
🛠️ Automatic Prompt Engineering 2.0
And how over-tokenization can help in scaling LLMs more efficiently
In this issue:
Backpropagation for prompts
An old new way of scaling LLMs
A Chinese AI giant doubling down

If you’re working in the industry, or a high-risk setting even, you probably know that a lot of the most valuable data can often not be used effectively because of privacy concerns.
But did you know that there is a way to make use of such assets without breaching privacy?
MOSTLY AI just released the world’s first industry-grade open-source toolkit for synthetic data creation. Their SDK supports tabular as well as textual data, differential privacy, automated quality assurance, and more, all while bringing a SOTA privacy-accuracy trade-off up to 100x faster than existing solutions.
You can check it out here for free.
1. LLM-AutoDiff: Auto-Differentiate Any LLM Workflow
Watching: LLM-AutoDiff (paper/code)

What problem does it solve? Current prompt engineering methods for directing Large Language Models (LLMs) in complex workflows — like multi-step pipelines combining retrieval, reasoning, and formatting — require extensive manual tuning. This becomes especially cumbersome when tasks involve cyclic or repeated LLM calls (e.g., iterative refinement loops), leading to inefficiency and suboptimal performance in applications such as multi-hop question answering or autonomous agents.
How does it solve the problem? The authors developed LLM-AutoDiff, an automatic prompt engineering framework that treats textual prompts as trainable parameters. Inspired by neural network optimization, the framework uses a frozen "backward engine" LLM to generate textual feedback (akin to gradients) that iteratively refines prompts across multi-component workflows. This approach uniquely handles cyclic dependencies, isolates sub-prompts (e.g., instructions, formats) to prevent context dilution ("lost-in-the-middle"), and prioritizes error-prone samples for faster training.
What are the key findings? LLM-AutoDiff outperformed existing textual gradient methods in accuracy and efficiency across diverse tasks, including single-step classification and multi-hop retrieval workflows. Notably, it improved performance in agent-driven pipelines and resolved bottlenecks in sequential LLM calls (e.g., multi-hop loops), demonstrating robustness in scenarios where traditional prompt engineering struggles.
Why is this important? By automating prompt optimization for complex LLM architectures, this work could democratize advanced LLM applications, much like automatic differentiation libraries (e.g., TensorFlow, PyTorch) revolutionized neural network training. It addresses scalability challenges in real-world deployments, where manual tuning becomes impractical, and opens the door to self-optimizing LLM systems for tasks like dynamic decision-making or iterative problem-solving.
2. Over-Tokenized Transformer: Vocabulary is Generally Worth Scaling
Watching: Over-Tokenization (paper)

