
🥇 GraphRAG's Biggest Problem Solved
And how to beat OpenAI's o1 on a budget

In this issue:
A new standard for GraphRAG
Replicating OpenAI’s strongest model
LLM-”brained” agents for your devices

1. LazyGraphRAG: Setting a new standard for quality and cost
Watching: LazyGraphRAG (blog)
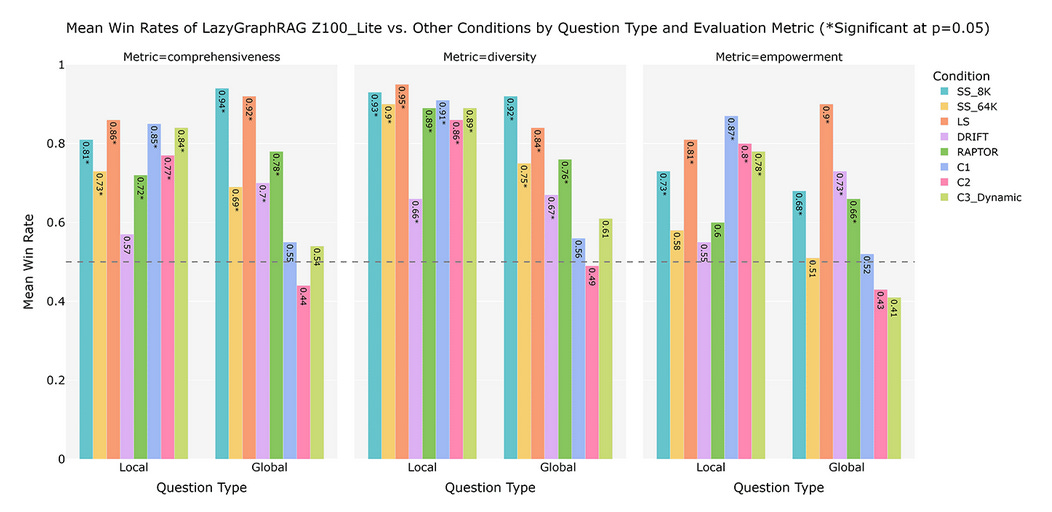
What problem does it solve? Retrieval Augmented Generation (RAG) has become a popular approach for knowledge-intensive tasks, such as open-domain question answering. However, standard RAG methods that rely on vector similarity search can struggle with global queries that require a broad understanding of the entire dataset. GraphRAG, which leverages the community structure of entities in the source text, addresses this limitation but comes with significant upfront indexing costs. LazyGraphRAG aims to provide a scalable solution that balances the strengths of both vector RAG and GraphRAG while minimizing their drawbacks.
How does it solve the problem? LazyGraphRAG combines best-first and breadth-first search strategies in an iterative deepening manner. It starts with a vector similarity search to identify the most relevant text chunks for the query, similar to vector RAG. However, instead of immediately generating an answer, it performs a relevance test using an LLM to determine if the retrieved information is sufficient. If not, it expands the search to include neighboring communities in the graph structure, gradually increasing the breadth of the dataset considered. This lazy approach defers LLM use and dramatically improves the efficiency of answer generation compared to full GraphRAG.
What's next? The LazyGraphRAG approach will soon be available in the open-source GraphRAG library, providing users with a unified query interface for both local and global queries over a lightweight data index. As the method demonstrates strong performance across the cost-quality spectrum, it has the potential to become a go-to solution for a wide range of knowledge-intensive tasks.
2. O1 Replication Journey -- Part 2: Surpassing O1-preview through Simple Distillation, Big Progress or Bitter Lesson?
Watching: O1-Replication (paper/code)

What problem does it solve? The paper addresses the lack of transparency and reproducibility in current attempts to replicate OpenAI's O1 model capabilities. Many researchers are using knowledge distillation techniques to achieve similar performance, but often without disclosing the details of their methods. This lack of transparency makes it difficult to assess the true technical complexity and generalizability of these replicated models.
How does it solve the problem? They demonstrate that a simple approach of distilling knowledge from O1's API, combined with supervised fine-tuning, can achieve superior performance on complex mathematical reasoning tasks like the American Invitational Mathematics Examination (AIME). They show that a base model fine-tuned on just tens of thousands of O1-distilled long-thought chains can outperform O1-preview on AIME with minimal technical complexity. Furthermore, they explore the generalization capabilities of these O1-distilled models across diverse tasks such as hallucination, safety, and open-domain question answering.
What's next? The paper serves as a call for increased transparency and reproducibility in AI research, particularly in the context of replicating advanced models like O1. The authors emphasize the importance of developing researchers who are grounded in first-principles thinking, rather than solely focusing on achieving more capable AI systems through opaque methods. They provide a comprehensive benchmark framework for evaluating and categorizing O1 replication attempts based on their technical transparency and reproducibility, which can serve as a guide for future research in this area. However, the authors also caution against over-relying on distillation approaches and highlight the potential risks and limitations of such methods.
3. Large Language Model-Brained GUI Agents: A Survey
Watching: LLM GUI Agents (paper)

What problem does it solve? Graphical User Interfaces (GUIs) have been the primary means of human-computer interaction for decades. However, the increasing complexity of software applications and the need for more intuitive and efficient user experiences have posed challenges. LLM-brained GUI agents aim to address these challenges by leveraging the power of Large Language Models (LLMs) to enable natural language-based interaction with GUIs. These agents can interpret user instructions, navigate complex interfaces, and execute tasks autonomously, simplifying the user experience and enhancing productivity.
How does it solve the problem? LLM-brained GUI agents combine the strengths of LLMs, particularly their natural language understanding and code generation capabilities, with visual processing techniques to interact with GUIs effectively. These agents can parse and understand the structure and semantics of GUI elements, such as buttons, menus, and input fields. By leveraging the knowledge and reasoning abilities of LLMs, they can interpret user instructions expressed in natural language and map them to the appropriate GUI actions. This enables users to perform complex tasks through simple conversational commands, eliminating the need for manual navigation and interaction with the interface.
What's next? Future advancements may focus on improving the robustness and generalization capabilities of these agents across diverse GUI environments. This could involve the collection and utilization of large-scale GUI interaction datasets, the development of specialized action models tailored for GUI tasks, and the establishment of standardized evaluation metrics and benchmarks. Additionally, the integration of LLM-brained GUI agents into various domains, such as web browsing, mobile app automation, and enterprise software, holds immense potential for transforming user experiences and enhancing productivity. We can expect to see more widespread adoption and innovative applications of these agents in both personal and professional settings.
Papers of the Week:
Associative Knowledge Graphs for Efficient Sequence Storage and Retrieval
XGrammar: Flexible and Efficient Structured Generation Engine for Large Language Models
RE-Bench: Evaluating frontier AI R&D capabilities of language model agents against human experts
Adapter-based Approaches to Knowledge-enhanced Language Models -- A Survey
From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge
Best of Both Worlds: Advantages of Hybrid Graph Sequence Models
ShowUI: One Vision-Language-Action Model for GUI Visual Agent