
Falcon-H1: The AI Chimera That Challenges The Transformer
How a new AI model beats models twice its size

Sometimes in AI, smaller can be smarter. A recent research release shows a 34-billion-parameter AI model matching the performance of models twice its size by doing something unconventional – giving the AI two different neural networks instead of one. This isn’t just a one-off trick: it hints at how the next generation of foundation models might be built, blending techniques and potentially modalities to achieve more with less. In this post, we break down this hybrid AI breakthrough and explore what it means for tech builders, researchers, and strategists alike.
Meet Falcon-H1 – The Hybrid AI That Punches Above Its Weight
A few months ago, the team at Technology Innovation Institute (TII) unveiled Falcon-H1, a series of large language models with a new hybrid architecture (and now, we finally got the report). Instead of relying purely on the standard Transformer architecture that underpins most modern generative AIs, Falcon-H1 combines two different model paradigms in parallel within each layer. In simple terms, it’s like giving the model “two heads” for thinking: one head uses the classic attention mechanism (great for focusing on specific details in text), and the other uses a State Space Model (SSM) (great for remembering long sequences efficiently). These twin heads work side by side, and their outputs are fused together, allowing Falcon-H1 to leverage the strengths of both approaches.
Why go hybrid? The Transformer (attention) is excellent at understanding contextual relationships (think of it as a spotlight that highlights relevant words), while the SSM provides superior long-term memory and speed (think of it as an efficient notepad that can handle very long documents without slowing down). By marrying the two, Falcon-H1 aims to get the best of both worlds – and according to the results, it succeeds. The hybrid architecture yields faster inference and lower memory usage than a pure Transformer, without sacrificing accuracy. In fact, the researchers found that they only needed a relatively small fraction of attention heads (the Transformer part) to achieve strong performance – the SSM component carries a lot of the load for long-text understanding. This is a significant departure from the “all-Transformer, all the time” approach of most large models.
So, what is Falcon-H1 exactly? It’s a family of six open-source models of varying sizes (from a tiny 0.5 billion parameters up to 34 billion) released with a permissive license (Apache 2.0). Each model comes in both a base version and an instruction-tuned version (trained to follow human instructions better). Despite the relatively moderate sizes (by today’s standards), Falcon-H1 models are punching above their weight class. Here are some of the highlights and features of Falcon-H1:
Hybrid Architecture (Attention + SSM): Each model layer uses two parallel heads – one Transformer attention head and one “Mamba-2” SSM head – whose outputs are concatenated. The ratio of attention to SSM can be tuned, but it turns out you don’t need much attention to get great results. This design provides strong generalization across tasks with faster speed and better memory efficiency than attention alone. (Think of it like a car with both an electric motor and a gas engine – efficient for long hauls yet quick for bursts of power.)
Wide Range of Model Sizes: Falcon-H1 is released in six sizes – 0.5B, 1.5B, 1.5B-Deep, 3B, 7B, and 34B parameters – covering everything from lightweight models that could run on edge devices to hefty models for servers. The “1.5B-Deep” variant is intriguing: it has the same parameter count as the 1.5B model but far more layers (66 layers vs 24), illustrating one of the team’s findings that deeper models can outperform wider ones under the same budget.
Multilingual by Design: These models aren’t just English-centric. Falcon-H1 was trained natively on 18 languages (covering English, Chinese, Arabic, Hindi, Spanish, French, and many more) and the underlying tokenizer can scale to 100+ languages. In practice, this means the models can understand and generate multiple languages out-of-the-box, a nod to our globally connected world where AI needs to speak many tongues.
Compact Models, Big Performance: Perhaps the most impressive claim: Falcon-H1 models are designed to match or exceed the performance of models at least twice their size. The tiny 0.5B model (the size of a single GPT-2, roughly) delivers performance on par with typical 7B parameter models from just a year prior. The 1.5B-Deep model actually outperforms many 7B models out there. And the flagship 34B model has been shown to match or beat certain 70B models (like Meta’s and Alibaba’s latest) on a range of benchmarks. In short, Falcon-H1 squeezes more juice out of every parameter – a welcome development as we confront the cost and complexity of ever-larger AI models.
256K Context Length: Falcon-H1 can handle really long inputs. Thanks to the SSM-based design and some clever tweaking of positional embeddings, it supports up to 256,000 tokens of context (for the 7B and 34B models). That’s orders of magnitude more than the 4K or 8K token limits many GPT-style models had not long ago. For perspective, 256k tokens is roughly a hundreds of pages of text in one go. This opens the door to AI that can ingest and reason about long documents (or lengthy multi-turn conversations) without breaking a sweat.
