
LLM Watch Papers of the Week
Get ahead of the curve in five minutes
Welcome, Watcher! This week in LLM Watch:
Scaling up reinforcement learning for language models
Unifying neural vs. symbolic AI
New strategies for LLM-based agents
And much more!
Don’t forget to subscribe to never miss an update again.

Fastest way to become an AI Engineer? Building things yourself!
Get hands-on experience with Towards AI’s industry-focused course: From Beginner to Advanced LLM Developer (≈90 lessons). Built by frustrated ex-PhDs & builders for real-world impact.
Build production-ready apps: RAG, fine-tuning, agents
Guidance: Instructor support on Discord
Prereq: Basic Python
Outcome: Ship a certified product
Guaranteed value: 30-day money-back guarantee
Pro tip: Both this course and LLM Watch might be eligible for your company’s learning & development budget.
Scaling Reinforcement Learning for LLMs
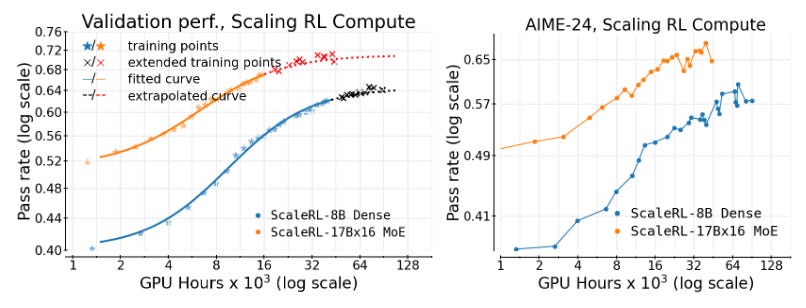
Predictable Scaling of RL Compute (paper): A Meta & collaborators study provides the first large-scale analysis (400k GPU-hours!) of how RL fine-tuning scales for LLMs. They fit sigmoidal compute-performance curves and find that many design choices (loss aggregation, normalization, etc.) mainly affect compute efficiency but not final performance. With these insights, they introduce a best-practice recipe “ScaleRL” that extrapolates small-run learning curves to predict final performance. Using ScaleRL, they successfully forecast a 100k GPU-hour run’s result, moving RL training closer to the predictability of pre-training.
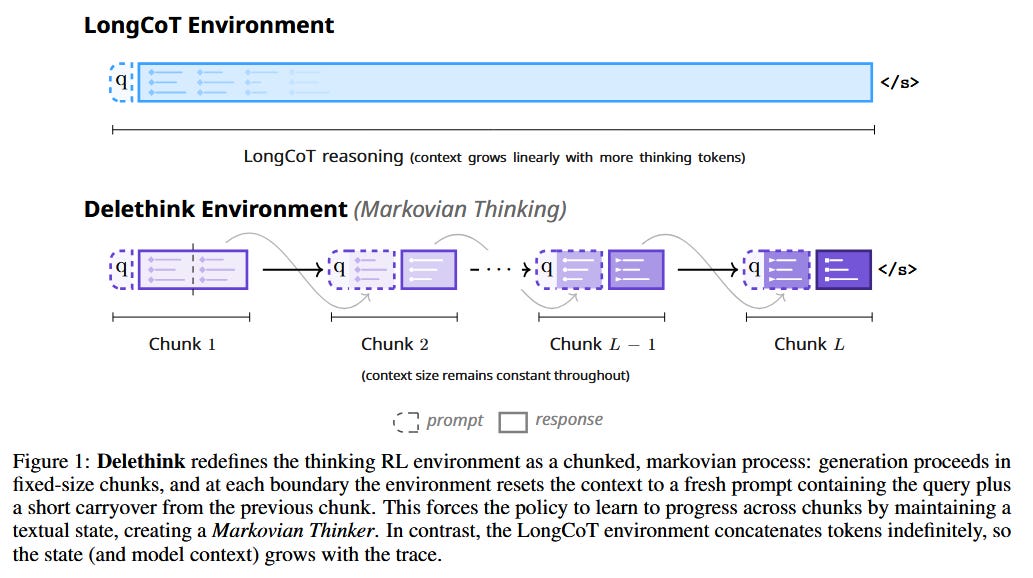
“Markovian Thinker” for Long Reasoning (paper): Long chain-of-thought reasoning typically forces an LLM agent to condition on an ever-growing prompt (making RL policies pay quadratic cost as thoughts get longer). Aghajohari et al. propose Markovian Thinking, reformulating the RL “thinking environment” so the model only ever sees a fixed-size state. In their Delethink setup, reasoning is chunked into segments: the model generates a brief state summary at each chunk’s end, then resets context and continues fresh with that summary. This yields linear-time, constant-memory scaling. A 1.5B model trained with Delethink can reason for 24k tokens in 8k-token chunks, matching or beating a baseline trained with full 24k-token context. Even more impressively, it continues to improve with longer reasoning (96k tokens), while the baseline plateaus - at roughly one-quarter of the computing cost (estimated 7 H100-months vs 27 for the baseline). Redesigning the environment, not just the model, thus enables efficient, scalable long-term reasoning.
