
AI Agents of the Week: Papers You Should Know About
Get ahead of the curve with LLM Watch
Executive Summary
This week in AI agents: Significant advances in long-horizon planning, tool use, multi-agent collaboration, memory and state management, and real-world deployment.
A new open-source framework, AgentForge, promises to simplify and accelerate the construction of LLM-driven agents via a modular skill-based architecture.
In the robotics domain, a comparative study finds that teams of lightweight LLM-based agents can outperform a single large model (GPT-4) in zero-shot task planning for construction robots -highlighting the power of multi-agent collaboration for adaptability.
Pushing the tool-use frontier, LLM-in-Sandbox gives language agents a virtual computer to read/write files, execute code, and interact with external resources, yielding broad performance gains across math, science, and long-context tasks without additional training.
Finally, looking at real-world deployment, researchers propose an LLM agent-based defense against “whaling” phishing attacks, where AI-generated personalized scams target high-profile individuals. The system’s intelligent agents autonomously profile vulnerabilities and suggest tailored countermeasures, demonstrating both the promise and the practical hurdles of using autonomous agents for cybersecurity.
In summary, researchers are addressing the agentic bottlenecks of current AI systems -from designing flexible frameworks and teamwork strategies, to extending memory and tool use, to enforcing stable behavior and deploying agents in complex real-world scenarios. The progress made in this week’s papers lays technical groundwork for more robust, adaptable, and trustworthy AI agents moving forward.
AgentForge -Open-Source Modular Framework Slashes LLM Agent Development Time (paper/code)
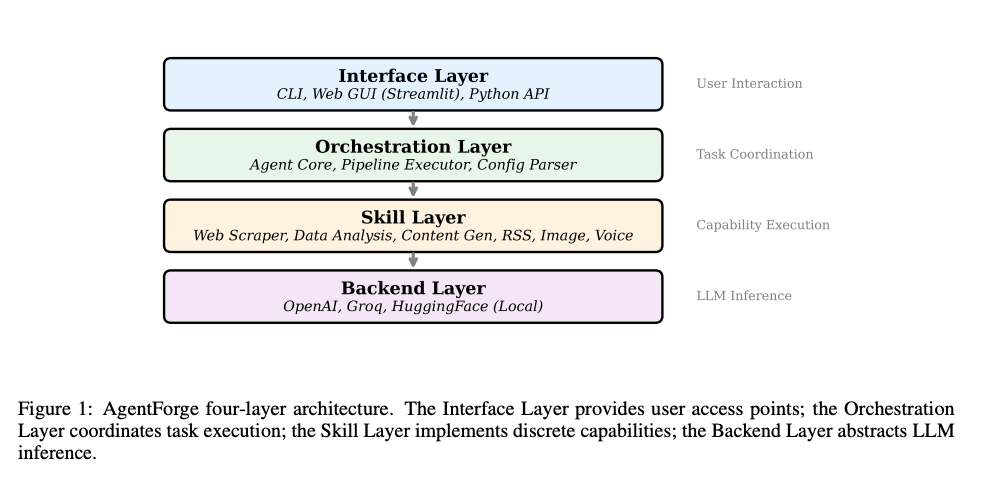
Problem: Building autonomous agents around large language models is often tedious and inflexible. Existing agent frameworks (or manual orchestrations) either lock developers into rigid patterns or require writing monolithic, error-prone code, slowing down experimentation and deployment. There is a need for a lightweight yet extensible toolkit to streamline assembling complex agents without sacrificing flexibility.
Approach & Key Contributions: AgentForge addresses this gap by introducing a principled modular architecture for LLM-driven agents. At its core is a composable skill abstraction: each skill is a self-contained capability (with a defined input-output contract) that can be chained to form sophisticated workflows. Skills are orchestrated as a directed acyclic graph (DAG), allowing both sequential and parallel task decomposition. AgentForge also provides a unified LLM backend interface to swap out language model providers (OpenAI, local HuggingFace, etc.) without changing agent code. A declarative YAML configuration system separates the agent’s logic from implementation details, enabling easier customization and sharing of agent designs. The entire framework is open-source and designed for readability, making it easy for researchers and practitioners to extend with new skills or integrations.
