
🧑🔬 Everything To Know About Deep Research
Learn about Deep Research Agents, MEM1, o4-mini and NoThinking
Welcome, Watcher! This week in LLM Watch:
Everything about Deep Research Agents
How AI can achieve long-term goals
High quality graph data improving tool use
Don’t forget to subscribe to never miss an update again.
Courtesy of NotebookLM
1. Deep Research Agents: A Systematic Examination And Roadmap
Watching: Deep Research Agents (paper/code)

What problem does it solve? Large Language Models have evolved from handling isolated tasks like question answering to more complex capabilities, but they still struggle with sustained, multi-step research workflows. Traditional approaches like Retrieval-Augmented Generation (RAG) improve factual accuracy but lack the ability to perform continuous reasoning and dynamic adaptation. The paper addresses the need for autonomous AI systems that can conduct end-to-end research tasks - from formulating research strategies to synthesizing comprehensive reports - without being limited by static workflows or pre-defined tool configurations.
How does it solve the problem? The authors conducted a systematic examination of Deep Research (DR) agents, analyzing their core components including search engine integration (API-based vs browser-based), tool invocation strategies, and architectural workflows. They propose a unified classification framework that differentiates between static workflows (predefined task pipelines) and dynamic workflows (adaptive task planning), while also categorizing planning strategies and agent architectures (single-agent vs multi-agent). The paper examines optimization approaches ranging from prompt-based methods to supervised fine-tuning and reinforcement learning, with particular attention to how systems like OpenAI DR and Gemini DR implement these techniques.
What are the key findings? The survey reveals that leading DR agents employ diverse approaches: industrial systems like OpenAI DR use reinforcement learning-based fine-tuning with single-agent architectures, while others adopt multi-agent configurations for task specialization. Browser-based retrieval provides more comprehensive access to dynamic content compared to API-based methods, though at higher computational cost. The authors identify critical limitations including restricted access to proprietary data sources, sequential execution inefficiencies, and significant misalignment between current benchmarks (which focus on simple QA tasks) and the actual capabilities needed for comprehensive research report generation.
Why does it matter? These findings establish a foundational understanding of how to build AI systems capable of autonomous scientific discovery and complex research tasks, potentially transforming how research is conducted across disciplines. The identified challenges - particularly around benchmark misalignment and the need for asynchronous parallel execution - provide a clear roadmap for advancing the field. As DR agents mature, they could dramatically accelerate research workflows by automating literature reviews, hypothesis generation, and evidence synthesis, making sophisticated research capabilities accessible to a broader audience while augmenting human researchers' productivity.
2. MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
Watching: MEM1 (paper)