RL Fine-Tuning Unlocks Reasoning Abilities
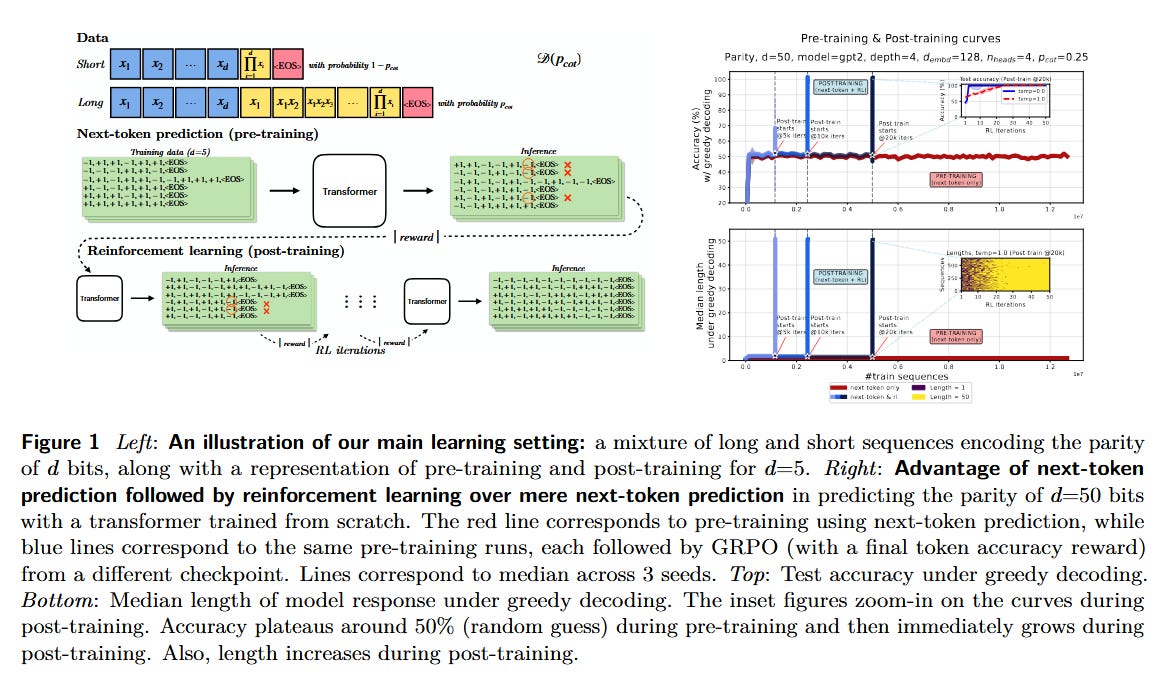
Why RL Helps LLMs Reason (paper): Tsilivis et al. tackle the question of how RL fine-tuning (after next-token pre-training) boosts reasoning. They introduce a theoretical framework showing that after pre-training, applying RL enables models to solve tasks requiring long chain-of-thought with far less data than next-token prediction alone. Essentially, RL rewards the final outcome of a multi-step reasoning chain, letting the model leverage longer test-time computation (longer answers) to learn the task. For example, in a toy parity task with mostly short examples, an RL-finetuned transformer generalizes correctly using long chains, whereas a purely next-token-trained one would need exponentially more data. They also confirm the effect on real models: RL finetuning LLaMA on mixture-of-experts math problems yields better generalization by exploiting longer reasoning steps.
