
Less Thinking, More Doing: The Promises of Test-Time Interaction
Learn about Test-Time Interaction, Lingshu, and Highly Compressed Tokenizers
Welcome, Watcher! This week in LLM Watch:
From LLMs that only “think” to models that also “do”
Making sense of all medical data with a single model
Generative models that don’t need training
Courtesy of NotebookLM
1. Thinking vs. Doing: Agents that Reason by Scaling Test-Time Interaction
Watching: Test-Time Interaction (paper/code)
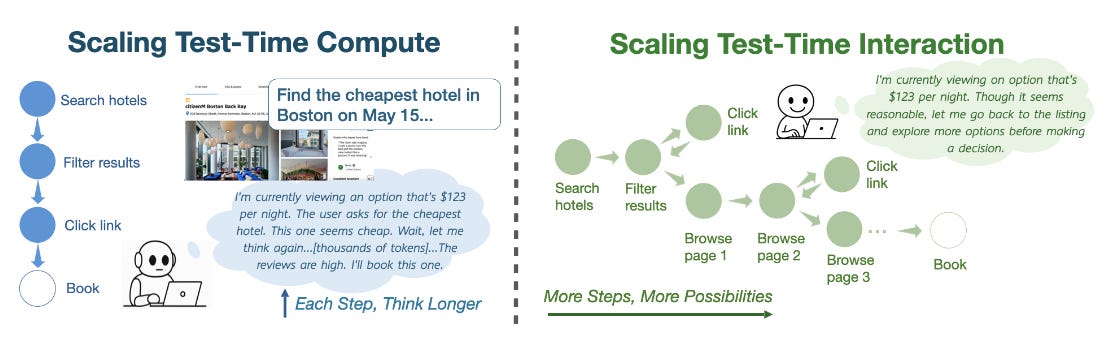
What problem does it solve? Current AI agents are stuck in a "think first, act later" paradigm. When these agents encounter a task, they spend a lot of computational resources generating long chains of reasoning before taking any action - essentially overthinking before doing anything. This is like trying to plan your entire route through a maze before taking a single step. The fundamental limitation is that this approach prevents agents from learning new information through interaction with their environment. In real-world scenarios where conditions change or information is incomplete (think booking a flight where prices fluctuate or browsing a website where not all content is immediately visible), these reactive agents struggle because they can't adapt their behavior based on what they discover along the way.
How does it solve the problem? The researchers propose "interaction scaling" - instead of “thinking” longer, agents should “act” more. For this purpose, they developed TTI (Test-Time Interaction), a training method that uses curriculum-based reinforcement learning. The curriculum is clever: it starts by training agents with short interaction sequences (like teaching a child simple tasks first) and gradually increases the allowed number of steps. This is implemented using a multiplicative schedule that expands the interaction horizon from 10 to 30 steps over training iterations. The agents learn through online filtered behavior cloning, where only successful task completions are used for training. They tested this approach on web navigation tasks using a Gemma 3 12B model, creating agents that can browse websites, fill forms, and search for information.
What are the key findings? They demonstrate that "doing more" beats "thinking more" when agents have a fixed computational budget. On WebArena benchmarks, simply prompting agents to "check again" after completing a task improved success rates from 23% to 28% - while forcing them to spend more time in the reasoning phase only yielded a 3% improvement. The full TTI system achieved state-of-the-art performance among open-source agents, with 64.8% success on WebVoyager and 26.1% on WebArena. Interestingly, TTI agents learned to adaptively balance exploration and exploitation - they'd efficiently complete simple tasks but engage in backtracking and broader searches for complex ones. The trained agents actually reduced their per-step reasoning (shorter chain-of-thought) while taking more interaction steps, automatically learning to trade thinking for doing.
Why does it matter? This fundamentally challenges how we approach AI agent development. Instead of building agents that are excellent armchair philosophers, we need agents that learn by doing - much like humans do. This is particularly important for real-world applications where environments are dynamic and information is incomplete. Their work shows that interaction itself is a form of compute that can be scaled, opening new avenues for agent training beyond just making models larger or their reasoning deeper. For practical applications like web automation, customer service, or robotic control, this means we can build agents that adapt in real-time rather than being stuck with pre-planned behaviors. The approach also demonstrates a form of self-improvement where agents learn from their own synthetic data, potentially reducing reliance on expensive human-annotated datasets.
2. Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Watching: Lingshu (paper/code)
What problem does it solve? While Large Language Models like GPT-4 have become remarkably capable at understanding everyday images and text, they struggle when it comes to medical applications. Think of it like asking a brilliant generalist to suddenly perform surgery - they might understand the concepts, but lack the specialized expertise. Current medical MLLMs face three major roadblocks: they mostly focus on medical images while ignoring the vast wealth of medical text knowledge, they're prone to "hallucinating" (making up plausible-sounding but incorrect medical information), and they lack the sophisticated reasoning abilities that doctors use when making complex diagnoses. This gap is particularly concerning given that medical AI needs to be both comprehensive and reliable.
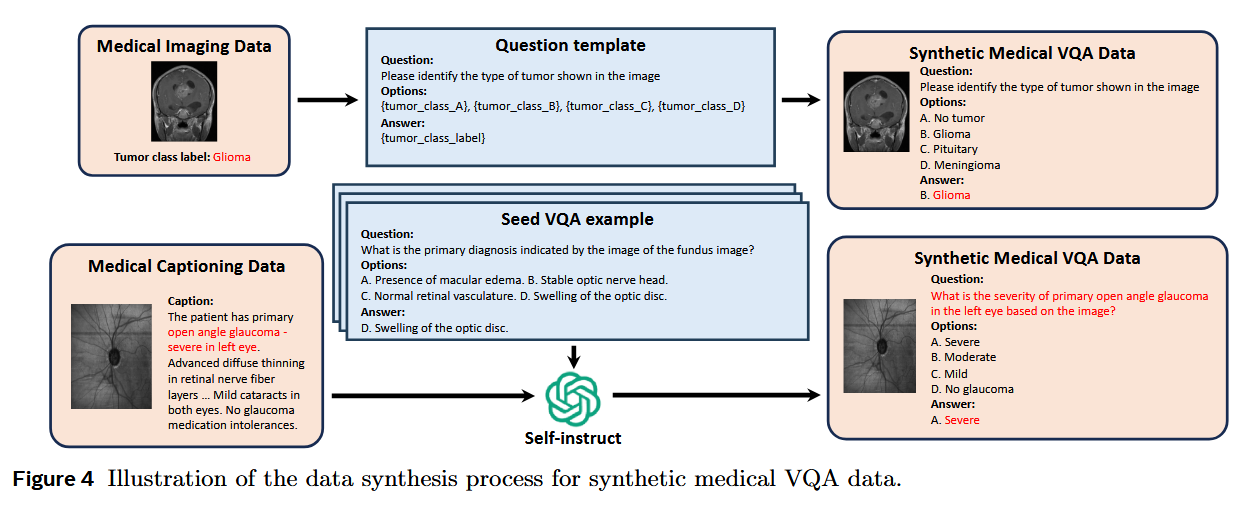
How does it solve the problem? The researchers developed Lingshu through a comprehensive data curation pipeline that goes beyond just collecting medical images. They gathered medical knowledge from multiple sources - imaging data, extensive medical texts, and even general-domain data - then synthesized high-quality training examples including detailed medical captions, visual question-answering pairs, and chain-of-thought reasoning samples. The model undergoes multi-stage training that progressively builds medical expertise, similar to how medical students progress from basic anatomy to complex clinical reasoning. They also explored using reinforcement learning with verifiable rewards (RLVR) to enhance the model's medical reasoning abilities. Additionally, they created MedEvalKit, a standardized evaluation framework that consolidates various medical benchmarks for fair comparison.
What are the key findings? Lingshu consistently outperforms existing open-source multimodal models across most medical tasks evaluated. The model demonstrates strong performance on three fundamental medical capabilities: multimodal question answering (understanding and answering questions about medical images), text-based medical QA, and medical report generation. For instance, Lingshu-32B achieves state-of-the-art performance with an average score of 66.6 across multimodal benchmarks, outperforming both proprietary and open-source competitors. The researchers also conducted five real-world case studies showing Lingshu's practical utility in scenarios like medical diagnosis, radiology report generation, and patient consultations.
