
🥐 Claude 4 Is Here: What You Should Know
Learn about Claude 4, Meta's J1 and s3 for Search
Welcome, Watcher! This week in LLM Watch:
Leading the charge, Anthropic's Claude 4 transforms how AI tackles complex workflows with its dual-model approach. By combining Opus 4's heavyweight reasoning with Sonnet 4's everyday capabilities - both featuring extended thinking modes, tool integration, and 200K context windows - Claude 4 maintains coherence across multi-hour sessions and complex projects. With the ability to create persistent memory files while reducing hallucinations by 65%, we're witnessing AI that can truly own end-to-end development tasks without constant human supervision.
Next, Meta's J1 might change how we evaluate AI outputs through "thinking out loud" judges trained via reinforcement learning. Using just 22K synthetic examples, these judges outperform models distilled from much larger reasoning engines - even beating a 671B parameter MoE with a 70B footprint. By explicitly reasoning before rendering verdicts and dramatically reducing ordering bias, J1 creates more trustworthy evaluation tools that handle both objective and subjective tasks with remarkable efficiency.
Finally, s3 proves that less really can be more in AI search by decoupling retrieval from generation. By training only the search component with downstream-aware rewards, s3 achieves superior results with 70x less data and 33x faster training than end-to-end alternatives. This lightweight, modular approach not only outperforms conventional methods across both general and specialized domains but works seamlessly with any frozen or proprietary LLM - demonstrating that thoughtful architecture matters more than massive data or brute-force fine-tuning.
Don't forget to subscribe to never miss an update again.
1. Introducing Claude 4
Watching: Claude 4 (blog)

What problem does it solve? Modern AI helpers often hit a wall when faced with super-long or really tricky coding and reasoning tasks - they can’t juggle lots of details, can’t pause to call on tools like web search mid-thought, and lose track of things if you ask them to work for hours without a break.
How does it solve the problem? Anthropic built two new “Claude 4” models - Opus 4 for heavyweight, multi-step coding jobs and Sonnet 4 for everyday tasks - each with two modes: a near-instant response and an “extended thinking” mode that can call tools (web search, code runners, etc.) in parallel. They also gave both models a massive 200 K-token context window and the ability to create “memory files” when granted local file access, so key facts stick around for the long haul.
What are the key findings? Opus 4 now tops real-world coding benchmarks like SWE-bench and Terminal-bench and can sustain focused work over thousands of steps (even seven-hour refactors), while Sonnet 4 pushes Sonnet 3.7’s coding score even higher and follows complex instructions more precisely. According to Anthropic, both models are roughly 65% less prone to taking shortcuts or hallucinating answers on agentic tasks.
Why does it matter? This brings us closer to AI that can own entire software workflows - remembering context, fetching external info on the fly, and staying coherent across long sessions - so developers can trust AI companions with bigger, more complex projects without constant supervision.
2. J1: Incentivizing Thinking in LLM-as-a-Judge via Reinforcement Learning
Watching: J1 (paper)
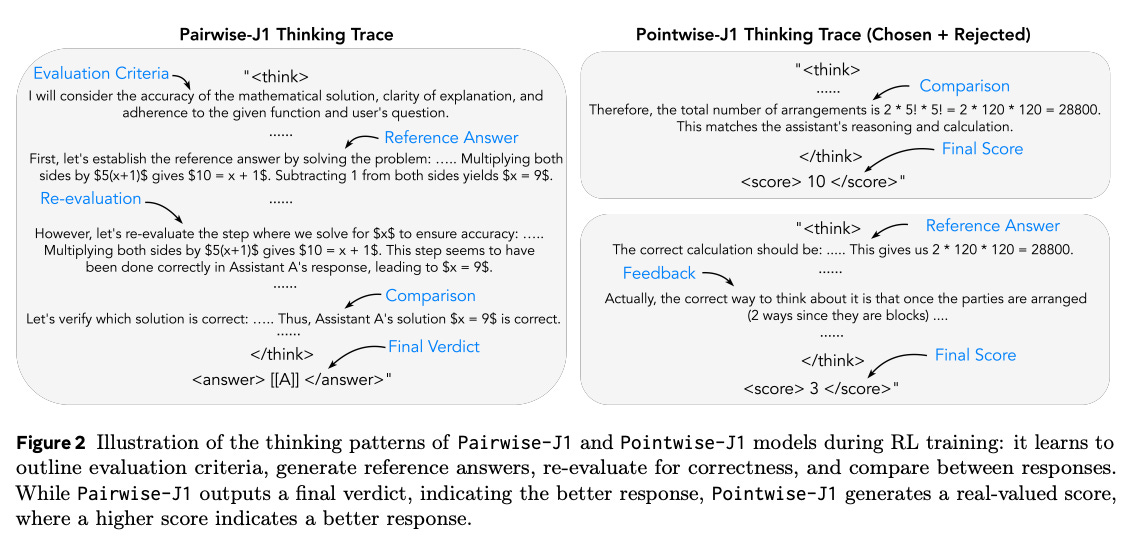
What problem does it solve? Modern AI systems - especially large language models - are only as good as the tools we use to evaluate them. Current “LLM-as-a-Judge” approaches often make snap judgments without clear reasoning, suffer from ordering biases (preferring the first‐shown answer), and struggle to handle both objectively verifiable tasks (like math problems) and more subjective user prompts. This evaluation bottleneck limits our ability to reliably align, benchmark, and improve LLMs across diverse applications.
How does it solve the problem? The team from Meta introduces J1, a reinforcement-learning recipe that trains LLM judges to “think out loud” via chain-of-thought before deciding which of two responses is better. First, they turn every evaluation (verifiable or not) into a task with a clear right answer by synthetically generating high-quality and low-quality response pairs. Then they train both pairwise (compare A vs. B) and pointwise (score each answer independently) judges using a verifiable reward signal - correct verdicts earn positive points and consistency across response orders earns extra points - optimized via the GRPO algorithm. They also design “seed prompts” to guide the model’s internal reasoning and mitigate position bias.
What are the key findings? J1-based judges at 8B and 70B parameters consistently beat all prior 8B and 70B SOTA judge models - including those distilled from much larger reasoning engines - across five benchmarks (PPE, RewardBench, JudgeBench, RM-Bench, FollowBenchEval). The 70B J1 model even out-performs a 671B Mixture-of-Experts model on subjective tasks. Test-time tricks like self-consistency and score averaging further boost accuracy, and the pointwise variant nearly eliminates order bias while maintaining high judgment quality.
Why does it matter? Reliable, (relatively) unbiased evaluation is crucial for safe and effective LLM development - from training with human feedback to real-world deployment. J1 demonstrates that with only 22K synthetic examples and online RL, you can build a generalist judge that reasons explicitly, handles both objective and subjective prompts, and scales to test-time improvements. This reduces reliance on costly human annotations, tightens the feedback loop for model alignment, and paves the way for more trustworthy AI systems.
3. s3: You Don't Need That Much Data to Train a Search Agent via RL

