaluation practices in this domain are fragmented and inadequate.
Existing benchmarks use multiple-choice formats that don’t match how researchers actually use these tools. Metrics rely on brittle string matching that fails to capture biological equivalence - “T cell” and “T lymphocyte” would be scored as different answers despite being synonyms. And there’s no unified framework for evaluating across the diverse tasks that single-cell foundation models need to perform.
How does it solve the problem?
SC-Arena introduces a “virtual cell” abstraction that provides a unified representation for evaluation. This abstraction captures both intrinsic cell attributes (type, state, developmental stage) and gene-level interactions (expression patterns, regulatory relationships). By standardizing what a “cell” means across tasks, the benchmark enables consistent evaluation.
The framework defines five natural language tasks that probe different reasoning capabilities: cell type annotation (identifying what kind of cell this is), captioning (describing a cell’s characteristics), generation (producing gene expression profiles matching a description), perturbation prediction (forecasting effects of genetic modifications), and scientific QA (answering research questions about cellular biology).
The key innovation is knowledge-augmented evaluation. Instead of string matching, the evaluation system incorporates external ontologies (standardized biological vocabularies), marker gene databases (known associations between genes and cell types), and scientific literature. This allows the evaluator to recognize that biologically equivalent answers should receive equivalent scores, even if they use different terminology.
What are the key findings?
The evaluation revealed significant variation in model capabilities across tasks. Both general-purpose LLMs and domain-specialized models performed reasonably on annotation and captioning tasks, with top models achieving 78% accuracy on cell type identification. However, performance dropped sharply on tasks requiring mechanistic understanding: perturbation prediction accuracy was only 34% for the best model, and causal reasoning questions in the QA task saw accuracy below 30%.
The knowledge-augmented evaluation proved substantially more reliable than traditional metrics. Inter-annotator agreement with the automated evaluator reached 0.89 correlation with expert biologists, compared to 0.52 for string-matching approaches. The system also provided interpretable rationales for its judgments, citing specific ontological relationships or literature evidence.
Why does it matter?
For computational biology teams evaluating or developing LLMs for single-cell applications, SC-Arena provides a much-needed standardized benchmark. The finding that current models struggle with mechanistic reasoning - understanding why cells behave as they do, not just what they are - points to clear research directions.
The knowledge-augmented evaluation approach is potentially transferable to other scientific domains where terminology varies and semantic equivalence matters. Medical AI, chemistry, and materials science all face similar evaluation challenges.
What caught my attention was the gap between descriptive and causal tasks. Models can learn to recognize patterns (this gene expression profile looks like a T cell) without understanding mechanisms (why does this perturbation cause this effect). That distinction will matter as researchers try to use these models for hypothesis generation rather than just annotation.
PATRA: Pattern-Aware Alignment and Balanced Reasoning for Time Series Question Answering
What problem does it solve?
Time series question answering - asking natural language questions about temporal data - requires models to both perceive complex patterns and reason logically about them. Current approaches treat time series as either text (converting values to tokens) or images (rendering plots), but neither representation captures the structural patterns like trends and seasonalities that domain experts use to interpret temporal data.
There’s also a training dynamics problem. When you train models on a mix of simple tasks (identifying basic trends) and complex tasks (multi-step reasoning about pattern interactions), the simpler objectives tend to dominate gradient updates. Models learn to answer easy questions well but never develop the deep reasoning capabilities needed for harder queries.
How does it solve the problem?