Why does it matter? By addressing the limitations of existing medical MLLMs - particularly their narrow focus on images and susceptibility to errors - Lingshu provides a more holistic and reliable foundation for medical AI applications. The comprehensive evaluation framework (MedEvalKit) is equally important as it establishes standardized benchmarks for the field, enabling fair comparisons and driving future improvements. Most critically, the demonstrated real-world applications suggest that such models could meaningfully assist healthcare professionals in clinical practice, potentially improving diagnostic accuracy and patient care while reducing physician workload.
3. Highly Compressed Tokenizer Can Generate Without Training
Watching: Highly Compressed Tokenizers (paper/code)
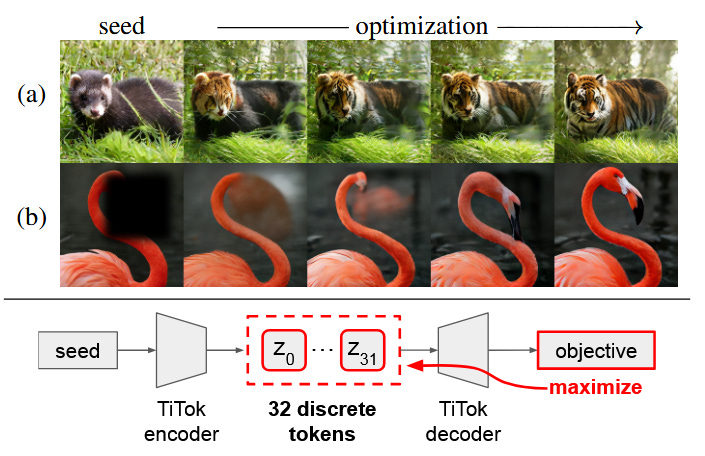
What problem does it solve? Modern image generation systems like DALL-E or Stable Diffusion typically require two major components: a tokenizer that compresses images into a compact representation, and a separate generative model (like a diffusion model) that learns to create new images in this compressed space. Training these generative models is computationally expensive and time-consuming. The authors investigate whether the tokenizer itself - specifically highly compressed 1D tokenizers that squeeze entire images into just 32 discrete tokens - might already possess generative capabilities without needing any additional model training. This is like asking whether a really good compression algorithm might inherently understand images well enough to create new ones.
How does it solve the problem? The researchers took a pretrained TiTok 1D tokenizer and explored its capabilities through increasingly sophisticated experiments. First, they discovered that specific token positions correspond to high-level image attributes (like lighting or blur), enabling simple "copy-paste" operations between images' token representations to transfer these attributes. Building on this insight, they developed a gradient-based optimization approach that directly manipulates tokens at test time using objectives like CLIP similarity (for text-guided editing) or reconstruction loss (for inpainting). This optimization doesn't require any training - it just iteratively adjusts the tokens to maximize the desired objective, similar to how you might adjust sliders in photo editing software until the image looks right.
What are the key findings? They demonstrate that highly compressed tokenizers can indeed function as generative models without additional training. The authors achieved an FID score of 8.2 on ImageNet generation (lower is better), competitive with methods that require extensive generative model training. They found that higher compression ratios paradoxically lead to better generative performance - tokenizers producing just 32 tokens outperformed those using 64 or 128 tokens. The system successfully performs text-guided image editing, inpainting, and even generates images from scratch using only test-time optimization. Remarkably, simple token manipulations like copying tokens between images can reliably transfer appearance attributes like lighting conditions or background blur.
Why does it matter? Their findings suggest that extreme compression forces tokenizers to learn such rich, semantic representations that they become implicit generative models - essentially learning not just how to compress images, but understanding what makes an image valid. This could dramatically reduce the computational resources needed for image generation, as it eliminates the need to train separate generative models. The work also provides insights into the nature of visual representation learning: when you compress an image into just 32 tokens, each token must capture global, meaningful information about the image, creating a latent space that's inherently suitable for generation and manipulation.

Papers of the Week:
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Truly Self-Improving Agents Require Intrinsic Metacognitive Learning
VerIF: Verification Engineering for Reinforcement Learning in Instruction Following
ReasonMed: A 370K Multi-Agent Generated Dataset for Advancing Medical Reasoning
Learning What Reinforcement Learning Can't: Interleaved Online Fine-Tuning for Hardest Questions