
🔋 Fixing AI's Energy Consumption
And how to speed up RNNs by up to 175x

In this issue:
Reducing energy consumption by up to 95%
Google’s way forward for RAG
RNNs might’ve been all we needed
MLOps/GenAI World is all about solving real-world problems and sharing genuine experiences with production-grade AI systems.
Join leaders and engineers from Microsoft, Huggingface, BlackRock and many more for the following tracks:
Real World Case Studies
Business & Strategy
Technical & Research (levels 1-7)
Workshops (levels 1-7)
In-person coding sessions
Get Access to 30+ virtual workshops, 60+ in-person talks and 90+ hours of recordings by claiming your personal discount.
1. Addition is All You Need for Energy-efficient Language Models
Watching: L-Mul (paper)
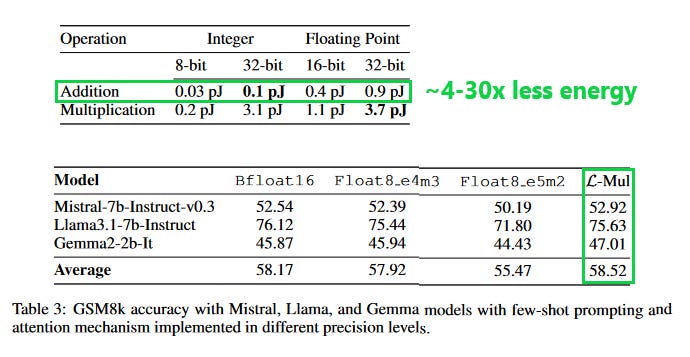
What problem does it solve? Floating point operations, particularly multiplications, are one of the most compute-intensive parts of neural networks. This is especially true for Large Language Models (LLMs) that often have hundreds of billions of parameters. Quantization techniques, such as using lower precision floating point numbers (e.g., float8 instead of float32), have been proposed to reduce the computational cost. However, these techniques still require expensive floating point multiplications.
How does it solve the problem? The L-Mul algorithm approximates floating point multiplications with integer additions, which are significantly less computationally expensive. The key idea is to represent floating point numbers in a way that allows for multiplication to be approximated by addition. L-Mul achieves this by using a linear approximation of the multiplication operation. The algorithm can be tuned by adjusting the number of bits used for the mantissa, with more bits leading to higher precision but also higher computational cost. Notably, L-Mul with a 4-bit mantissa achieves comparable precision to float8_e4m3 multiplications, while L-Mul with a 3-bit mantissa outperforms float8_e5m2.
What's next? The potential energy savings from using L-Mul in tensor processing hardware are significant - up to 95% for element-wise multiplications and 80% for dot products. The next step would be to implement L-Mul in popular deep learning frameworks and hardware accelerators. It would also be interesting to see how L-Mul performs on even larger models and more diverse tasks. However, it's important to note that while L-Mul shows promise, it's still an approximation, and there may be some tasks or models where the loss in precision is not acceptable.
2. Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models
Watching: Astute RAG (paper)
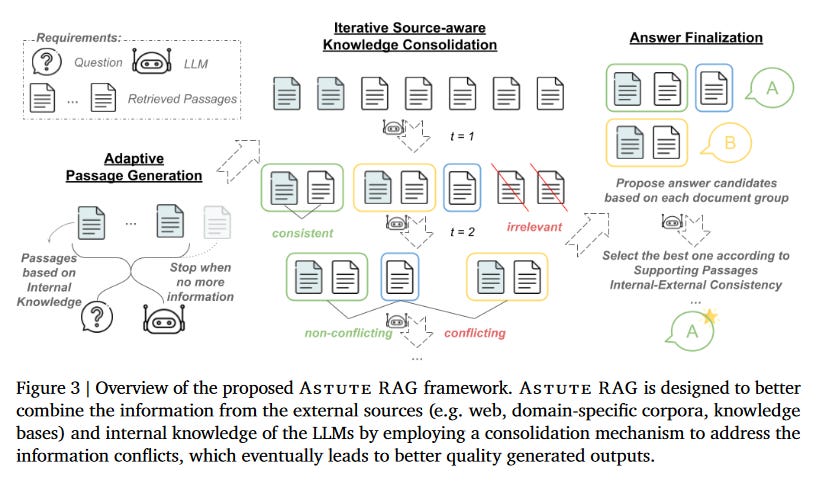
What problem does it solve? Retrieval-Augmented Generation (RAG) has been a promising approach to enhance Large Language Models (LLMs) by integrating external knowledge. However, the retrieval process can be imperfect, leading to the inclusion of irrelevant, misleading, or even malicious information. This can result in knowledge conflicts between the LLM's internal knowledge and the external sources, undermining the effectiveness of RAG.
How does it solve the problem? Astute RAG is a novel approach that addresses the challenges of imperfect retrieval in RAG systems. It adaptively elicits essential information from the LLM's internal knowledge and iteratively consolidates it with the external knowledge from retrieval, while maintaining source-awareness. The final answer is determined based on the reliability of the information. This process effectively resolves knowledge conflicts and improves the overall reliability and trustworthiness of the RAG system.
What's next? Further research could explore the integration of more advanced retrieval techniques to minimize the occurrence of imperfect retrieval. Additionally, the development of more sophisticated methods for assessing information reliability and resolving knowledge conflicts could further improve the performance of Astute RAG. It will be crucial to address the challenges posed by imperfect retrieval to ensure the trustworthiness and effectiveness of these systems in real-world applications.
3. Were RNNs All We Needed?
Watching: Minimal RNNs (paper)

What problem does it solve? Transformers have been the go-to architecture for sequence modeling tasks in recent years, but their scalability limitations regarding sequence length have become increasingly apparent. This has led to a renewed interest in recurrent sequence models that can be parallelized during training, such as S4, Mamba, and Aaren. However, these novel architectures can be complex and computationally expensive.
How does it solve the problem? The authors revisit traditional recurrent neural networks (RNNs) from over a decade ago, namely LSTMs (1997) and GRUs (2014), and propose a simple modification to make them fully parallelizable during training. By removing the hidden state dependencies from the input, forget, and update gates of LSTMs and GRUs, the need for backpropagation through time (BPTT) is eliminated. This allows for efficient parallel training, resulting in a 175x speedup for sequences of length 512. Additionally, the authors introduce minimal versions (minLSTMs and minGRUs) that use significantly fewer parameters than their traditional counterparts.
What's next? The findings of this research suggest that the performance of recent sequence models can be matched by stripped-down versions of decade-old RNNs. This opens up new possibilities for efficient and scalable sequence modeling using traditional architectures. Future work could explore the application of these parallelizable LSTMs and GRUs to various domains, such as natural language processing, speech recognition, and time series forecasting. Additionally, the ideas presented in this paper could inspire further research into simplifying and optimizing other existing neural network architectures for improved efficiency and scalability.
Papers of the Week:
Scalable and Accurate Graph Reasoning with LLM-based Multi-Agents
Stuffed Mamba: State Collapse and State Capacity of RNN-Based Long-Context Modeling
MLLM as Retriever: Interactively Learning Multimodal Retrieval for Embodied Agents
Let's Ask GNN: Empowering Large Language Model for Graph In-Context Learning
Retrieval-Augmented Decision Transformer: External Memory for In-context RL