Results: On a suite of benchmark tasks, AgentForge proves both effective and efficient. For example, in web automation and data analysis scenarios, agents built with AgentForge achieved high success rates (87%+ task completion) comparable to state-of-the-art solutions. Crucially, the framework drastically reduced development overhead -cutting agent development time by 62% versus using LangChain and by 78% versus hand-coding with raw APIs. Despite its modularity, AgentForge adds minimal runtime overhead: the orchestrator introduces under 100ms latency, making it suitable for real-time applications. The authors demonstrate built-in skills ranging from web scraping and data analysis to RSS monitoring and even multimodal abilities like image generation and text-to-speech.
Why It Matters: AgentForge provides a much-needed “LEGO kit” for LLM-based agents, empowering developers to rapidly prototype and deploy complex agent behaviors without reinventing the wheel. By formalizing best practices (skill modularity, backend abstraction, config-driven design), it lowers the barrier to entry for custom autonomous agents and encourages reproducibility. The strong performance and huge gains in development speed suggest that future research and industrial applications can iterate faster on agent designs. Overall, AgentForge’s release could accelerate innovation in the agent ecosystem by providing a solid, flexible foundation for building the next generation of autonomous AI agents.
Multi-Agent LLM Team Outperforms GPT-4 in Zero-Shot Construction Planning (paper)
Problem: Robots in construction and other dynamic environments must handle varied, unstructured tasks -but current robot task planners struggle with adaptability. Large foundation models (LLMs and vision models) offer general reasoning abilities, yet it’s unclear how best to deploy them for complex physical tasks. Should one monolithic AI agent handle everything, or can multiple specialized agents collaborating yield better results? This study investigates how to enhance task planning for construction robots using LLM-based agents, comparing a single-agent approach to multi-agent teams in zero-shot settings. The challenge is to improve both adaptability and generalizability of robot plans without costly fine-tuning, using only lightweight open-source models.
Approach: The authors design four agent systems for a simulated construction scenario, all using relatively small LLMs/VLMs (no GPT-4 access during planning). One system is a single agent responsible for the entire planning task. The other three are multi-agent teams where agents adopt different expert roles and collaborate (e.g. a “Painter” agent, “Inspector” agent, etc.). These agents communicate and coordinate to produce a step-by-step action plan for the robot. Importantly, all planning is done in a zero-shot fashion -relying on the foundation models’ built-in knowledge and some prompt engineering, but without additional training data from the construction domain. The evaluation spans three representative construction roles (Painting walls, Safety inspection, Floor tiling), testing how well each agent/team can generate feasible task plans that adapt to new situations.
Results: The multi-agent strategy proved remarkably effective. A team of four specialized LLM agents working together outperformed a state-of-the-art GPT-4-based planner on most metrics, while also being an order of magnitude more cost-efficient. In particular, the four-agent team’s plans were more complete and correct for the given tasks than those produced by a single GPT-4 model, despite the latter’s superior size and training. Smaller teams of three agents also showed stronger generalization than a single agent, though the four-agent configuration was best. These findings indicate that collaboration between focused LLM agents can compensate for (or even exceed) raw model power in complex planning tasks. The paper includes an analysis of how different agent behaviors influence the final plan, providing insight into why the team-based approach excels. For example, dividing cognitive labor reduced errors and brought diverse perspectives (vision, safety, execution) to the plan, yielding more robust solutions.
Why It Matters: This work suggests a paradigm shift for applying AI in robotics and other domains -more brains may beat a bigger brain. By orchestrating multiple lightweight agents, we can achieve emergent performance gains that a single large model can’t match, at lower cost. It highlights the importance of agent specialization and cooperation: the multi-agent setups handled ambiguity and unexpected situations better, pointing to improved adaptability. For the future of autonomous agents, this implies that carefully designed agent teams (even using open models) could tackle real-world tasks more effectively than relying on one super-LLM. Moreover, the cost-effectiveness (10× cheaper than GPT-4 while outperforming it) is promising for practical deployment. As AI agents move into messy, physical environments, this study provides evidence that swarm intelligence via LLM collaboration is a viable path to long-horizon autonomy and resiliency in the field.