Domain Expertise (STEM and Code): Because of a carefully curated training set, Falcon-H1 shows strong abilities in math, science, and coding tasks. The team deliberately included high-quality technical content – like math problem sets, scientific papers, and a large code corpus – in the training mix. They even tweaked the tokenizer to handle things like LaTeX math notation and code syntax better (e.g., splitting digits and punctuation so the model learns numbers and code structure more effectively). As a result, the models have exceptional STEM capabilities compared to peers, excelling at mathematical reasoning and scientific Q&A.
Open-Source and Accessible: All Falcon-H1 models are released under a permissive open-source license and are available on Hugging Face for anyone to use. Crucially, the team also provides quantized versions of the instruction-tuned models (over 30 checkpoints in total), meaning you can run these models with much less memory than the full parameter count would normally require. In practice, this could allow a 34B model to run on a single high-end GPU or even a powerful laptop – bringing near state-of-the-art AI capabilities to those without mega-scale infrastructure.
In summary, Falcon-H1 arrives not as a single monolithic model but as a portfolio of AI models that are smaller, multilingual, long-winded (in a good way), and freely available. It’s a bold demonstration that innovation in architecture and training can rival sheer scale. But how did the researchers actually pull this off? Let’s peek under the hood.
How Did They Do It? Rethinking the Recipe for AI Success
It’s one thing to list features and accomplishments, but Falcon-H1’s creation is as interesting as its results. The researchers didn’t just scale up a Transformer in the usual way – they questioned a lot of AI’s conventional wisdom and tried some decidedly off-beat ideas in the process. Here are a few of the key methods and insights behind the scenes:
Hybrid “Mixer” Layers: As mentioned, the core innovation was the parallel hybrid layer design. Instead of stacking some SSM layers and some attention layers separately, Falcon-H1’s layers each contain both components running concurrently
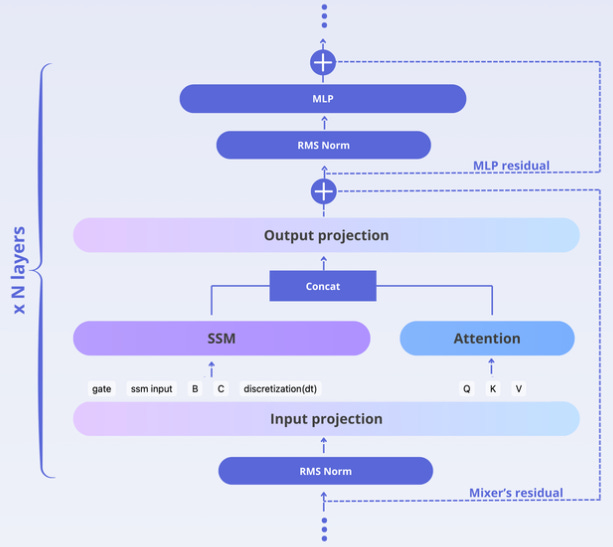
The diagram above (from the Falcon team) illustrates this: an input goes through a normalization, then splits into an SSM branch (purple) and an Attention branch (blue). Both process the data at the same time, then their outputs are concatenated and passed through an MLP (feed-forward network) together before the layer outputs its result. This parallel approach, as opposed to a sequential mix, was found to work best. Crucially, it lets the designers tune the ratio of how many channels go to SSM vs Attention vs MLP. After extensive experiments, they settled on a ratio (for example, in one configuration, roughly 2 parts SSM, 1 part attention, 5 parts MLP) that optimized efficiency and learning dynamics. Interestingly, adding too much attention actually hurt performance, whereas giving the SSM a healthy share improved it. In other words, more Transformer wasn’t always better – a smaller attention mechanism paired with SSM was the sweet spot.
Positional Encoding Trick for Long Contexts: One challenge with super-long context windows (like 256k tokens) is how to give the model a sense of position (which word comes first, second, etc.) without losing precision. Falcon-H1 tackled this by using an unusually high-frequency rotary positional embedding (RoPE) base. Essentially, they cranked up a parameter in the positional encoding formula to $10^{11}$ (far beyond typical values), which significantly improved the model’s ability to generalize on long sequences. Normally, using such a high frequency would destabilize a pure Transformer, but the hypothesis is that the SSM part naturally handles some positional information, allowing the attention part to take on this extreme frequency without trouble. It’s a bit like giving the model an extremely fine-grained ruler to measure position in text – and finding that it actually can make use of all those tick marks when reading a long document.
