
🍎 - BIG News from Apple
The tech giant's new found love for sharing

In this issue:
Solving data-transfer bottlenecks with SparQ
Teaching LLMs to “think before speaking”
Apple spilling all their tea

1. SparQ Attention: Bandwidth-Efficient LLM Inference
Watching: SparQ Attention (paper/code)

What problem does it solve? The vast computational resources required for large language model (LLM) inference present a major hurdle for their practical use, especially when managing extensive input sequences and sizable batch processes. A notable issue is that the generation of tokens tends to be impeded by data-transfer limitations. To address this issue and improve the efficiency of LLMs during inference, the research introduces SparQ Attention, which optimizes the use of memory bandwidth in the attention mechanism, focusing on the selective fetching of cached historical data.
How does it solve the problem? SparQ Attention addresses the inefficiency of memory bandwidth usage by selectively retrieving only the necessary parts of cached history during the attention processes of LLMs. This targeted approach avoids the need to fetch the entire history, which can result in significant reductions of data-transfer demands during model inference. Moreover, SparQ Attention's design allows for its implementation on existing LLMs without the need for alterations in the pre-training setup or extra fine-tuning, making it a convenient, drop-in enhancement for increased inference throughput.
What’s next? Given its straightforward integration and demonstrated ability to multiply data-transfer savings by up to eight times without compromising accuracy significantly, SparQ Attention seems poised for broad adoption. As it is further validated across diverse downstream tasks and models like Llama 2, Mistral, and Pythia, we may see a new standard emerging for LLM inference optimization.
2. Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
Watching: Quiet-STaR (paper)
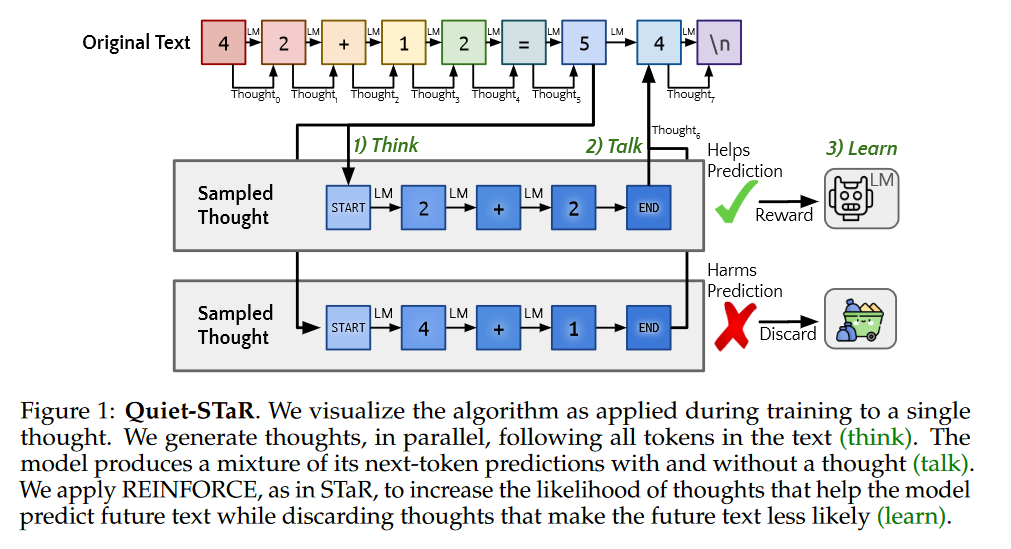
What problem does it solve? The ability to reason or infer unstated rationales is a sophisticated aspect of human cognition that remains a challenge for artificial intelligence. Current language models often lack the finesse to implicitly understand and explain the steps between statements, which encompasses reasoning within written text. Quiet-STaR tackles this by improving language models' predictions through the generation of rationales at each token to explain subsequent text, effectively teaching itself to reason more like humans do.
How does it solve the problem? Quiet-STaR addresses the computational burden and knowledge acquisition barriers of generating these internal thoughts in language models. It utilizes a tokenwise parallel sampling algorithm paired with learnable tokens to indicate the beginning and end of a thought. Additionally, it expands on teacher-forcing techniques to enhance the LM's predictive capabilities, particularly for challenging-to-predict tokens. By integrating this approach, Quiet-STaR efficiently teaches language models to generate and use internal thoughts for more intuitive reasoning.
What’s next? The promising zero-shot performance gains seen with Quiet-STaR suggest that language models can be preconditioned for stronger reasoning abilities without task-specific fine-tuning. The door is now open to further research into how LMs can self-improve their inference and reasoning skills. Moreover, the methodology could lead to more intelligent and autonomous systems capable of understanding and interacting with the world in more human-like ways.
3. MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Watching: MM1 (paper)

What problem does it solve? The integration of different types of data — notably text and images — into Large Language Models to create Multimodal Large Language Models (MLLMs) is a challenging frontier in AI. While many strides have been made, the performance of such models often hinges on the nuances of their architecture and the diversity of their pre-training data. The problem addressed here is to determine which components of these MLLMs are most critical for achieving top-tier performance across various benchmarks, especially in a few-shot learning setting, where a model is expected to perform well with minimal input.
How does it solve the problem? The study tackles this problem through extensive ablation studies, which involve systematically modifying or removing certain parts of the MLLM's design, such as the image encoder and the vision-language connector, to understand their impact. Specifically, the research identifies the optimal blend of training data, including image-caption pairs, interleaved image-text sequences, and text-only data, as being key to achieving state-of-the-art results. It emphasizes the significant role of the image encoder and the quality of images used (resolution and token count) for the model's performance while suggesting that the design of the vision-language connector is less critical. This knowledge is then applied to the construction of a new family of powerful MLLMs named MM1, which showcases remarkable improvements in various pre-training metrics and fine-tuning tasks.
What’s next? The creation of MM1 paves the way for MLLMs to advance significantly, potentially spearheading new possibilities for AI applications requiring nuanced multimodal understanding and interaction. The study provides a blueprint for scaling MLLMs, which researchers and developers will likely iterate upon, possibly leading to breakthroughs in complex tasks that demand a sophisticated grasp of both visual and linguistic elements.
Papers of the Week:
Masked Structural Growth for 2x Faster Language Model Pre-training
UltraWiki: Ultra-fine-grained Entity Set Expansion with Negative Seed Entities
Fact-Checking the Output of Large Language Models via Token-Level Uncertainty Quantification
Proxy-RLHF: Decoupling Generation and Alignment in Large Language Model with Proxy
GraphInstruct: Empowering Large Language Models with Graph Understanding and Reasoning Capability