
💥 Breaking Compute Barriers
Harder, Better, Faster, Stronger

In this issue:
Reading twice before you speak helps a lot
Breaking through the inference compute-bound
How speculation speeds up your processes

Want to market your brand? I’ve been personally using passionfroot since its launch and have found several partners on their platform. They make it easy for companies to find fitting creators for their brand and I’ve found their streamlined collaboration process to be more efficient and more enjoyable for both sides.
1. Re-Reading Improves Reasoning in Large Language Models
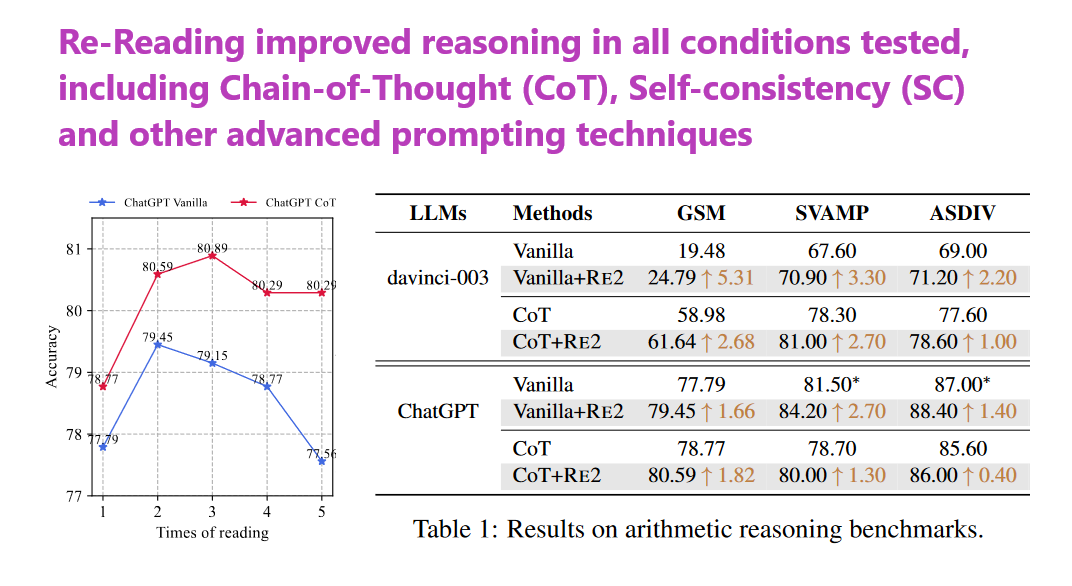
What problem does it solve? Understanding and reasoning within large language models (LLMs) can be a challenging task, especially when the inherent structure of these models restricts them to unidirectional information processing. Most enhancements in LLMS have focused on extracting complex thought processes within the models' outputs. Re2, stands out by doubling down on the input phase, effectively preprocessing questions in a two-pass manner. This aims to mimic a "bidirectional" mechanism, which potentially taps into a richer context for reasoning, something traditionally difficult for decoder-only LLM architectures to achieve.
How does it solve the problem? The Re2 prompting method innovates by implementing a "re-reading" strategy. Here's how it works: in the first pass, the LLM reads the input question and processes it to grasp the global context. The same question is then presented a second time, allowing the LLM to encode this broader context and align its understanding more closely with the task at hand. This dual-layer approach is paired with existing thought-eliciting prompting methods like Chain-of-Thought, enhancing the model's ability to reason through questions comprehensively. It essentially tricks a unidirectional model into a form of bidirectional processing, typically exclusive to models with more complex architectures.
What’s next? Given that Re2 has shown promising results across multiple reasoning benchmarks and various LLMs, the next steps will likely involve broader implementation and integration with other enhancement strategies. The sheer simplicity of the method, paired with its notable effectiveness, suggests that it could quickly become a staple in LLM reasoning tasks.