Deeper, Not Just Wider: When allocating a fixed budget of parameters, the team found that making the model deeper (more layers) often yielded better results than making it wider (bigger layer dimensions). This insight led to the creation of the Falcon-H1-1.5B-Deep variant – it packs 66 layers into 1.5B params, compared to the standard 24 layers – and that deep model outperformed many models with 3B or even 7B parameters. It’s a notable data point in the ongoing “depth vs width” debate in model design, suggesting that for some tasks a tall, thin model can beat a short, fat one (up to a point).
Unorthodox Training Curriculum: In training AI, a common practice is curriculum learning – feed the model easy examples first and gradually move to harder ones. Falcon-H1’s team tried the opposite and it worked better. They gave even the most complex data (like tough math problems and very long texts) right from the start of training, rather than saving them for last. Counterintuitively, this early exposure to hard examples gave the model “more time to learn” the skills needed for those challenges. It’s akin to teaching a language by mixing in advanced literature from day one alongside the basics – a risky approach for humans, but apparently effective for this AI’s development.
More Data, More Reuse: Falcon-H1 was trained on a colossal 20 trillion token corpus (with about 18T actually used). This includes a refined web crawl (“FineWeb”), a large multilingual set (Wikipedia, Common Crawl, subtitles, etc. for 17 languages), a 67-language code dataset (deduplicated and cleaned), and specialized math and science data. One concern with such large datasets is models simply memorizing content. The prevailing wisdom is usually to avoid reusing data in training passes. However, the team found that this risk is a bit overestimated – they carefully measured the model’s “memorization window” and concluded they could reuse high-quality examples more times than usual without hurting generalization. By doing so, they ensured that the best content (like high-quality science articles or code) had a stronger influence on training, rather than being diluted by a flood of lower-quality web text. This approach improved the model’s grasp of those domains without turning it into a rote copy-machine.
Stabilizing the Training of SSMs: State-space models are powerful for long sequences, but they can be tricky – prone to training instabilities (loss spikes). The Falcon team addressed this by inserting special “dampening” factors into the SSM components as part of their parametrization (essentially, controlling the scale at which the SSM part learns). By doing so, they eliminated the nasty training spikes that often plague SSM-based networks, resulting in a smooth learning curve. They also paid close attention to things like parameter norm growth and noise in gradients, tweaking hyperparameters (like using scheduled weight decay) to keep the training process stable. The takeaway for researchers: making novel architectures work often requires this kind of diligent debugging and fine-tuning of the training process.
Efficient Scaling with μP (Mu Parametrization): Training six different model sizes could have been six times the work, but Falcon-H1 applied an advanced technique called Maximal Update Parametrization (μP) to streamline this. μP provides a theory-backed way to set hyperparameters (like learning rate) for one model size and then scale them to larger models reliably. Using μP, the team found optimal settings on a base model and transferred them to all other sizes, allowing them to train multiple models in parallel without lots of per-model tuning. They even went a step further by customizing the μP scaling: instead of assuming the base model’s hyperparameters were perfectly tuned, they optimized 35 separate μP scaling factors for different parts of the network. This fine-grained approach squeezed extra performance out of each model. For the layperson, the result is that Falcon-H1 models were trained efficiently and in concert, making this massive undertaking a bit more manageable.
All these choices – from architectural design to training strategy – contributed to Falcon-H1’s success. The researchers effectively broke some rules and set new ones. It’s a reminder that in the race for bigger and better AI, raw scale isn’t the only path; sometimes clever engineering and fresh ideas can unlock performance that brute force alone would miss.
Results: When Smaller Models Beat Giants
So, did the hybrid approach pay off? The proof is in the pudding (or rather, in a slew of benchmarks). The Falcon-H1 models have demonstrated state-of-the-art or near-SOTA performance across a variety of tasks, often rivaling models far larger:
The flagship Falcon-H1-34B model is reported to match or outperform systems in the 70B parameter range. In evaluations, it stood toe-to-toe with models like Qwen-72B (Alibaba’s model) and a prototype LLaMA-70B on many benchmarks. This is astonishing when you consider it has half (or even half to one-third) the parameters – a testament to parameter efficiency. On standard NLP benchmarks (like MMLU for knowledge, HellaSwag for common-sense reasoning, GSM8k for math, etc.), Falcon-34B’s numbers are right up there with the best, and sometimes winning【25†image】. It’s not uniformly dominant, but the fact that it’s in the same league as models twice its size is a huge win for the approach.
