
🗃️ GraphRAG Evolves into StructRAG
And the potential future of agent "thinking"

In this issue:
GraphRAG → StructRAG
Agent thinking, fast and slow
A universal knowledge graph foundation model
MLOps/GenAI World is all about solving real-world problems and sharing genuine experiences with production-grade AI systems.
Join leaders and engineers from Microsoft, Huggingface, BlackRock and many more for the following tracks:
Real World Case Studies
Business & Strategy
Technical & Research (levels 1-7)
Workshops (levels 1-7)
In-person coding sessions
Get Access to 30+ virtual workshops, 60+ in-person talks and 90+ hours of recordings by claiming your personal discount.
1. StructRAG: Boosting Knowledge Intensive Reasoning of LLMs via Inference-time Hybrid Information Structurization
Watching: StructRAG (paper)

What problem does it solve? Retrieval-augmented generation (RAG) methods have shown promise in enhancing large language models (LLMs) for knowledge-based tasks. However, when it comes to knowledge-intensive reasoning tasks, existing RAG methods often struggle. The main challenge lies in the scattered nature of the useful information required for these tasks, making it difficult for RAG methods to accurately identify key information and perform global reasoning with noisy augmentation.
How does it solve the problem? Inspired by cognitive theories suggesting that humans convert raw information into structured knowledge when tackling knowledge-intensive reasoning, StructRAG proposes a novel approach. It introduces a framework that can identify the optimal structure type for a given task, reconstruct original documents into this structured format, and infer answers based on the resulting structure. By converting the scattered information into a structured representation, StructRAG enables more effective identification of key information and facilitates global reasoning, even in the presence of noisy augmentation.
What's next? The extensive experiments conducted across various knowledge-intensive tasks demonstrate the state-of-the-art performance achieved by StructRAG, particularly in challenging scenarios. This showcases its potential as an effective solution for enhancing LLMs in complex real-world applications. Moving forward, further research could explore the applicability of StructRAG to an even wid
er range of knowledge-intensive tasks and investigate its scalability to larger datasets and more diverse domains.
For a detailed introduction, check out my latest research summary.
2. Agents Thinking Fast and Slow: A Talker-Reasoner Architecture
Watching: Talker-Reasoner Architecture (paper)
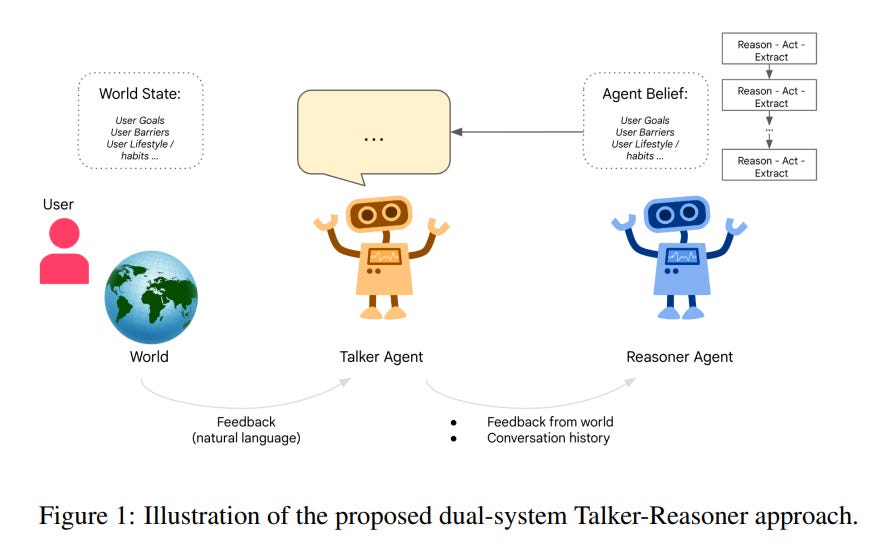
What problem does it solve? As Large Language Models (LLMs) are becoming more capable of engaging in natural conversations, there is a growing need for these models to not only converse but also reason and plan effectively. Balancing the demands of generating coherent, context-aware responses while simultaneously performing multi-step reasoning and goal-oriented planning can be challenging for a single model. The proposed Talker-Reasoner architecture aims to address this issue by separating the conversational and reasoning components, allowing each to focus on its specific task.
How does it solve the problem? The Talker-Reasoner architecture introduces two distinct agents: the "Talker" and the "Reasoner." The Talker agent, analogous to Kahneman's System 1, is designed to be fast and intuitive, focusing on generating conversational responses that are informed by all available information. On the other hand, the Reasoner agent, similar to System 2, is slower and more deliberative, tasked with performing multi-step reasoning, planning, and executing actions in the world. By separating these responsibilities, the architecture allows for a more modular and efficient approach to handling the dual nature of conversational agents.
What's next? The Talker-Reasoner architecture offers several advantages, including improved modularity and reduced latency. By separating the conversational and reasoning components, developers can fine-tune and optimize each agent independently, leading to more efficient and effective conversational AI systems. As research in this area progresses, we can expect to see further refinements and adaptations of this architecture to suit the needs of different conversational AI applications.
3. A Prompt-Based Knowledge Graph Foundation Model for Universal In-Context Reasoning
Watching: KG Foundation Models (paper/code)

What problem does it solve? Knowledge Graphs (KGs) are a powerful tool for representing and reasoning over large amounts of structured data. However, existing approaches to KG reasoning often struggle to generalize across different KGs and reasoning settings. This lack of transferability means that separate models must be developed for each KG, which is inefficient and limits the potential impact of KG-based systems.
How does it solve the problem? KG-ICL introduces a novel prompt-based approach to KG reasoning that enables generalization and knowledge transfer across diverse KGs. The key idea is to use a prompt graph centered around a query-related example fact as context to understand the query relation. To encode these prompt graphs in a way that allows generalization to unseen entities and relations, KG-ICL employs a unified tokenizer and two specialized message passing neural networks. This architecture enables the model to perform both prompt encoding and KG reasoning in a flexible and transferable manner.
What's next? The strong performance of KG-ICL across a wide range of KGs and reasoning settings highlights the potential of prompt-based approaches for achieving universal KG reasoning capabilities. Future work could explore the integration of KG-ICL with other knowledge-driven tasks, such as question answering or natural language understanding. Additionally, the development of more sophisticated prompt graph construction techniques and the incorporation of additional context information could further enhance the model's reasoning abilities.
Papers of the Week:
Towards Trustworthy Knowledge Graph Reasoning: An Uncertainty Aware Perspective
SuperCorrect: Supervising and Correcting Language Models with Error-Driven Insights
Divide-Verify-Refine: Aligning LLM Responses with Complex Instructions
Proactive Agent: Shifting LLM Agents from Reactive Responses to Active Assistance