
AI Agents of the Week: Papers You Should Know About
Get ahead of the curve with LLM Watch
Executive Summary
Memory as a First-Class Citizen: A comprehensive survey this week formalized agent memory as a core capability, cutting through fragmented terms and approaches. It proposes a unified taxonomy of memory forms (token-level logs vs. parametric weights vs. latent vectors) and functions (factual knowledge vs. experiential learning vs. working scratchpad). This clarity matters because long-term memory is emerging as essential for autonomous agents, yet inconsistent terminology and design hinder progress. By mapping out how agents form, use, and update memories, the survey lays groundwork for agents that remember and learn over time, with future research charted in memory automation, integration with reinforcement learning, multimodal memory, and trustworthy memory handling.
Multi-Agent Reasoning Accelerates Complex Tasks: New frameworks show that multiple specialized agents, or hierarchical agent roles, outperform solo agents on long-horizon problems. In scientific discovery, a “peer-review” style multi-agent system (MASTER) had LLM-based agents design experiments, critique results, and triage next steps, slashing required simulations by up to 90% compared to unguided trial-and-error. The agents’ decisions were scientifically grounded (e.g. identifying meaningful chemical patterns) beyond what random sampling or single-model biases could achieve. Similarly, another study had two embodied agents with asymmetric knowledge collaborate: by adopting an active querying protocol, the “follower” agent learned to ask the right questions to leverage the leader’s privileged information, doubling the team’s success rate on embodied tasks (17% → 35%) and overcoming communication failures. Together, these works highlight how multi-agent collaboration and better communication (through hierarchical plans, peer review, or query-answer interplay) can tackle complex, real-world tasks more efficiently than a lone agent.
Tool Use, Multimodality, and Self-Reflection: Advancing autonomy also means integrating external tools and perception into an agent’s reasoning loop. One highlight is Ophiuchus, a medical AI agent that can “think with images” by deciding when to invoke image analysis tools, where to zoom into a medical image, and then how to incorporate that visual evidence back into its chain-of-thought. It uses a novel three-stage training: (i) tool-augmented reasoning demonstrations, (ii) a self-reflection fine-tuning phase that teaches the agent to revisit and correct its own intermediate conclusions, and (iii) an “Agentic Tool Reinforcement Learning” stage to optimize its policy for diagnostic tasks. The result is a multimodal agent that significantly outperforms state-of-the-art methods on medical visual QA and diagnosis benchmarks. This underscores a broader trend of agents using tools (search, APIs, simulators) in a feedback loop - planning actions, observing outcomes, and self-correcting - which is crucial for robustness on open-ended tasks.
Evaluating Autonomy Beyond Task Success: As agents become more complex (using tools, memory, other agents), how we evaluate them is being rethought. Researchers introduced an end-to-end Agent Assessment Framework with four pillars - the LLM’s own reasoning, its use of memory, its tool use, and its environment interactions - to capture performance in a holistic way. In real cloud operations tests, this framework revealed subtle behavioral deviations and failure modes that one-dimensional success/failure metrics missed. In parallel, a study on “knowledge collapse” warns that if AI agents continually train on their own or each other’s outputs, they risk converging to a narrow, degraded pool of knowledge. Interestingly, diverse model “ecosystems” can mitigate this collapse - but only up to a point, as too little or too much diversity both hurt performance. These findings point to a future where we monitor and incentivize diversity in agent teams and evaluate them on rich criteria (robustness, adaptability, cooperation), not just whether they got the right answer.
In the detailed highlights below, we unpack each paper’s core innovation, why it matters for autonomous AI, the problems it addresses, and future implications.