LLM-in-Sandbox -Virtual Computer Access Unlocks Broad Agent Capabilities (paper)
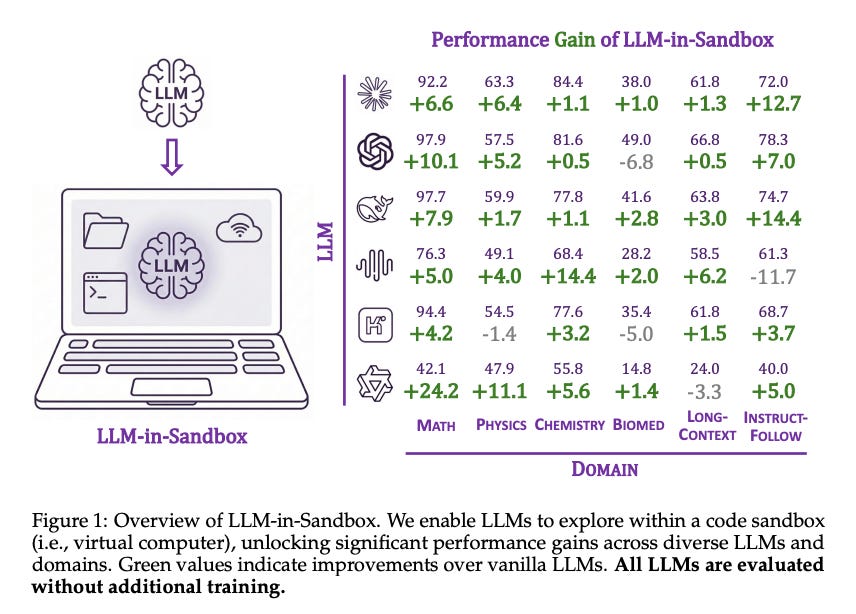
Problem: Even the most advanced LLM-based agents are limited by their fixed context windows and lack of persistent tool use -they can’t truly “scratchpad” knowledge or execute code unless explicitly designed to do so. Many agent failures on complex tasks stem from these limitations: context overflow, inability to use external resources effectively, and difficulty handling specialized computations or formats. The question is whether giving an LLM agent a more general computing environment to work within could elicit more general problem-solving intelligence. Can an AI agent taught to use a computer (file system, internet, Python interpreter, etc.) tackle non-textual problems and longer contexts that stump a normal chatGPT-style agent?
Approach: Enter LLM-in-Sandbox, a framework that places an LLM agent inside a virtual machine sandbox with a full suite of tools. The agent can issue commands to browse files, run scripts, call external APIs, etc., as if it were a human programmer operating a computer. Notably, the authors first show that strong LLMs can figure out how to use the sandbox tools without any additional training. Simply by prompting, models like GPT-3.5 or Claude instinctively perform actions like searching for information online, writing to disk to manage long texts, or executing code to do math or reformat output. Building on this, the paper introduces LLM-in-Sandbox-RL, a reinforcement learning approach that fine-tunes the model within the sandbox to use these tools even more effectively. Uniquely, this RL training doesn’t require handcrafted agent-specific data -they use general text tasks but allow the model to practice utilizing the sandbox, thereby marrying broad knowledge with tool-use skills.
Results: Simply enabling sandbox access leads to significant performance gains across diverse domains. Without any finetuning, several strong LLMs showed improved results on tasks in mathematics, physics, chemistry, biomedicine, and long-context understanding when they could offload work to the sandbox. For instance, the paper reports that enabling file system usage boosted accuracy on a long-document question answering task, as the model could store and retrieve relevant information on the fly (where a normal LLM would forget or get confused). The authors quantify improvements (often in the range of +5 to +15 percentage points on task performance) and visualize how all evaluated LLMs benefit to some degree by having this extended capability. After RL-based fine-tuning (LLM-in-Sandbox-RL), the models became even more proficient at tool use, generalizing robustly to new tasks -essentially learning when and how to use the virtual computer to solve problems beyond their standalone ability. The paper also addresses efficiency considerations, finding that the sandbox approach is computationally feasible, and it open-sources the entire sandbox framework as a Python package for the community.