2. FlattenQuant: Breaking Through the Inference Compute bound for Large Language Models with Per-tensor Quantization
Watching: FlattenQuant (paper)
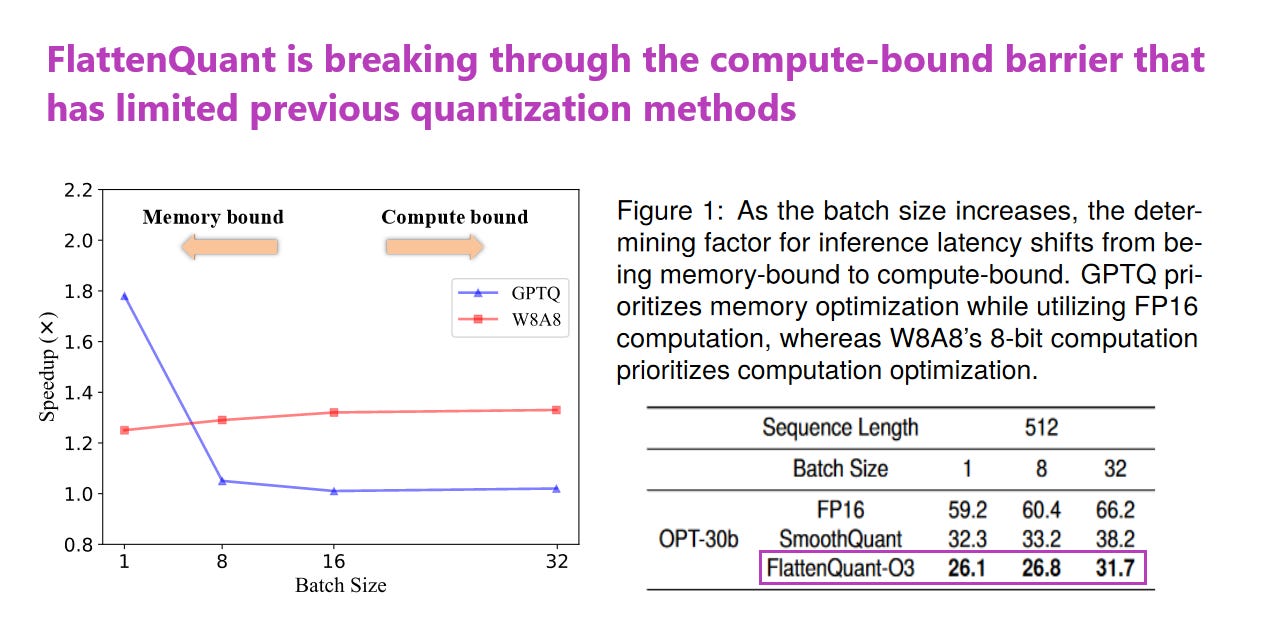
What problem does it solve? Deploying Large Language Models (LLMs) often faces two significant constraints: high latency during inference and the considerable amount of GPU memory required. Both factors can severely limit the practical use of LLMs, especially when working with large batch sizes or long sequences. While attempts have been made through quantization methods to tactically reduce these limitations, the problem of being compute-bound persists, especially when more precise computations (like FP16 data type) are necessary in linear layer calculations.
How does it solve the problem? FlattenQuant tackles this issue by strategically flattening large channels within a tensor, which allows for the tensor's maximum value to be significantly reduced. As a result, this method facilitates low bit per-tensor quantization with minimal sacrifice to model accuracy. Essentially, FlattenQuant enables some parts of linear layer calculations in LLMs to be carried out with just 4 bits, while the rest can be handled with 8 bits. This approach to matrix multiplication is particularly adept at addressing the issues that arise when dealing with compute-intensive operations, such as large matrix computation.
What’s next? The promising results of FlattenQuant with up to twice the speed and over double the memory reduction, all with negligible accuracy loss, pave the way for more efficient use of LLMs in real-world applications. Moreover, as this line of research evolves, we can expect other innovative quantization strategies to emerge, potentially offering even greater optimizations and expanding the horizon for LLM applications. The question now is how well these techniques can be generalized across different models and tasks, and whether they'll become standard practice in the industry.