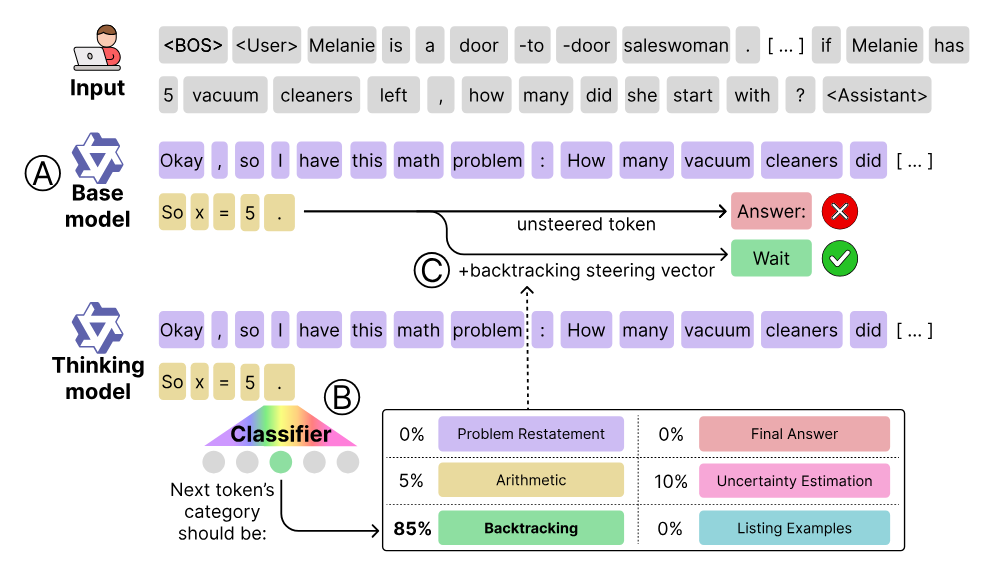
“Base” vs “Thinking” Models - Knowing How vs When (paper): Are chain-of-thought “thinking” models fundamentally more capable, or just better at using base model skills? Venhoff et al. find it’s largely the latter. By injecting small steering vectors into a frozen base model’s activations at just ~12% of positions, they can trigger the model’s latent reasoning abilities and recover ~91% of the performance gap up to a full chain-of-thought trained model - all with no weight updates. This implies large pre-trained LLMs already “know how” to reason, and what specialized finetuning really does is teach them when to deploy those skills. In other words, pre-training equips the model with reasoning mechanisms, and post-training (“thinking” model training) mainly teaches efficient use of those mechanisms at the right time. This insight reframes how we view advanced reasoning LLMs: much of the reasoning prowess was latent in the base model all along.
