
🤖 ChatGPT failing 92% of the time
As a large language model trained by OpenAI, I can't solve this task... yet

Before we start with this week’s newsletter, a quick announcement!
I’ve reactivated my Medium account and published an article about vector search with recency embeddings. If notebook-based tutorials are something that’s interesting to you, feel free to follow me over there and leave a clap or two.
The reason I’ve decided to publish this kind of content on Medium is that code blocks on Substack and Linkedin are hard to read without proper syntax highlighting.
But now, let’s dive into this week’s highlights together!
In this issue:
The hardest coding benchmark ever
Towards more truthful RAG
Putting a number on LLM emergence

1. PECC: Problem Extraction and Coding Challenges
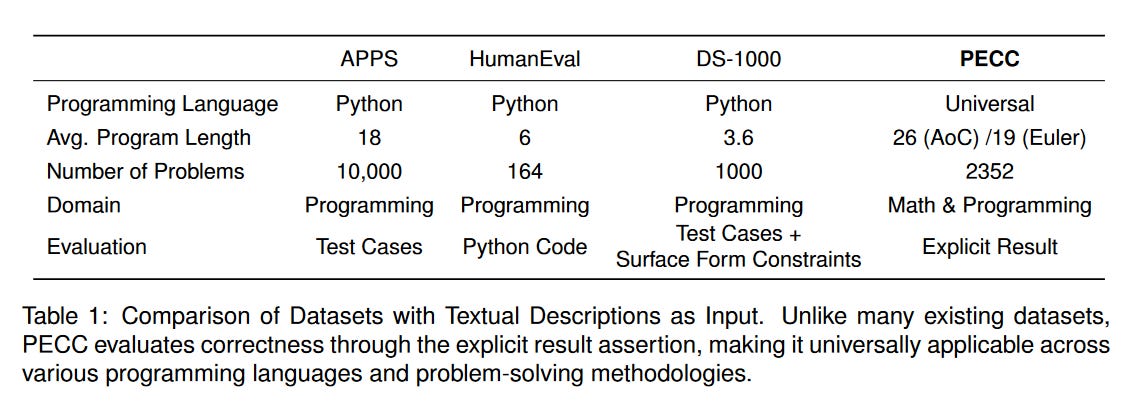
What problem does it solve? While Large Language Models (LLMs) have demonstrated impressive capabilities in various domains, including code generation and problem-solving, existing benchmarks often evaluate these tasks in isolation. However, real-world scenarios frequently involve understanding complex instructions presented in a prose-style format, identifying the underlying problems, and generating appropriate code solutions. The lack of benchmarks that assess LLMs' ability to handle such challenges limits our understanding of their true potential as universal problem solvers.
How does it solve the problem? To address this gap, the researchers introduce PECC, a novel benchmark derived from Advent of Code (AoC) challenges and Project Euler problems. PECC presents 2,396 problems that require LLMs to interpret narrative-embedded instructions, extract relevant requirements, and generate executable code solutions. The benchmark incorporates the complexity of natural language prompting in chat-based evaluations, mimicking the ambiguities often encountered in real-world instructions. By evaluating LLMs on PECC, researchers can gain insights into their ability to understand and solve problems presented in a more realistic and challenging format.
What's next? The results from evaluating LLMs on PECC highlight the varying performance of models when faced with narrative and neutral problems. GPT-3.5-Turbo, for example, successfully solves 50% of the AoC challenges but only 8% of the math-based Euler problems. These findings underscore the need for further research and development to enhance LLMs' problem-solving capabilities across diverse domains. As LLMs continue to evolve, PECC provides a valuable framework for monitoring and assessing their progress as universal problem solvers. Future work may focus on improving LLMs' ability to handle complex, narrative-based instructions and generate accurate code solutions, ultimately bringing us closer to the goal of creating truly versatile and reliable AI systems.
2. RAGTruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models
Watching: RAGTruth (paper)