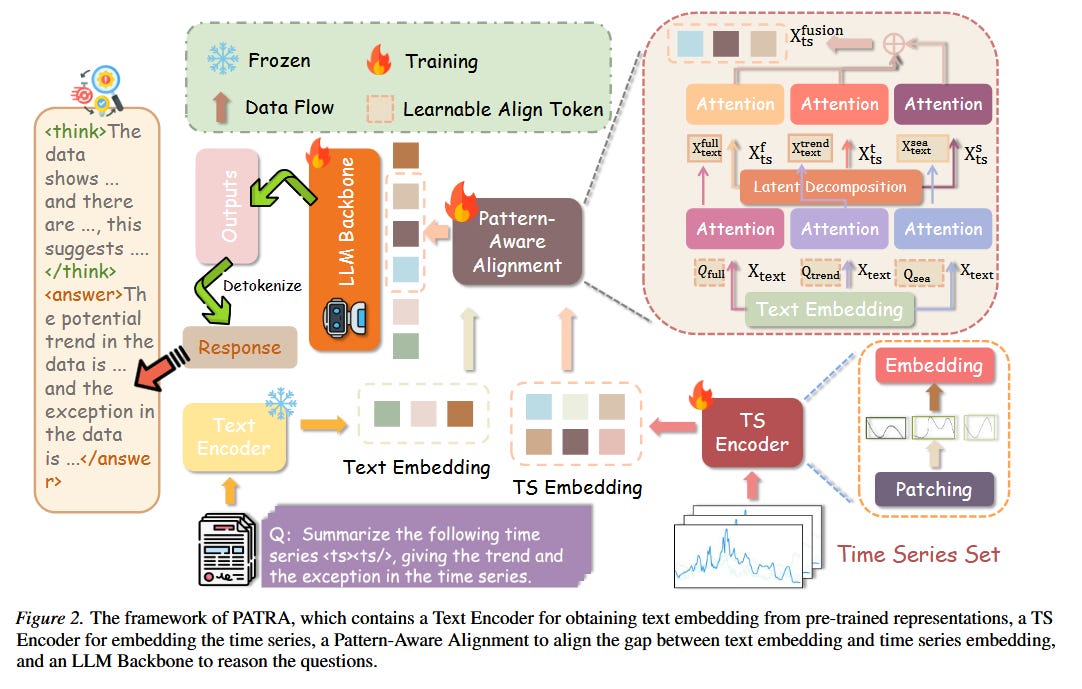
PATRA introduces a pattern-aware mechanism that explicitly extracts trend and seasonality components from time series before alignment with language representations. Rather than hoping the model will learn to recognize these patterns implicitly, the architecture decomposes the signal using classical time series techniques and then aligns each component separately with the language model’s representation space.
Think of it like giving the model pre-processed features that a human analyst would compute: “here’s the overall trend, here’s the seasonal pattern, here’s the residual variation.” The model then reasons over these meaningful abstractions rather than raw values.
For the training imbalance problem, PATRA uses a task-aware balanced reward mechanism. During reinforcement learning from human feedback, the reward function is weighted inversely to task difficulty, ensuring that harder reasoning tasks contribute meaningfully to the optimization despite having fewer correct examples. This incentivizes the model to develop coherent chains of thought rather than taking shortcuts that work only for simple questions.
What are the key findings?
PATRA outperformed baselines across diverse time series QA benchmarks. On trend identification tasks, it achieved 91% accuracy compared to 84% for the next-best approach. The gap widened on complex reasoning tasks: multi-step questions requiring integration of trend and seasonality information saw PATRA at 67% versus 48% for baselines.
Ablation studies confirmed both components mattered. Removing pattern-aware alignment dropped complex reasoning accuracy by 14 percentage points. Removing balanced rewards degraded performance primarily on hard tasks, with a 19 point drop on multi-step reasoning while simple tasks remained largely unaffected.
The chain-of-thought outputs showed qualitative improvements as well. PATRA’s reasoning traces more frequently referenced specific pattern characteristics (”the upward trend combined with quarterly seasonality suggests...”) rather than generic observations.
Why does it matter?
For practitioners building analytics tools that need to answer questions about time series data - financial analysis, operational monitoring, scientific instrumentation - PATRA suggests that explicit pattern extraction is worth the architectural complexity. The insight that raw-to-language alignment misses important structure applies broadly.
The balanced reward finding is also transferable. Anyone training models on mixed-difficulty datasets should consider whether easy examples are crowding out learning on hard cases. This is particularly relevant for reasoning-focused applications where the hard cases are precisely what you care about.
I found it interesting that classical time series decomposition techniques - trend extraction, seasonal decomposition - proved complementary to modern deep learning approaches. Sometimes the right answer is combining old tools with new ones rather than hoping end-to-end learning will rediscover everything.