Why It Matters: LLM-in-Sandbox demonstrates a viable path to embed an AI agent in an environment with persistent memory and tool APIs, resulting in more agentic behavior without needing specialized training for each tool. This approach touches on many facets of autonomy: long-horizon memory (via files), tool use (via code execution and web access), and self-improvement (via RL fine-tuning). For the future of autonomous agents, this suggests that giving AI the equivalent of a computer’s OS can dramatically enhance their problem-solving scope -an encouraging result as we push towards agents that can perform complex, multi-step real-world tasks. Moreover, by open-sourcing the sandbox, the authors invite further exploration of safe and effective agent tool use. As researchers adopt LLM-in-Sandbox, we may see rapid progress in agents that can write and debug their own code, manage large knowledge bases, or interface with arbitrary software -all key for truly general-purpose autonomy.
LLM Agents to the Rescue: Personalized Defenses Against AI-Powered Whaling Attacks (paper)
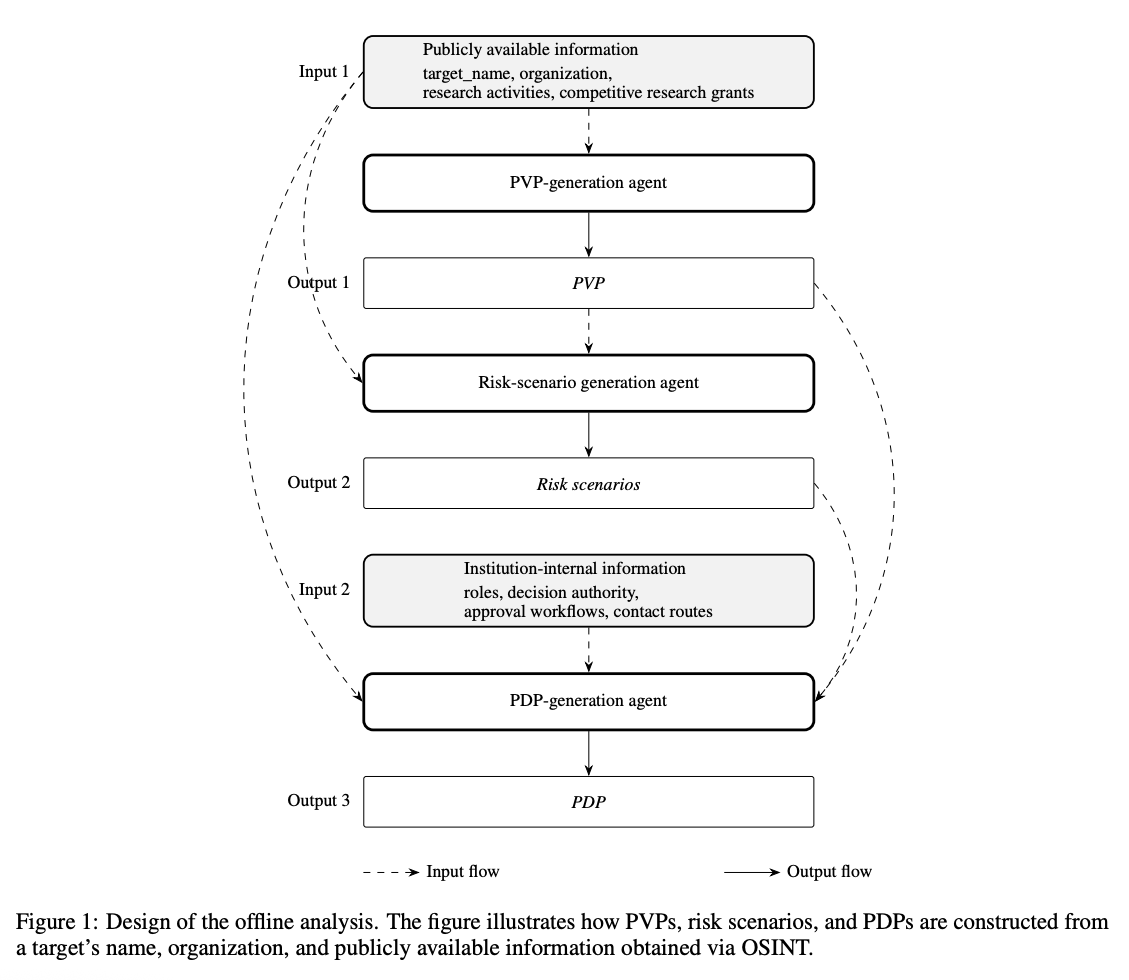
Problem: “Whaling” attacks are highly targeted phishing campaigns that single out important individuals (executives, researchers, etc.) with personalized fraudulent emails. With the rise of generative AI, attackers can now automatically scrape public data and craft very convincing, tailored scam emails -making whaling an even more serious threat. For example, a dean or CEO might receive a deep-faked email referencing their actual projects or colleagues, tricking them into a harmful action. Traditional security filters and training often fail to catch such bespoke social engineering. The challenge addressed here is how to use AI agents for defense: can autonomous agents analyze a high-value individual’s digital footprint, anticipate likely phishing ploys, and help vet incoming communications? In essence, the researchers ask if an LLM-based agent system can serve as a personalized cybersecurity assistant, shielding users from sophisticated, AI-enhanced whaling attacks.