What problem does it solve? Modern LLM agents struggle with long-horizon, multi-turn tasks because they typically append all past observations, actions, and thoughts to the context at every turn. This full-context prompting approach creates an ever-growing prompt that leads to quadratic computational costs (or linear with KV caching), massive memory requirements, and degraded reasoning performance as irrelevant information accumulates. Think of it like trying to remember every single detail of a long conversation - eventually your brain gets overloaded and you can't focus on what's actually important anymore.
How does it solve the problem? MEM1 introduces a clever approach where the agent learns to maintain a compact "internal state" that serves as both working memory and reasoning space. At each turn, instead of keeping all previous information, the agent consolidates its prior memory with new observations into this internal state, then discards everything else. The framework uses reinforcement learning to train this behavior end-to-end - the agent is rewarded for task success, which naturally incentivizes it to preserve only the most relevant information. They also introduce a masked trajectory approach to handle the technical challenge of training with dynamically changing contexts.
What are the key findings? When tested on multi-objective QA tasks, MEM1-7B achieved 3.5× better performance while using 3.7x less memory compared to the larger Qwen2.5-14B-Instruct model on complex 16-objective tasks. The agent maintained nearly constant memory usage even as task complexity increased from 2 to 16 objectives, while baseline methods showed linear memory growth. Additionally, MEM1 demonstrated strong generalization - agents trained on 2-objective tasks successfully handled up to 16-objective compositions without additional training.
Why does it matter? It demonstrates that LLMs can learn to manage their own memory as part of their reasoning process, eliminating the need for external memory modules or architectural changes. This makes it practical to deploy sophisticated AI agents for real-world applications like research assistants, web navigation, and customer service, where interactions can span dozens or hundreds of turns. By achieving better performance with less compute and memory, MEM1 makes advanced AI capabilities more accessible and sustainable, especially for organizations with limited resources.
3. Enhancing LLM Tool Use with High-quality Instruction Data from Knowledge Graph
Watching: LLM Tool Use (paper)
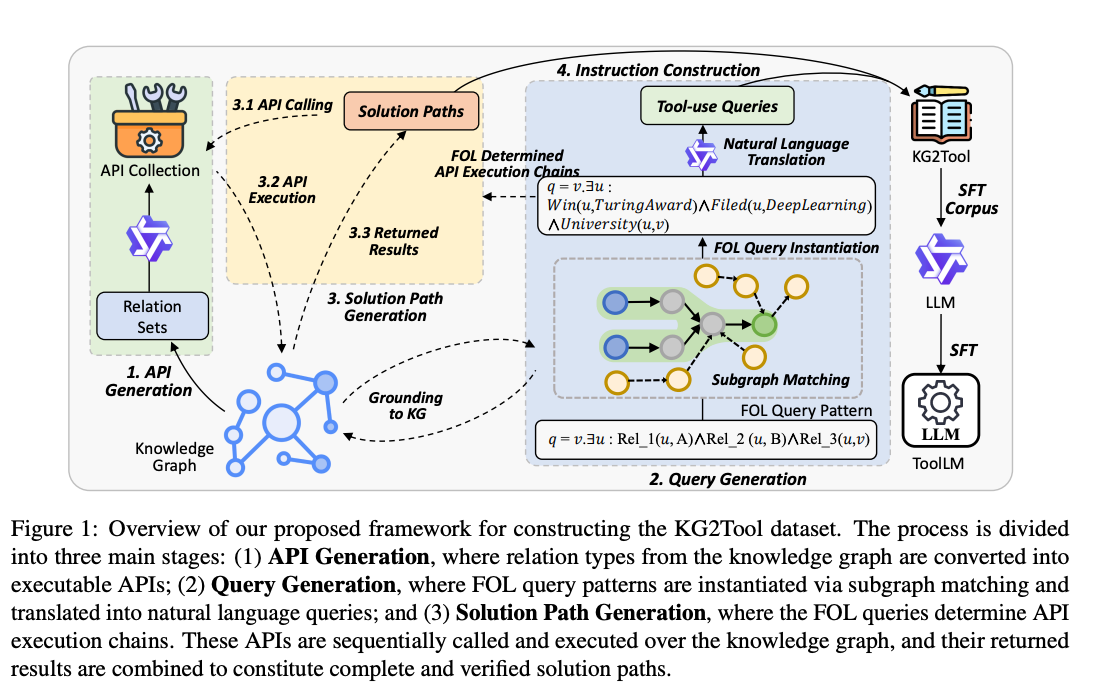
What problem does it solve? Teaching Large Language Models (LLMs) to effectively use tools has become crucial for expanding their problem-solving capabilities beyond text generation. While previous approaches have attempted to create instruction datasets for tool use, they've relied heavily on LLMs themselves to generate training data, resulting in inconsistent quality, insufficient complexity, and prohibitively high costs. The random sampling of APIs often leads to irrelevant tool combinations and overly simplistic queries that fail to challenge the reasoning capabilities of LLMs. Additionally, the extensive manual review and revision required for LLM-generated data makes scaling impractical.
How does it solve the problem? The authors propose leveraging knowledge graphs (KGs) as a source of high-quality instruction data. Since KGs represent structured knowledge with entities as nodes and relations as edges, each "entity-relation-entity" triple can be interpreted as an "input-function-output" operation, naturally mapping to tool use scenarios. The framework uses First-Order Logic (FOL) queries as intermediaries to systematically extract subgraphs and transform them into tool-use queries and solution paths. By converting KG relations into executable APIs and parsing query pathways into detailed solution steps, the method generates complex, multi-step tool combinations without relying on potentially flawed LLM-generated content.
What are the key findings? The experiments demonstrate that fine-tuning LLMs with just a small sample (2,000 instances) of the KG2Tool dataset leads to significant performance improvements on the T-Eval benchmark. For instance, ToolLM-7B achieved a 9.0% improvement over Qwen2.5-7B, reaching an overall score of 84.72 that surpassed GPT-3.5. Remarkably, ToolLM-14B achieved the highest score of 87.21, even outperforming its larger 70B parameter counterpart. The approach proved effective across different backbone models, with improvements ranging from 7.0% to 10.2% on various architectures.
Why does it matter? This addresses a critical bottleneck in developing tool-using LLMs by providing a scalable, cost-effective alternative to manual annotation and unreliable LLM-generated data. Since KGs are manually curated and verified, the resulting instruction data maintains high quality without requiring extensive human review or expensive API calls to commercial models. The ability to enhance smaller models (like 7B parameters) to achieve performance comparable to much larger models has significant implications for deploying efficient LLM applications. Moreover, the method not only improves tool utilization but also enhances general capabilities, particularly in multi-step reasoning tasks, suggesting broader applicability beyond tool use scenarios.

Papers of the Week:
ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs
RLPR: Extrapolating RLVR to General Domains without Verifiers
Enhancing LLM Tool Use with High-quality Instruction Data from Knowledge Graph
Text2Cypher Across Languages: Evaluating Foundational Models Beyond English
It is jaw dropping when you combine multiple agents working in tandem (structured and unstructured), while simultaneously providing RAG and tools.
https://www.srao.blog/p/your-ai-needs-a-fight-club
I am considering open sourcing the implementation.