The Falcon-H1-1.5B-Deep model (just 1.5B params) deserves a shout-out. It clearly outperforms other ~2B models (like Qwen3-1.7B) and even holds its own against many 7B models. Essentially, a well-designed 1.5B hybrid model from 2025 can do what a vanilla 7B model from 2024 could do. That’s a big deal for those who need smaller models – it means you might not need a massive cluster to get strong AI performance for many tasks. Falcon-1.5B-Deep even beat some 7B versions of Falcon’s own previous generation (Falcon-40B from 2023 had a 7B little sibling) and competitive models, which validates the “deeper not wider” strategy in practice.
On multilingual benchmarks, Falcon-34B shows very strong performance across languages like Arabic, Spanish, Hindi, etc., often on par with the best models evaluated for those languages. This confirms that the model’s multilingual training wasn’t just token window dressing; it genuinely learned multiple languages well. For businesses in non-English markets or operating globally, this is a welcome capability – an AI that doesn’t treat English as the default brain.
In terms of reasoning and specialized tasks, Falcon-H1 models excel in categories like math and coding. The inclusion of math and code data gave them a leg up on benchmarks like GSM8k (math word problems) and HumanEval (coding tasks). For instance, Falcon-34B performs strongly on GSM8k and is competitive on coding challenges, approaching the scores of much larger models. The team even noted that they did no special fine-tuning for reasoning, yet the instruction-tuned models show robust reasoning abilities out-of-the-box. This is a promising sign that massive fine-tune rounds (like those done for GPT-4’s “Chain-of-Thought” reasoning) might be sidestepped with a good pretraining mix.
On long-context tasks, Falcon-H1 really shines. They tested the 34B model on retrieval and long-document QA tasks where it had to read very lengthy texts (tens of thousands of tokens) and answer questions. Its performance was strong and in some cases it could handle things that a typical model (with a 4K or 8K limit) simply couldn’t attempt. This hints at new applications: think AI assistants that can digest entire books or analyze years of financial reports in one go. One can imagine loading up a 200-page contract and asking the model detailed questions – Falcon-H1’s long attention span is built for that.
To sum up the results: Falcon-H1 proves that smart design can yield outsized results. A smaller open-source model, built on novel ideas, is reaching parity with the closed giants of the field. It’s not every day that David goes up against Goliath in AI and comes out looking this good. And importantly, anyone can use David – the models are downloadable, finetunable, and deployable by anyone with the hardware and savvy to do so.
Why This Matters: A Glimpse of AI’s Future (Hybrid and Multimodal?)
Beyond the cool factor of Falcon-H1’s achievements, there’s a broader significance here. This research is a signpost for several big trends in AI:
1. Rethinking “Bigger is Better”: For the last few years, the story of AI has been “scale, scale, scale.” More parameters, more data, more compute – and you’ll get better results. That’s largely held true (GPT-4 wouldn’t be GPT-4 without an astronomical scale-up). But Falcon-H1 shows another path: architectural innovation and training strategy can give you leaps in performance without merely doubling size. It’s a reminder that we may be entering an era of diminishing returns on brute-force scaling, and the next breakthroughs could come from making models smarter, not just larger. For AI researchers, this is an exciting validation of pursuing new model forms (like combining attention with SSMs, or other hybrids) – there’s room to beat the scaling curve by being clever.
2. The Rise of Modular & Multimodal Foundation Models: Falcon-H1’s hybrid approach hints at a future where AI systems aren’t monolithic slabs of one architecture, but a combination of specialized components working together. Today it’s attention + SSM. Tomorrow it could be attention + SSM + convolution, or text + vision + memory modules, etc. In other words, multimodal foundation models might internally look like a collection of expert modules – an image understanding module, a text reasoning module, maybe a database retrieval module – all integrated in a single system. We’re already seeing early signs: OpenAI’s GPT-4 is multimodal (it can see images as well as read text), and it likely achieves this by combining a vision encoder with a language model. Google’s research has been exploring “universal models” that handle text, images, and more in one network. The success of Falcon-H1’s dual-technique model is a vote of confidence for this direction. It shows that heterogeneous architectures can work at scale. For tech strategists, this implies that the AI solutions of the near future might be more flexible and tailored – not every company will need a 100B-parameter pure Transformer if a 10B hybrid with the right components does the job better.
