
AI Agents of the Week: Papers You Should Know About
Get ahead of the curve with LLM Watch
Executive Summary
This week in AI agents, researchers closed critical gaps in world-model planning, enabling faster and more efficient decision-making. New specialized agents demonstrated domain expertise - from a cybersecurity agent that outperforms traditional tools to frameworks for enterprise-grade software agents.
A landmark study from Google established the first scaling laws for multi-agent systems, revealing when adding agents helps or hinders performance.
Meanwhile, multiple works tackled the long-term autonomy problem: a self-healing agent runtime that monitors and fixes an agent’s mistakes on the fly, and a dynamic memory system that lets agents learn from experience, even surpassing larger models without memory.
Finally, researchers are beginning to formalize agent behavior and design principles - using game theory to audit LLM agent strategies and drawing parallels from human organizations to engineer more reliable, aligned agents.
In the detailed sections below, we break down each paper’s core innovation, why it matters for autonomous AI, the problems addressed, and future implications.
Closing the Train-Test Gap in World Models for Gradient-Based Planning (paper/code)
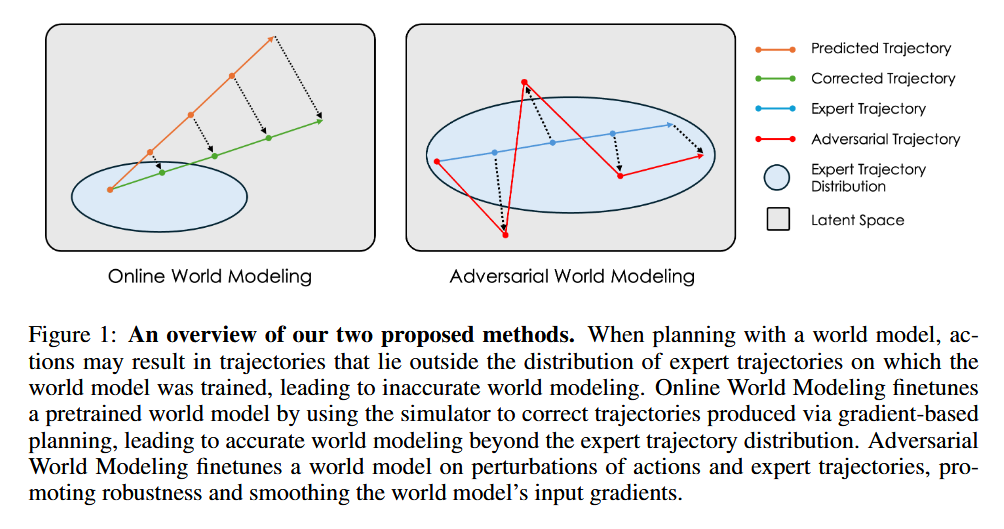
Core innovation: Aligning training objectives of world models with how they are used at test-time, enabling dramatically better planning performance. Parthasarathy et al. observe that learned world models are trained to predict next states, yet deployed to plan sequences of actions - creating a train-test mismatch. They propose train-time data synthesis techniques to make the model practice what it will eventually do: plan multi-step actions. By augmenting the training with trajectories optimized for planning, the world model learns to bridge the gap between predicting and planning.
Why it matters: Planning agents often face a dilemma: fast gradient-based planning (using differentiable models) is elegant but has trailed more brute-force methods. This work shows it’s possible to retain efficiency without sacrificing performance. With the new training approach, a gradient-based planner can match or outperform classical planning (like cross-entropy search) on complex manipulation and navigation tasks, while operating 10× faster. This means autonomous agents can plan actions in real time more effectively, an important step for agents in physical or time-constrained environments.
Problem it addresses: The historical performance lag of gradient-based MPC (Model Predictive Control). Traditional MPC either does exhaustive search or solves optimizations iteratively, which is slow. Gradient-based planning is faster but until now underperformed because world models weren’t trained for that purpose. By closing this gap, the authors eliminate a key inefficiency, ensuring the agent’s internal world model is truly optimized for decision-making rather than just state prediction.
Future implications: Agents that learn world dynamics can be directly used for real-world robotics and game AI planning without heavy search or human-engineered planners. This approach could be combined with ever-larger datasets of expert trajectories to yield generalist world models that plan well out-of-the-box. Also, having Yann LeCun among the authors signals interest in differentiable planning for autonomy - expect to see these ideas influence next-generation self-driving car agents or household robots that need quick, adaptive planning in open-ended tasks. Finally, aligning training with usage is a principle that might extend beyond world models to other agent components, improving the consistency and robustness of agent behavior.