What problem does it solve? The article addresses the underappreciated role of tokenization in large language models (LLMs), particularly how vocabulary design impacts model scaling and performance. While tokenization is foundational to LLMs, the relationship between input/output vocabulary configurations and scaling dynamics remains poorly understood—especially whether expanding vocabularies could reduce computational costs or improve efficiency without scaling model size.
How does it solve the problem? The authors proposed Over-Tokenized Transformers, which decouples input and output vocabularies to enable asymmetric scaling. By scaling input vocabularies to include more multi-gram tokens (e.g., phrases or common word combinations), the framework allows richer input representations while keeping output vocabularies compact. This approach tests whether larger input vocabularies—independent of model architecture size—consistently improve performance.
What are the key findings? Experiments revealed a log-linear relationship: doubling input vocabulary size yields predictable reductions in training loss, regardless of model scale. For example, models using enlarged input vocabularies matched the performance of models twice their size, with no added computational cost. This suggests tokenization optimization can rival traditional model scaling strategies.
Why is this important? The findings redefine tokenization’s role in scaling laws, challenging the assumption that model size alone drives performance. Practically, this enables cost-efficient LLM development—improving capabilities without expensive compute upgrades. For research, it highlights tokenizer design as a critical lever for efficiency, potentially reshaping how LLMs are architected and trained.
3. Qwen2.5-Max: Exploring the Intelligence of Large-scale MoE Model
Watching: Qwen2.5-Max (blog)
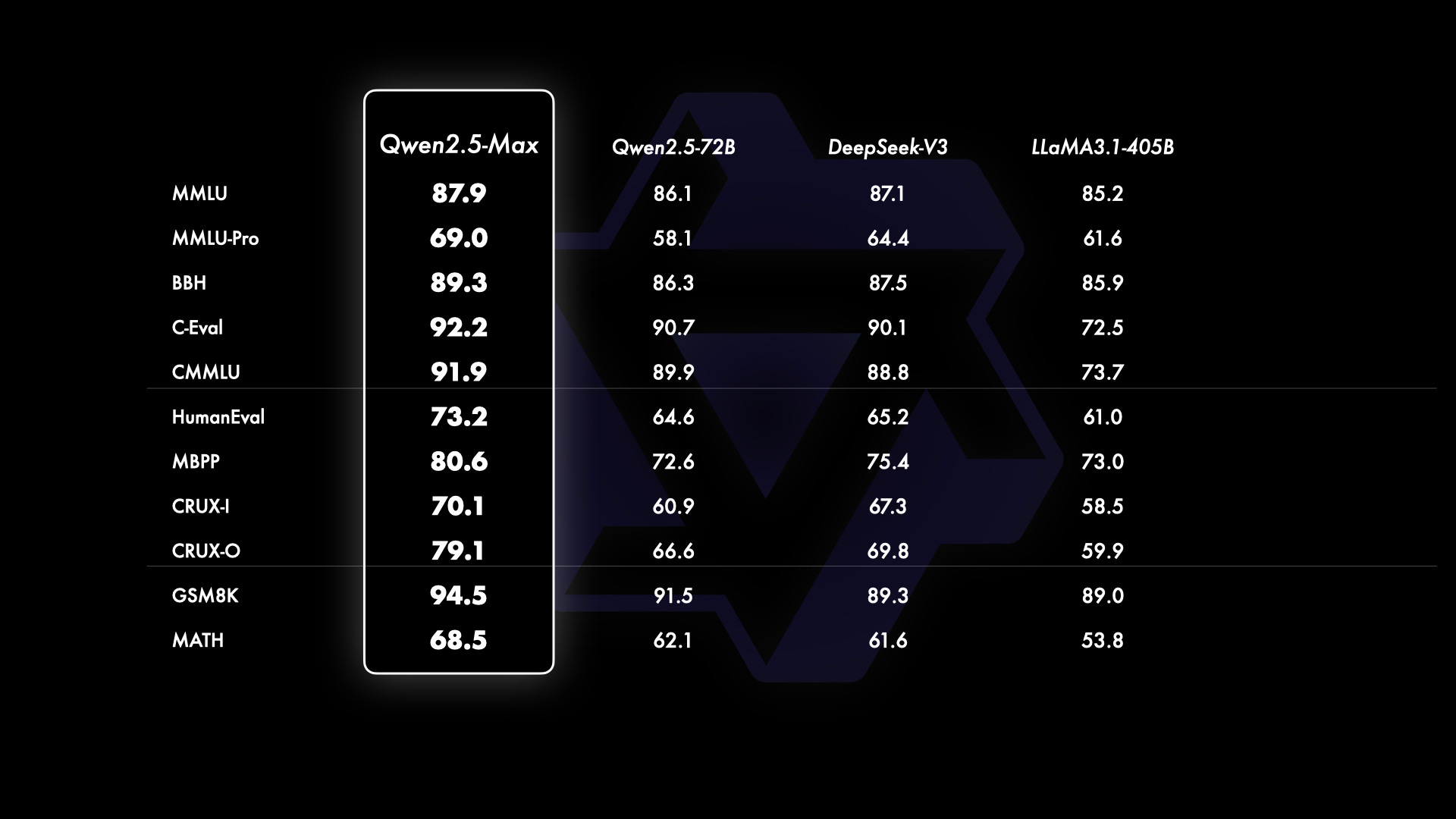
What problem does it solve? Scaling extremely large language models—whether dense architectures or Mixture-of-Experts (MoE) variants—remains a poorly understood challenge due to limited public insights into effective training methodologies. While continuous scaling of data and model size is known to improve performance, critical practical details (e.g., balancing expert specialization in MoEs, optimizing trillion-token pretraining) are often proprietary, hindering broader advancements in the field.
How does it solve the problem? The team developed Qwen2.5-Max, a massive MoE model pretrained on over 20 trillion tokens, combining curated Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) for post-training alignment. By openly sharing performance results and deployment details (e.g., API availability via Alibaba Cloud), they provide insights into scaling strategies, benchmarking against leading models like DeepSeek V3 and GPT-4o.
What are the key findings? Qwen2.5-Max achieves state-of-the-art performance across high-stakes benchmarks: MMLU-Pro (college-level knowledge), LiveCodeBench (coding), and Arena-Hard (human preference alignment). Notably, it competes closely with proprietary models like Claude-3.5-Sonnet, demonstrating the efficacy of its MoE architecture and scaled training pipeline.
Why is this important? Scaling large MoE models remains understudied, and Qwen2.5-Max provides empirical evidence for successful scaling strategies (e.g., massive data and post-training techniques). Its public API availability lowers barriers to deploying advanced LLMs, while its benchmark performance highlights the practical viability of MoE architectures for complex tasks.
Papers of the Week:
Fast Think-on-Graph: Wider, Deeper and Faster Reasoning of Large Language Model on Knowledge Graph
VERUS-LM: a Versatile Framework for Combining LLMs with Symbolic Reasoning
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
PISCO: Pretty Simple Compression for Retrieval-Augmented Generation
A foundation model for human-AI collaboration in medical literature mining