What problem does it solve? Large language models often need to “look things up” at inference time via Retrieval-Augmented Generation (RAG), but existing retrieval learners either optimize proxy scores (like NDCG) that don’t guarantee better answers or jointly fine-tune the entire model - entangling search with text generation, wasting data, compute, and making it hard to plug into frozen or proprietary LLMs. The core challenge is: how do you train a lightweight “searcher” that genuinely boosts downstream answer quality with minimal supervision?
How does it solve the problem? They introduce s3, a modular search-only agent trained by reinforcement learning (PPO) against a novel “Gain Beyond RAG” (GBR) reward. GBR measures the delta in generation accuracy when using s3’s retrieved documents versus naïve top-k retrieval. In each multi-turn loop, the searcher issues a query, fetches results, selects the most relevant documents (up to three), and decides when to stop. Crucially, the generator LLM remains frozen - only the search policy is learned - and it requires just 2.4 K training examples.
What are the key findings? Despite using 70x less training data, s3 outperforms static retrievers (BM25, E5), zero-shot active methods (IRCoT), retrieval-only RL (DeepRetrieval) and end-to-end RL (Search-R1) on six general-domain and five medical QA benchmarks. It achieves an average generation accuracy of 58.9% on general QA and 76.6% in medical QA (versus ≤54% and ≤74% for baselines), and it cuts total training time by roughly 33x compared to Search-R1.
Why does it matter? They demonstrate that most of the gain in RAG comes from smarter search, not giant end-to-end models or massive datasets. By decoupling - and directly optimizing - the search component with a downstream-aware reward, s3 offers a data- and compute-efficient path to ground LLMs, works with any frozen or proprietary generator, and even generalizes zero-shot to specialized domains like medicine. This modular, sustainable approach lowers the barrier for building reliable, up-to-date QA systems.

Papers of the Week:
AI Agents vs. Agentic AI: A Conceptual Taxonomy, Applications and Challenge
WildDoc: How Far Are We from Achieving Comprehensive and Robust Document Understanding in the Wild?
SubGCache: Accelerating Graph-based RAG with Subgraph-level KV Cache
When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs
Disentangling Reasoning and Knowledge in Medical Large Language Models
Learning to Think: Information-Theoretic Reinforcement Fine-Tuning for LLMs
Unify Graph Learning with Text: Unleashing LLM Potentials for Session Search
KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
AAPO: Enhance the Reasoning Capabilities of LLMs with Advantage Momentum
Optimizing Anytime Reasoning via Budget Relative Policy Optimization