New Paradigms for LLM Agents and Tool-Use
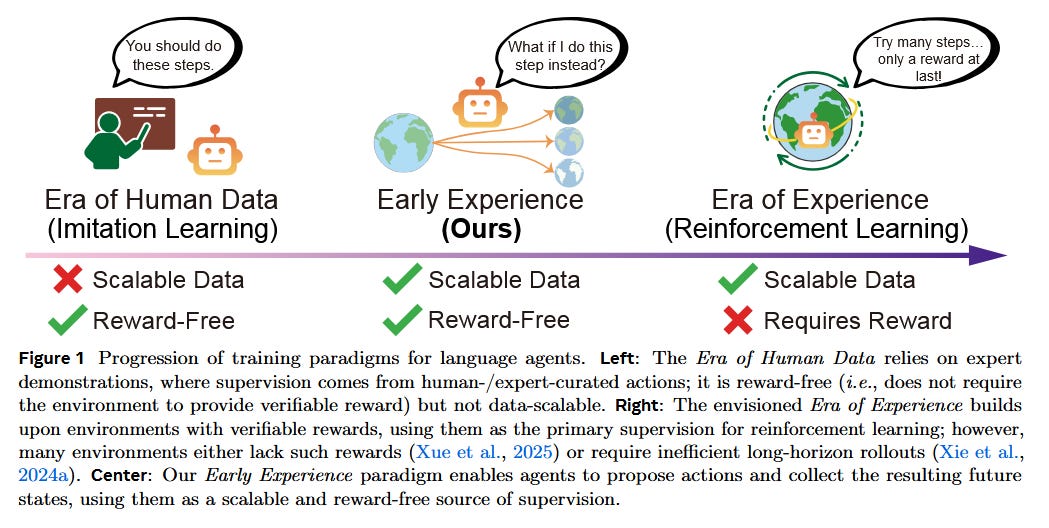
Early Experience Instead of Pure Imitation (paper): Meta’s* “Agent Learning via Early Experience” proposes a middle ground between static imitation learning and full reinforcement learning. Rather than relying solely on narrow expert demos (which don’t expose environment diversity), they let the agent collect its own interaction data without rewards - called “early experience”. Two uses of this data are explored: (1) Implicit world models, where the agent trains on its collected states to ground its policy in how the environment behaves, and (2) Self-reflection, where the agent learns from its mistakes (suboptimal actions) to improve reasoning. Across 8 environments, these strategies improve performance and out-of-domain generalization, effectively bridging the gap between imitation and fully autonomous agents. Notably, even when eventual rewards are available, early experience provides a strong foundation that makes subsequent RL more effective.
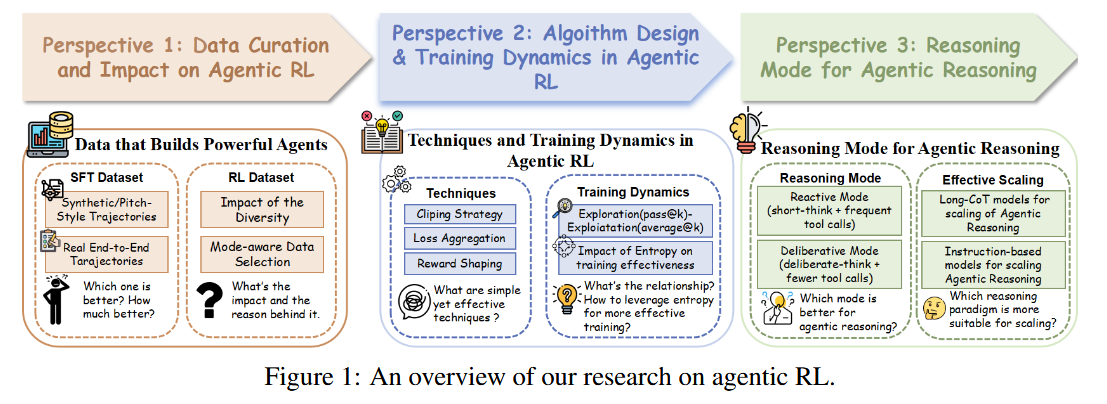
Best Practices for Agentic RL (paper): In “Demystifying RL in Agentic Reasoning,” Yu et al. systematically evaluate how to get the most out of RL when training tool-using LLM agents. They identify a few simple but powerful practices: (i) Use real, end-to-end tool-use trajectories rather than stitched-together snippets - this yields a much stronger initialization for supervised fine-tuning and ensures diverse, model-aware experience data. High-diversity datasets prevent the agent from overfitting and help sustain exploration. (ii) Employ exploration-friendly techniques - for example, allowing higher clipping thresholds, shaping rewards over longer horizons, and maintaining sufficient policy entropy - to encourage the agent to try novel solutions, greatly boosting RL training efficiency. (iii) Favor a deliberative reasoning strategy with fewer, more targeted tool calls over very frequent calls or overly verbose self-dialogues. In other words, teaching the agent to think a bit more before acting leads to better tool efficiency and final accuracy. Using these tips, they achieve state-of-the-art results on challenging benchmarks with smaller LLMs, even getting a 4B model to outperform a 32B model on agentic reasoning tasks. They also release a high-quality supervised and RL dataset of agent trajectories to help others replicate these gains.