Approach: The proposed framework employs multiple cooperating LLM agents to simulate both attacker and defender perspectives in order to harden a target’s security. First, an agent acting as a “profile builder” scours publicly available information about the target (e.g. their university webpage, publications, social media) to compile a detailed vulnerability profile -essentially, what an attacker is likely to learn about this person. This could include the target’s research interests, recent grants, names of colleagues, etc. Using this profile, a second agent generates potential attack scenarios: plausible whaling email themes or approaches that an attacker might attempt (for instance, a fake email from a funding agency referencing the target’s grant). For each identified attack scenario, the system then creates a defense profile -guidelines and checks tailored to that scenario (e.g. “If an email claims to be about grant XYZ, verify the sender’s domain and language matches official communications”). Finally, when a real email comes in, an analysis agent uses these defense profiles to assess the email’s content and flag any whaling-related red flags. The LLM agents thus work in concert: one preemptively thinks like an attacker to expose weak points, and another uses that insight to scrutinize communications from a defender’s standpoint. The framework was tested in a Japanese university setting with faculty members as the protected targets.
Results: In a preliminary evaluation, the agent-based system was able to produce meaningful security judgments with explanations that aligned well with human experts’ reasoning. For instance, given a sample whaling email, the defense agent would flag that “this email mentions project ABC and requests a money transfer -however, project ABC’s sponsor would never use a Gmail address,” thereby catching the scam with an explanation mirroring a security expert’s thought process. The personalized defense profiles improved the relevance of these judgments, as the agent knew what to expect (or not expect) in the context of that specific faculty member’s work. The study reports that the system’s responses were consistent with the actual work context of the targeted individuals -an important validation that it’s not generating generic advice, but rather tailored analysis. Equally important, the authors catalogued practical challenges that arose. For example, keeping the profiles up-to-date as a person’s public information changes is non-trivial, and there’s a risk of the agents themselves being fooled by attacker prompt manipulation. They also note the need for systematic evaluation: how do we formally verify that the AI defense catches new attacks before they cause harm?
Why It Matters: This work is an early glimpse at how autonomous agents could be deployed in the cybersecurity arena for active, personalized defense. Instead of a one-size-fits-all spam filter, we have AI agents that deeply understand an individual user’s context and can reason about attacks the way a human security analyst would -but continuously and at scale. As generative AI is empowering attackers (through automated phishing kits, social media scraping bots, etc.), it’s crucial that defenders also amplify their capabilities with AI. An exciting aspect of this framework is the attacker simulation: by having an agent “think like a hacker,” we can proactively patch holes before an attack happens. This could generalize to other domains (e.g. an agent that tries to break into a system to find vulnerabilities, paired with another that fixes them). The whaling defense study also underscores the limitations and responsibility that come with autonomous agents in high-stakes domains. The fact that it highlights challenges for future deployment is important -it reminds us that an AI defender must be thoroughly evaluated (we wouldn’t want false positives blocking real emails, or false negatives letting scams through). It also raises interesting questions of trust and oversight: users might need a “human in the loop” for the final call, at least initially. Nonetheless, this research is a promising step toward AI-augmented security agents. It shows that with the right design, LLMs can move beyond passive analysis and take on an agentive role: gathering intelligence, hypothesizing attacker strategies, and vigilantly guarding a person’s digital interactions. As autonomous agents become more common, using them to fight AI with AI in cybersecurity will likely be an area of intense development, and this paper provides a foundational approach for doing so.