Memory in the Age of AI Agents: A Unified Memory Taxonomy (paper)
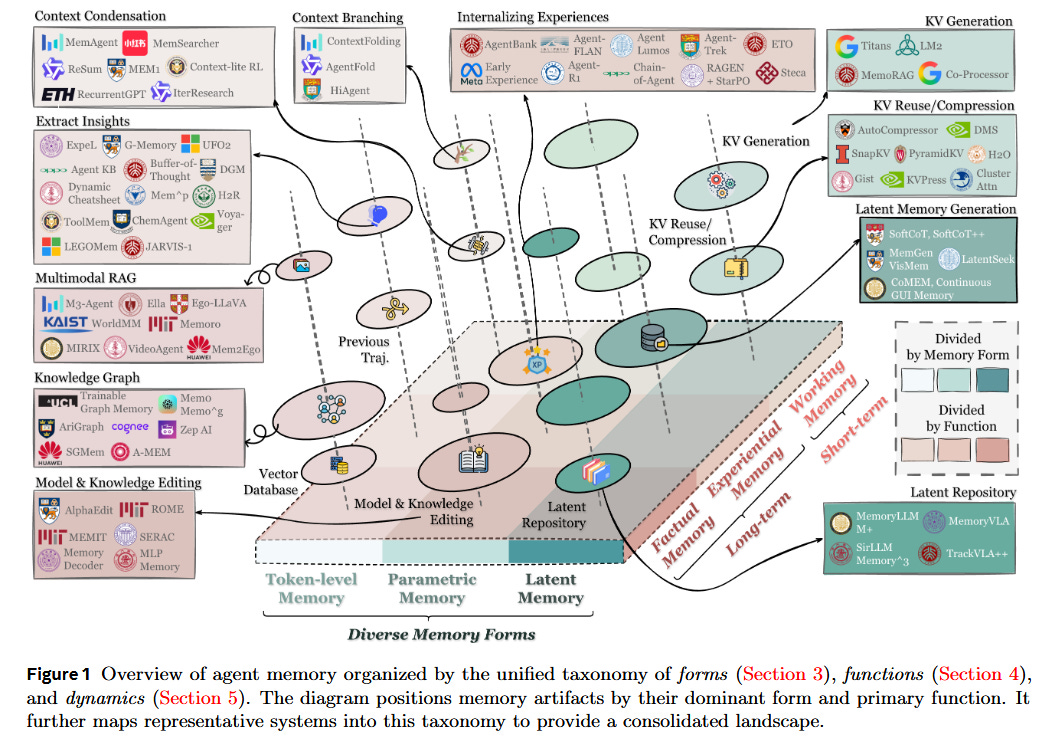
Core innovation: This work is a sweeping survey that brings order to the chaotic landscape of memory for AI agents. The authors propose a unified framework to categorize agent memory along three axes - Forms (how memory is implemented), Functions (why memory is needed), and Dynamics (how memory evolves over time). For example, memory forms include token-level (explicit knowledge bases or conversation logs), parametric (knowledge encoded in model weights), and latent (hidden activations or embeddings), while memory functions are delineated into factual (storing world knowledge), experiential (learning from past actions), and working memory (temporary context for the current task). By mapping existing approaches into this taxonomy, the survey highlights gaps and commonalities that were previously obscured by inconsistent terminology.
Why it matters for autonomous AI: Long-term memory is increasingly recognized as the backbone for truly autonomous agents - enabling them to accumulate knowledge, learn from experience, and handle extended dialogues or tasks. Yet, as the survey notes, research on agent memory has been fragmented, with different teams using the term “memory” to mean very different things. This confusion hampers progress. By clearly distinguishing types of memory and their roles, the paper helps ensure that when we say an agent has “long-term memory,” we know exactly what that entails. This clarity is crucial as developers design agents that can remember user preferences, refine strategies over months of operation, or build internal knowledge graphs. The framework also separates the mechanism of memory (e.g. a vector database vs. fine-tuned weights) from its purpose (e.g. recalling facts vs. improving task performance), which encourages developers to mix and match solutions (for instance, using a token-level knowledge base for factual recall and a latent memory for skills) to suit an agent’s needs.
Problem addressed: The rapid expansion of “LLM-based agents” led to a flurry of memory systems - episodic memory buffers, scratchpads, wiki-like tools, etc. - without a common language or evaluation method. Terms like long-term memory and short-term memory were overloaded and insufficient to capture what modern agents actually do. Researchers lacked a clear way to compare, say, one agent that logs entire dialogues to one that updates its weights incrementally. This survey directly tackles that problem by drawing boundaries around what agent memory is and is not. It explicitly differentiates agent memory from related ideas like prompt context length or retrieval-augmented generation, arguing that agent memory typically implies an internal, evolving store of information built from the agent’s own experience (as opposed to, say, a fixed external knowledge base). By surveying dozens of papers and systems, the authors identify common challenges (e.g. forgetting vs. remembering trade-offs, memory indexing, retrieval strategies) and bring some coherence to how we discuss agent memory.
Future implications: With this reference in hand, researchers and engineers can design memory architectures more systematically. The survey’s forward-looking discussion points to key frontiers: automating memory management (so the agent itself decides what to store or discard), integrating memory with reinforcement learning (for agents that learn continually in an environment), extending memory to multimodal data (images, audio), enabling multi-agent memory sharing, and ensuring memory is used safely and transparently. We can expect new agent frameworks that treat memory as a first-class module - e.g. dedicated memory controllers that decide when to query or update memory. In practical terms, this could yield personal AI assistants that remember facts about you for years, or autonomous robots that build up skills over lifelong operation. By rethinking memory “as a first-class primitive in the design of future agentic intelligence”, the community is paving the way for agents that learn more like humans - accumulating wisdom with experience, rather than resetting after each prompt.