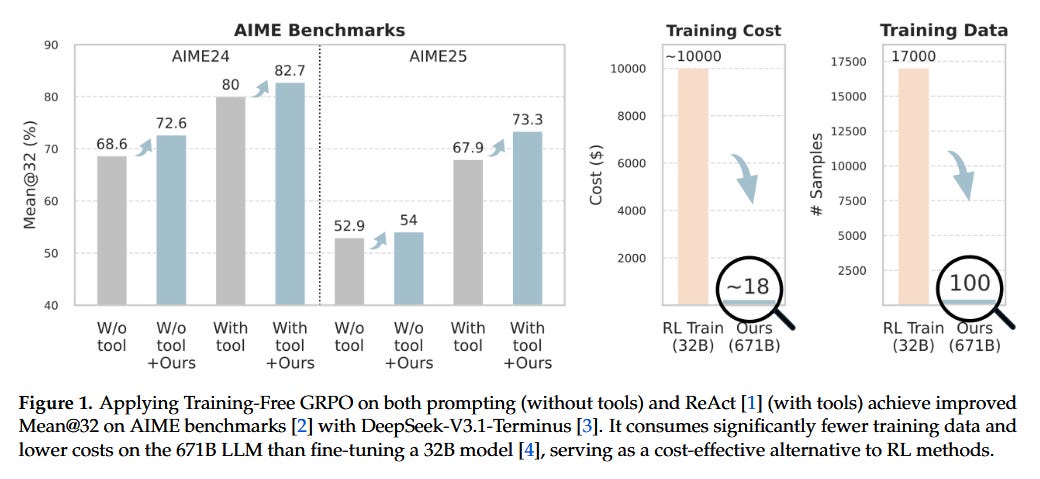
Training-Free RL via Token Priors (paper): Reinforcement learning usually means updating model weights - but Cai et al. show you can get policy improvements without any finetune. Their “Training-Free Group RPO” method treats the base LLM as fixed and instead adjusts the output token distribution on the fly using experience. During deployment, the agent generates multiple rollouts; within each group of rollouts, the method computes a “group relative semantic advantage” for tokens (think: which tokens led to better outcomes) and distills this into a token-level prior to bias the model’s next decisions. By iterating this process over a few epochs (with only a handful of ground-truth examples as reference), the LLM acquires “experiential knowledge” that steers its outputs, all without gradient updates. In tasks like math reasoning and web search, adding this lightweight loop to a state-of-the-art agent (DeepSeek) significantly improved out-of-domain performance. In fact, with only a few dozen examples, the training-free approach outperformed fully finetuned smaller LLMs - at a fraction of the cost and time, since it avoids any traditional RL training phase.
Tensor Logic: Unifying Neural and Symbolic AI

Pedro Domingos proposes Tensor Logic (paper), an ambitious new programming language designed as the “language of AI” that natively fuses neural and symbolic approaches. The motivation is that current tools are lacking: frameworks like PyTorch/TF give us auto-differentiation on GPUs but bolt onto Python (which has no built-in support for logical reasoning or knowledge), while classic AI languages (Prolog, Lisp) handle symbols and logic but can’t scale or learn from data. Tensor Logic addresses this by making the tensor equation the one core construct, since Domingos observes that logical inference rules are mathematically like tensor index summation (Einstein summation). Everything else in AI can be reduced to that form. The paper demonstrates how key paradigms - from transformers and neural nets to formal logic proofs, kernel methods, and graphical models - can all be implemented elegantly in Tensor Logic’s unified framework. Crucially, this opens up new possibilities like “sound reasoning in embedding space” - combining neural scalability/learnability with the rigor of symbolic reasoning. Tensor Logic thus aims to be a foundation for AI going forward, offering the transparency of symbols with the power of tensors, potentially spurring broader adoption of AI by bridging the long-standing neuro-symbolic divide.