3. Cascade Speculative Drafting for Even Faster LLM Inference
Watching: CS Drafting (paper)
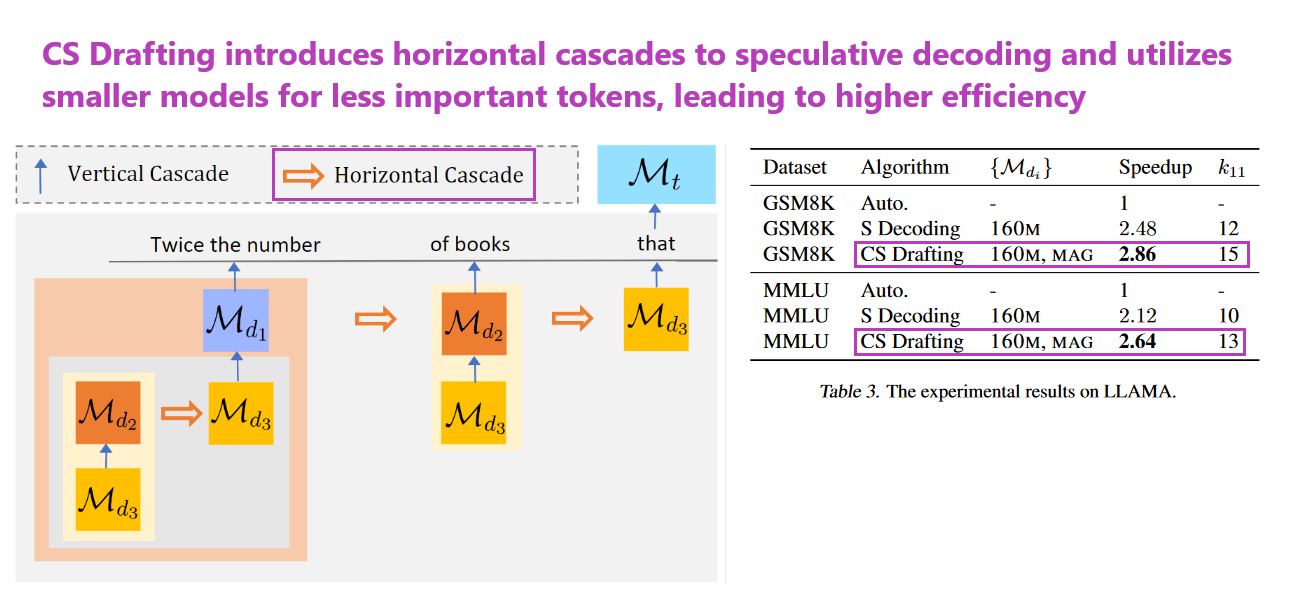
What problem does it solve? The technology of speculative decoding was introduced to expedite the inference process of Large Language Models (LLMs) by initially generating a draft with a smaller model, which a larger model then adjusts to align with its higher-quality output. Despite its potential for efficiency, the process is hindered by slow autoregressive generation and uniform time allocation for each token, regardless of its actual importance. These issues culminate in limiting the full benefits of speculative decoding.
How does it solve the problem? CS Drafting innovates by integrating two cascading methods to fine-tune the speculative decoding process. The Vertical Cascade removes the need for slow autoregressive generation by introducing non-autoregressive strategies from neural networks, which reduces the time to generate sequences. Meanwhile, the Horizontal Cascade smartly allocates the time needed for drafting based on the significance of each token, ensuring that more critical parts of the text are given the appropriate focus. This targeted allocation of resources is key to maximizing efficiency.
What's next? With CS Drafting demonstrating an impressive speed increase of up to 81% over traditional speculative decoding while maintaining output quality, follow-up research will likely focus on refining and testing this approach across various models and applications to determine its limits and full capabilities. Additionally, with the code made public, the broader community can contribute to this innovation, potentially leading to wider adoption and further performance enhancements.
Papers of the Week:
PythonSaga: Redefining the Benchmark to Evaluate Code Generating LLM
Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation
Improving Sentence Embeddings with an Automatically Generated NLI Dataset
DeepCode AI Fix: Fixing Security Vulnerabilities with Large Language Models
Aligning Large Language Models to a Domain-specific Graph Database
From Summary to Action: Enhancing Large Language Models for Complex Tasks with Open World APIs