What problem does it solve? Retrieval-augmented generation (RAG) has become a popular technique for reducing hallucinations in large language models (LLMs). However, despite the integration of RAG, LLMs may still generate unsupported or contradictory claims to the retrieved contents. To develop effective strategies for preventing hallucinations in RAG-based systems, it is crucial to have benchmark datasets that can accurately measure the extent of hallucination across various domains and tasks.
How does it solve the problem? RAGTruth is a corpus specifically designed to analyze word-level hallucinations in diverse domains and tasks within standard RAG frameworks for LLM applications. The dataset consists of nearly 18,000 naturally generated responses from various LLMs using RAG. These responses have been meticulously annotated at both the individual case and word levels, incorporating evaluations of hallucination intensity. By providing a high-quality dataset, RAGTruth enables the benchmarking of hallucination frequencies across different LLMs and the critical assessment of existing hallucination detection methodologies.
What's next? The researchers demonstrate that by using a high-quality dataset like RAGTruth, it is possible to finetune a relatively small LLM to achieve competitive performance in hallucination detection compared to existing prompt-based approaches that rely on state-of-the-art large language models like GPT-4. This finding suggests that the development of more efficient and accessible hallucination detection methods could be possible with the help of carefully curated datasets. As RAG continues to gain popularity in LLM applications, the availability of datasets like RAGTruth will be crucial in advancing research on hallucination prevention and ensuring the reliability of generated content.
3. Quantifying Emergence in Large Language Models
Watching: Emergence (paper/code)
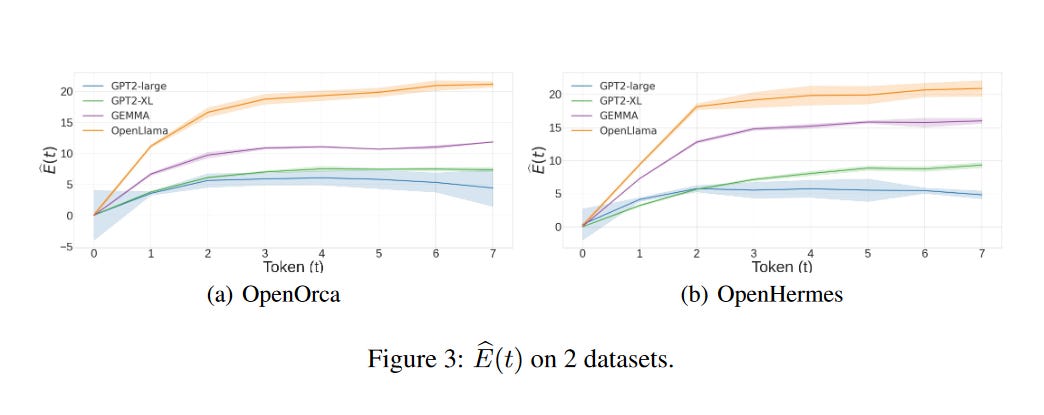
What problem does it solve? The concept of emergence in Large Language Models (LLMs) has been a topic of great interest, as it relates to the seemingly intelligent behaviors exhibited by these models. However, quantifying and measuring emergence has been a challenge due to the lack of a clear, measurable definition. Previous approaches have relied on extensive datasets and task-based performance metrics, which are resource-intensive and may not accurately capture the intrinsic emergence properties of the models.
How does it solve the problem? The proposed method quantifies emergence by comparing the entropy reduction at two levels: the macroscopic (semantic) level and the microscopic (token) level. These levels are derived from the representations within the transformer block of the LLM. By using a low-cost estimator, the method provides consistent measurements of emergence across various LLMs, such as GPT-2 and GEMMA, under both in-context learning (ICL) and natural sentence settings. The results align with existing observations based on performance metrics, validating the effectiveness of the quantification method.
What's next? The proposed emergence quantification method opens up new avenues for interpreting and understanding the behavior of LLMs. The study reveals novel emergence patterns, such as the correlation between the variance of the metric and the number of "shots" in ICL, which suggests a new way of interpreting hallucinations in LLMs. Furthermore, the method offers a potential solution for estimating the emergence of larger and closed-resource LLMs by using smaller, more accessible models like GPT-2. This could greatly facilitate the study of emergence in LLMs without the need for extensive resources.
Papers of the Week:
Retrieval-Augmented Language Model for Extreme Multi-Label Knowledge Graph Link Prediction
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context (updated models)
Beyond Code Generation: An Observational Study of ChatGPT Usage in Software Engineering Practice