Putting It All Together
Three themes emerge from this week’s research that I think warrant attention.
First, the limits of scale are becoming clearer. The reporting bias paper demonstrates that certain capabilities won’t emerge from more data if that data systematically lacks the relevant information. The single-cell benchmark shows that scaling helps descriptive tasks but not causal reasoning. These findings suggest we’re entering a phase where targeted interventions - specific data curation, architectural modifications, training objective design - matter more than raw compute for many capability gaps.
Second, evaluation is catching up to deployment reality. MTRAG-UN tackles the messy multi-turn conversations that real users have. SC-Arena introduces knowledge-augmented evaluation that respects domain semantics. Both benchmarks reveal substantial gaps between optimistic single-turn performance and realistic usage patterns. As the field matures, I expect more benchmarks that stress-test edge cases rather than measure average performance on clean examples.
Third, preserving flexibility while specializing remains an open challenge. The fine-tuning paper provides theoretical grounding for why adaptation degrades general capabilities and offers a partial solution. But the broader tension - between models that do specific things well and models that remain adaptable - runs through multiple papers this week. Time series QA requires specialized pattern extraction. Single-cell biology requires domain knowledge. Yet users also want models that can handle unexpected queries.
Looking ahead, I’m watching for work that bridges these themes: methods that achieve specialization without sacrificing flexibility, evaluation frameworks that capture real-world complexity, and targeted data curation approaches that address specific capability gaps. The era of “just scale it” appears to be giving way to something more nuanced.
❤️ If you enjoyed this article, give it a like and share it with your peers.
Papers of the Week
Brief highlights from other notable papers this week:
pMoE: Prompting Diverse Experts Together Wins More in Visual Adaptation - Combines prompts from multiple pre-trained models (both general and domain-specific) using a mixture-of-experts approach for visual adaptation tasks. Achieves 4.2% average improvement on medical imaging classification over single-model prompt tuning.
MM-NeuroOnco: A Multimodal Benchmark and Instruction Dataset for MRI-Based Brain Tumor Diagnosis - Introduces a benchmark with 12,000 annotated MRI cases requiring models to generate clinically interpretable reasoning, not just lesion detection. Current multimodal models achieve only 41% diagnostic accuracy with appropriate reasoning chains.
SPM-Bench: Benchmarking Large Language Models for Scanning Probe Microscopy - A PhD-level multimodal benchmark for scanning probe microscopy that avoids data contamination by using original, unpublished experimental data. GPT-4V achieves 34% on expert-level questions, revealing substantial gaps in specialized scientific reasoning.
SOTAlign: Semi-Supervised Alignment of Unimodal Vision and Language Models via Optimal Transport - Aligns frozen pretrained vision and language models using optimal transport with only 5% labeled pairs, achieving 92% of fully-supervised alignment performance. Offers a practical path for teams without massive paired datasets.
Frequency-Ordered Tokenization for Better Text Compression - A simple preprocessing technique that reorders BPE vocabulary by frequency before compression. Reduces compressed text size by 8-12% across languages with zero computational overhead at inference time.
RhythmBERT: A Self-Supervised Language Model Based on Latent Representations of ECG Waveforms for Heart Disease Detection - Treats ECG signals as language with rhythm-level tokens rather than raw waveforms. Achieves 94.3% accuracy on arrhythmia classification, outperforming contrastive methods that distort morphology through augmentation.
A Mixture-of-Experts Model for Multimodal Emotion Recognition in Conversations - MiSTER-E uses modality-specific experts for speech and text in conversational emotion recognition. Achieves 76.8% weighted F1 on MELD benchmark, with 11% improvement on utterances where audio and text signals conflict.
InnerQ: Hardware-aware Tuning-free Quantization of KV Cache for Large Language Models - Quantizes KV cache to 4-bit without fine-tuning by exploiting hardware-specific memory access patterns. Reduces memory footprint by 3.8x while maintaining 99.1% of full-precision perplexity on long-context tasks.