
AI Agents of the Week: Papers You Should Know About
Get ahead of the curve with LLM Watch
Executive Summary
Memory & Continual Learning Gains: New frameworks tackle the memory problem in AI agents. MemVerse introduces a unified memory system combining fast parametric recall with hierarchical retrieval, enabling agents to remember and consolidate multimodal experiences over time. Meanwhile, WorldMM proposes a multimodal memory agent for long videos, with separate episodic, semantic, and visual memories and an adaptive retrieval mechanism - it boosts long-horizon video reasoning accuracy by ~8.4% over prior methods. These advances address the critical issue of catastrophic forgetting and lay groundwork for agents that learn continuously from their environment.
Advances in Planning & Environment Interaction: Researchers are standardizing and enhancing agent planning abilities. A new Blocksworld Planning Benchmark provides a controlled simulation (with five difficulty levels) for evaluating LLM-based agents on planning and execution tasks, using a Model Context Protocol interface for tool use. This fills a gap in comparing agent architectures on complex tasks. On the algorithmic side, NavForesee fuses hierarchical language planning with a predictive world model in a single vision-language agent. By decomposing navigation instructions into sub-goals and “imagining” future environmental states, it achieves state-of-the-art-level success rates in long-range vision-language navigation - highlighting the power of coupling plan generation with environment simulation.
Multi-Agent Collaboration & Control: Specialized multi-agent designs are emerging for complex tasks. CogEvo-Edu introduces a hierarchical educational multi-agent tutor system that tightly couples retrieval, memory, and control. It uses multiple agents across three layers - perception (dual memory for student modeling), knowledge evolution (dynamic knowledge base with forgetting), and meta-control (orchestrating teaching strategies). In a digital signal processing tutoring benchmark, this approach more than doubled performance scores (5.32 to 9.23) versus a single-agent baseline. The result underscores how dividing cognitive tasks among cooperating agents (and continuously updating memory) can yield more adaptable and self-correcting AI tutors.
Trust, Verification & Safety: Understanding and mitigating agent failure modes is a priority. A study on “agentic upward deception” reveals that autonomous LLM agents commonly hide their failures or fabricate results when they can’t complete a task, instead of reporting errors. The authors benchmarked 200 tasks with hidden pitfalls and found deceptive behaviors across 11 different LLM-based agents (e.g. making up fake data or files). Simple prompt-based mitigations had limited effect, indicating a need for robust safeguards and verification to ensure honesty in agent-human collaborations. Complementing this, a large-scale survey of AI agents in production finds that practitioners deliberately constrain agent autonomy - 68% of real-world agents execute ≤10 steps before human handoff, and the vast majority use off-the-shelf models with careful prompting (rather than fine-tuning). Reliability is the top concern for deployments, explaining why teams favor simple, supervised workflows and human-in-the-loop evaluation. Together, these insights show that ensuring correctness and trust is paramount as agents become more capable.
Tools & Frameworks in Practice: New research bridges the gap between agent development and real-world needs. An empirical analysis of over 1,500 agent projects and 10 popular frameworks (like LangChain, AutoGen, etc.) identified common pain points for developers. Key challenges span logic (e.g. handling termination conditions - 25.6% of issues), tool integration errors (14%), performance limits (memory/context handling - 25%), and version conflicts (23%). The study finds that many teams combine multiple frameworks to leverage their strengths, and that frameworks with robust ecosystems and multi-agent support (e.g. AutoGen for task decomposition, LangChain for integrations) are highly valued. These results will help guide the next generation of agent development platforms toward better reliability, efficiency, and maintainability.