3. Democratization of AI Capability: The open-source nature of projects like Falcon-H1 means cutting-edge AI is not confined to a few big tech companies. We’re witnessing a fast-follower effect where open models replicate or even innovate beyond the proprietary ones, often within months. This shrinks the advantage gap. For product builders and startups, it’s great news: you can pick up a state-of-the-art foundation model (with support for your language, your long documents, etc.) for free and fine-tune it to your needs. Running a 34B model that competes with a 70B might be feasible on off-the-shelf hardware, especially with quantization and optimizations. That lowers the barrier to entry for AI-powered products. It also means more room for customization – you’re not stuck with a one-size-fits-all API from a large provider; you can have a model in-house that you understand and control. For enterprise strategists, the question shifts from “Where do we buy our AI capabilities?” to “How can we leverage these open foundation models to build unique value?”. The playing field is leveling, and the competitive edge will go to those who can best adapt and integrate these rapidly improving open models.
4. New Applications Unlocked: The technical improvements aren’t just academic; they translate to new use cases. 256K context means AI that can digest entire knowledge bases or code repositories at once – imagine assistants that truly “know” your company’s documentation or an AI that can refactor a whole codebase in one shot. Multilingual fluency means one model can serve users across markets, or analyze text in multiple languages without separate systems. Better math and reasoning means more reliable analytical assistants (maybe it won’t replace your junior analyst, but it can double-check their work). These capabilities get product people thinking: what can we build now that was impractical before? Perhaps AI tutors that read and critique textbooks, legal AI that cross-references entire law libraries, or business intelligence bots that comb through years of reports and data dumps to answer high-level questions. We’re inching closer to AI that isn’t just a clever chatbot, but a genuine research assistant that can handle breadth and depth of information.
To bring it down to specifics, let’s consider a few perspectives:
For Product Builders: Falcon-H1 and models like it mean you can deliver advanced AI features without needing a supercomputer or a mega-cloud budget. Want a customer support AI that handles long, complex threads of emails? A 7B or 34B Falcon can do that with its long context window. Need a coding helper that fits in your IDE? A 1.5B-Deep model might give surprisingly good code suggestions without calling an API. And because it’s open source, you can fine-tune it on your proprietary data (say, your company’s internal docs or codebase) with no external data leakage. The efficiency gain – doing more with smaller models – also hints at on-device AI for specialized apps. We could soon see smartphones or AR glasses running powerful language models locally, tailored to the user’s own data, thanks to these optimizations.
For AI Researchers: Falcon-H1 is a case study in breaking the mold. It encourages researchers to explore hybrid architectures and not assume Transformers are the end-all be-all. The success with SSMs may reinvigorate research into other sequence models or into better ways of integrating modules (maybe techniques from control theory or neuroscience-inspired models could be the next plug-in component). Also, the team’s willingness to challenge training orthodoxies (like reverse curriculum and data reuse) is a reminder that empirical results can defy expectations – we should keep testing those assumptions, especially as we venture into regimes (like 10+ trillion token training) where our old intuitions might not hold. In short, the field may become less uniform; expect a Cambrian explosion of model variants, each with different mixtures of components aimed at different niches (language, vision, speech, etc.), all coexisting and advancing the state of the art in tandem.
For Tech Strategists and Business Leaders: The broader trend indicated by this work is that AI is becoming more accessible and more adaptable. The power that once required a fortune in compute and a crack research team is rapidly trickling down. This compresses the timeline of AI adoption across industries – your competitors might deploy GPT-4-level AI in their workflows via an open model well before you budget for a big vendor contract. It also suggests that proprietary advantage in AI can be short-lived; an algorithmic breakthrough today might be open-sourced tomorrow. However, it also opens opportunities: organizations can craft their own foundation models tuned to their domain (be it finance, biomedicine, law) by starting from something like Falcon-H1 and extending it. Strategic differentiation may come from how you use and fine-tune the foundation models, rather than who has the biggest model. Additionally, keep an eye on the multimodal aspect – as models begin to handle text, images, and more in one system, companies that leverage that (e.g., an AI that can read documents and analyze associated charts/graphs all at once) will have an edge in insight extraction and automation.
Takeaway: The Falcon-H1 project shows that the future of AI won’t just be about piling on more parameters – it will be about combining ideas and domains to create smarter, more efficient systems. A hybrid model with “two brains” (attention + SSM) can outperform much larger single-minded models, hinting that the next leaps in AI might come from this spirit of integration. For those of us building and using these technologies, it’s a thrilling development. We should be prepared for AI models that are more like toolkits than one-trick ponies – able to see, listen, remember vast contexts, and reason, all in one. The foundations of AI are evolving, and with efforts like Falcon-H1, we’re getting a preview of a more surprising, accessible, and multimodal AI era to come.