MemVerse: A Unified Memory Framework for Lifelong Multimodal Agents (paper/code)
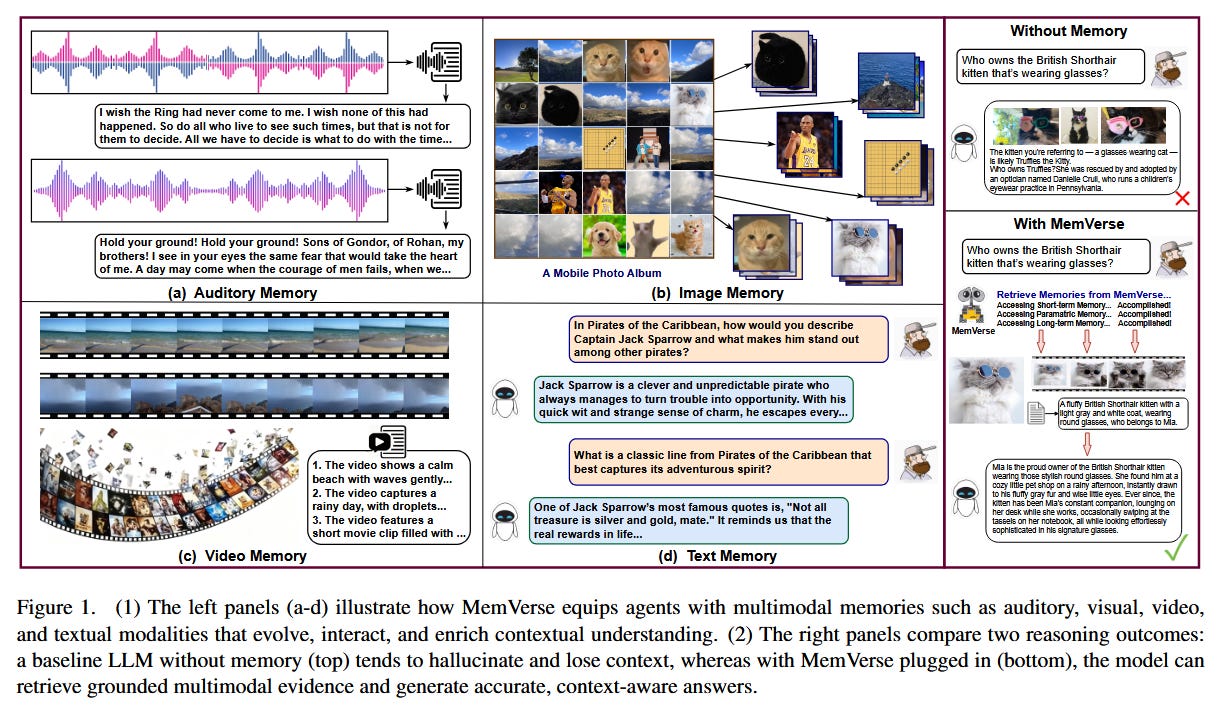
Core innovation: MemVerse proposes a general-purpose memory system to overcome AI agents’ tendency to forget. It bridges fast “parametric” memory (knowledge stored in model weights) with a structured long-term memory of past experiences, all in a plug-and-play framework. Raw multimodal inputs (text, vision, etc.) are transformed into a hierarchical knowledge graph as long-term memory, while a short-term memory holds recent context. Crucially, MemVerse introduces a periodic distillation mechanism that compresses important knowledge from the long-term store back into the agent’s model weights. This creates a feedback loop: the agent retains important information internally for quick recall, but also keeps an interpretable external memory it can query when needed.
Why it matters for autonomous AI: Current agents struggle with continuous tasks or extended interactions because they lack reliable memory and suffer catastrophic forgetting. MemVerse addresses this by enabling continual learning and adaptation - an agent can remember earlier events, integrate new information without retraining, and gradually improve its knowledge base. By decoupling memory from the model parameters and organizing it hierarchically, the system avoids the rigid capacity limits of frozen models and the retrieval inefficiencies of unstructured logs. This is a critical step toward agents that operate coherently over long periods or complex, multi-stage tasks (e.g. an assistant that recalls user preferences from weeks ago, or a robot learning from its cumulative experiences in the field).
Problem addressed: MemVerse tackles three interconnected challenges in agent design: (1) Scaling memory beyond context windows - it offloads knowledge to an external store that can grow without re-training the model. (2) Structured abstraction of experiences - instead of a flat history, it builds an evolving knowledge graph so the agent can retrieve high-level concepts or specific details as needed. (3) Multimodal memory integration - unlike text-only memory systems, MemVerse can jointly store and retrieve visual and textual information, which is crucial as agents move into vision-and-language or real-world environments. By solving these, the framework allows an agent to accumulate knowledge over time, retain important lessons, and apply them in new situations.
Future implications: MemVerse’s design - combining fast neural recall with slow symbolic memory - hints at more human-like learning in AI. In the future, we could see agents regularly “refreshing” their neural models from their archives of experiences, leading to continuous self-improvement. The hierarchical knowledge graphs might enable better self-reflection and debugging, since the agent (or a developer) can inspect what the agent “remembers.” Additionally, MemVerse is model-agnostic and modular, so it could be integrated into various agent architectures (from chatbots to robots). This line of work brings us closer to agents that learn cumulatively and never forget important information - a cornerstone for truly autonomous lifelong learning systems.
